Hadoop集群搭建与MapReduce开发实战指南
版权申诉
"本资源详细介绍了如何亲手搭建Hadoop集群,并进行MapReduce程序的开发,适合初学者,步骤清晰,附带完整代码和解释。"
在本文档中,作者提供了搭建Hadoop集群及MapReduce程序开发的详细步骤,分为三个主要任务:
任务1:Hadoop集群部署关键点个性化
1. 安装Ubuntu Kylin 16.04.4操作系统,设置计算机名和用户账户,便于管理和操作。
2. 更新系统包管理器apt,确保所有软件包是最新的,这有助于避免因软件版本过旧而产生的兼容性问题。
3. 安装SSH服务,配置SSH无密码登陆,简化集群间节点的交互,提高效率。
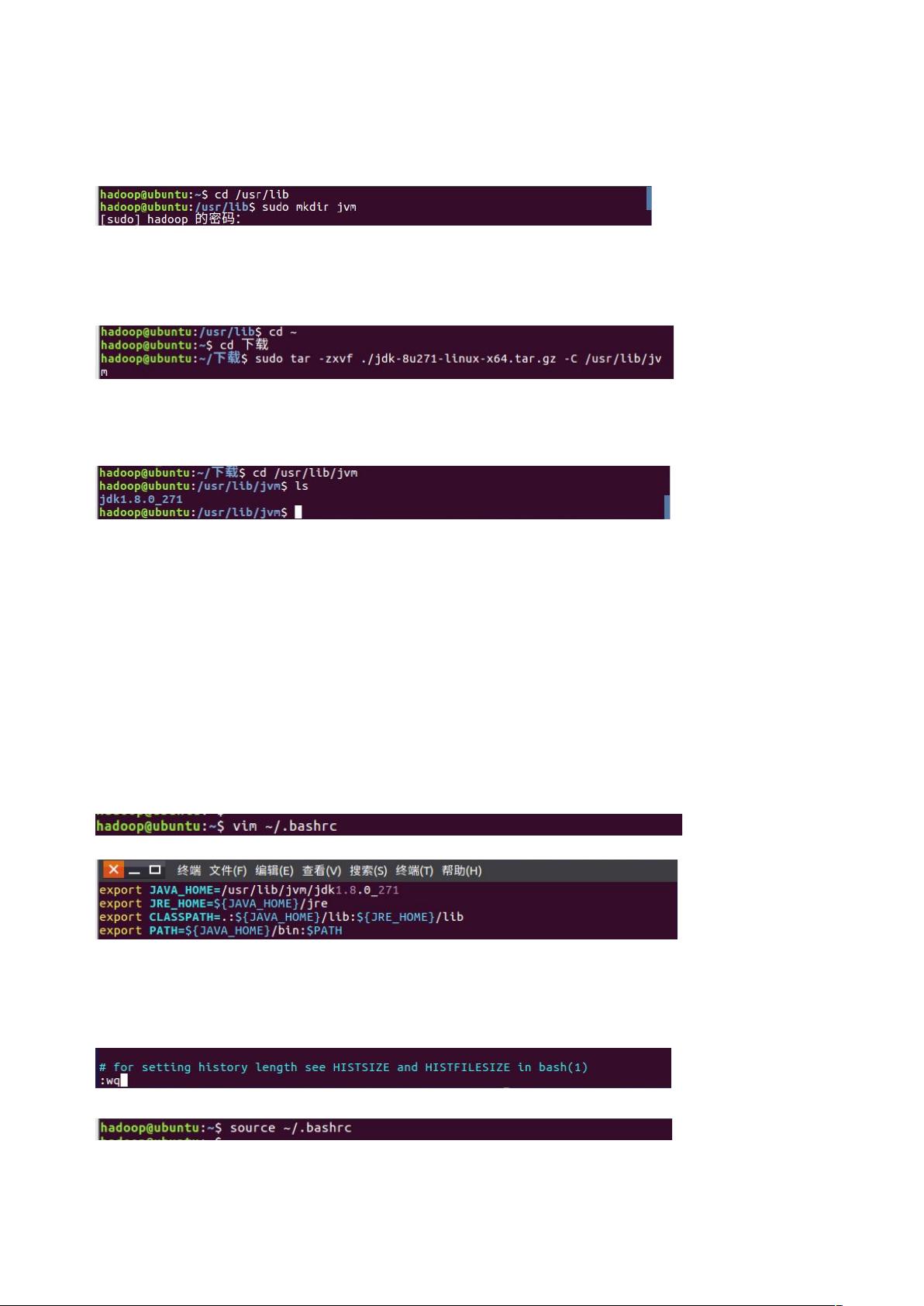
4. 安装Java环境,因为Hadoop依赖Java运行,所以这是必不可少的步骤。
5. 安装Hadoop,选择适合的版本,根据需求配置相关参数。
6. 配置Hadoop集群的网络设置,包括主机名解析和端口开放,确保节点间通信畅通。
7. 设置SSH无密码登陆到所有节点,实现集群自动化操作。
8. 配置Hadoop的分布式环境,如HDFS和YARN的配置文件,确保集群可以正常启动和运行。
9. 在集群上执行分布式实例,验证Hadoop部署是否成功。
任务2:MapReduce程序开发关键点个性化
1. 安装Eclipse作为开发环境,支持Java开发。
2. 安装Hadoop-Eclipse-Plugin插件,它使得Eclipse可以直接与Hadoop集群交互,方便MapReduce程序的编写和调试。
