CentOS7下大数据技术栈安装教程:Hadoop、MySQL、Spark与Hive详析
需积分: 15 3 浏览量
更新于2024-07-15
收藏 8.86MB PDF 举报
"这份文档是关于大数据技术的详细安装教程,涵盖了Hadoop、Samba、Spark、MySQL、Hive和Scala在CentOS7操作系统下的安装和配置过程。"