3. 配置插件,关联Hadoop集群的位置,使Eclipse能够识别和访问集群。
4. 使用Eclipse操作HDFS文件,例如上传、下载和查看文件,这对开发和测试MapReduce程序至关重要。
5. 在Eclipse中创建MapReduce项目,编写Mapper和Reducer类,实现业务逻辑。
6. 通过Eclipse运行MapReduce作业,观察程序执行情况,便于快速定位和解决问题。
任务3:开发总结
1. 提到了在启动Hadoop集群时可能出现的一些常见问题及其解决方案,如Java.NET.NoRouteToHostException、Too many fetch failures、Java heap space错误等。
2. 对于Hadoop集群运行时遇到的问题,如DataNode未启动或内存不足等问题,也给出了相应的处理建议。
3. 最后,作者提醒读者,对于HDFS和HBase的详细操作,可以参考其他相关资源。
这篇文档对于初次接触Hadoop和MapReduce的人来说是一份宝贵的指南,通过跟随步骤,即使是新手也能成功搭建集群并编写MapReduce程序。此外,作者还分享了开发过程中可能遇到的问题和解决方法,帮助读者更好地理解和应对实际操作中的挑战。
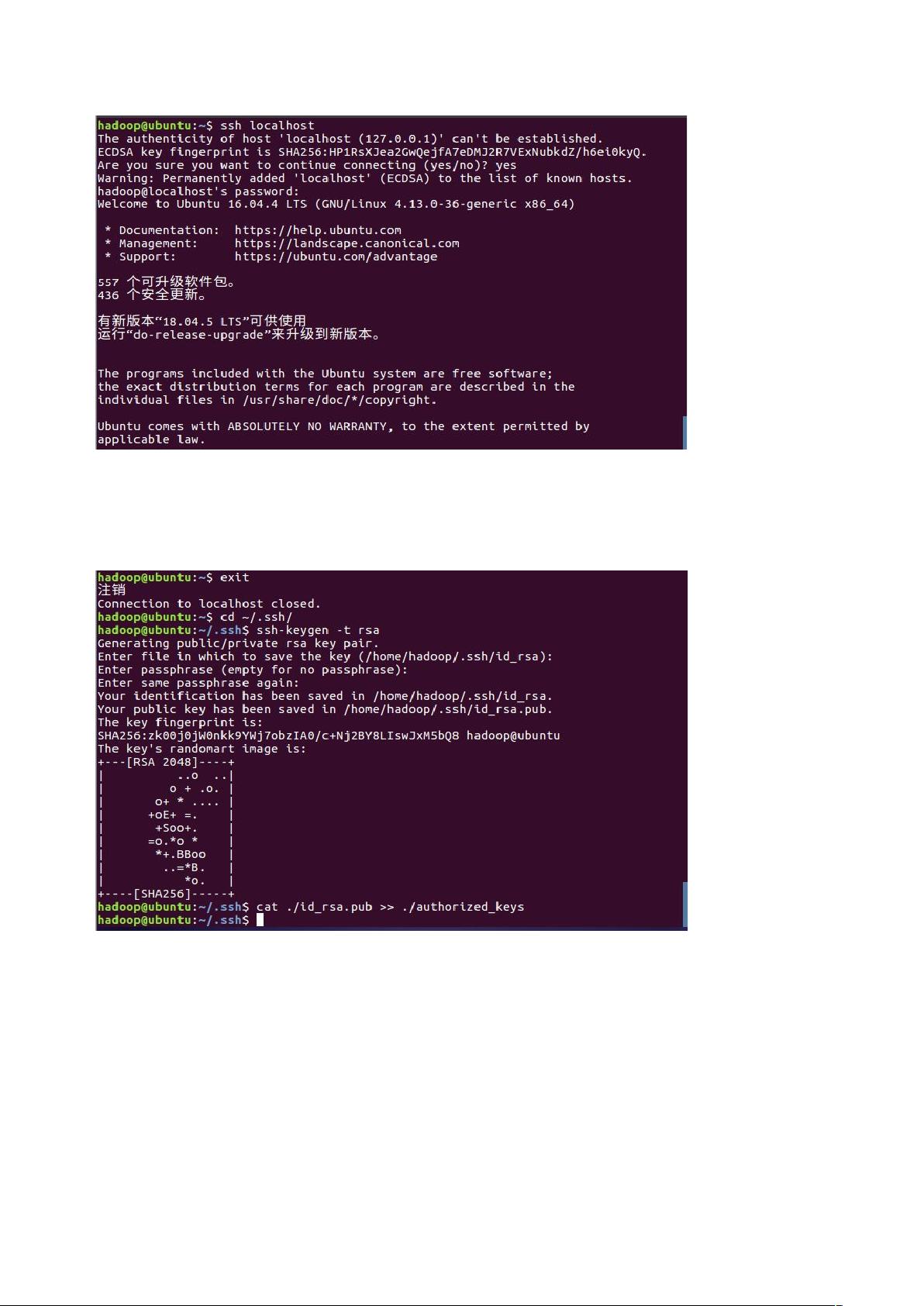
3.配置成 SSH 无密码登陆很方便,所以,输入 exit 命令退出刚才登陆的 ssh localhost,然后输入 cd
~/.ssh/命令进入.ssh 目录,输入 ssh-keygen -t rsa 命令利用 ssh-keygen 生成密匙,然后输入 cat ./id_rsa.pub
>> ./authorized_keys 命令将密匙加入到授权。
4.加入授权后,此时再输入 ssh localhost 命令登陆就不需要密码了
8
剩余51页未读,继续阅读
3218 浏览量
273 浏览量
1453 浏览量
2021-10-07 上传
2024-05-23 上传
177 浏览量
2021-10-10 上传

诗卿°
- 粉丝: 367
 我的内容管理
展开
我的内容管理
展开







最新资源
- React.js实现的简单HTML5文件拖放上传组件
- iReport:强大的开源可视化报表设计器
- 提升代码整洁性:Eclipse虚线对齐插件指南
- 迷你时间秀:个性化系统时间显示与管理工具
- 使用ruby-install一次性安装多种Ruby版本
- Logality:灵活自定义的JSON日志记录器
- Mogre3D游戏开发实践教程免费分享
- PHP+MySQL实现的简单权限账号管理小程序
- 微信支付统一下单签名错误排查与解决指南
- 虚幻引擎4实现的多边形地图生成器
- TouchJoy:专为触摸屏Windows设备打造的屏幕游戏手柄
- 全方位嵌入式开发工具包:ARM平台必备资源
- Java开发必备:30个实用工具类全解析
- IBM475课程资料深度解析
- Java聊天室程序:全技术栈源码支持与学习指南
- 探索虚拟房屋世界:house-tour-VR应用体验
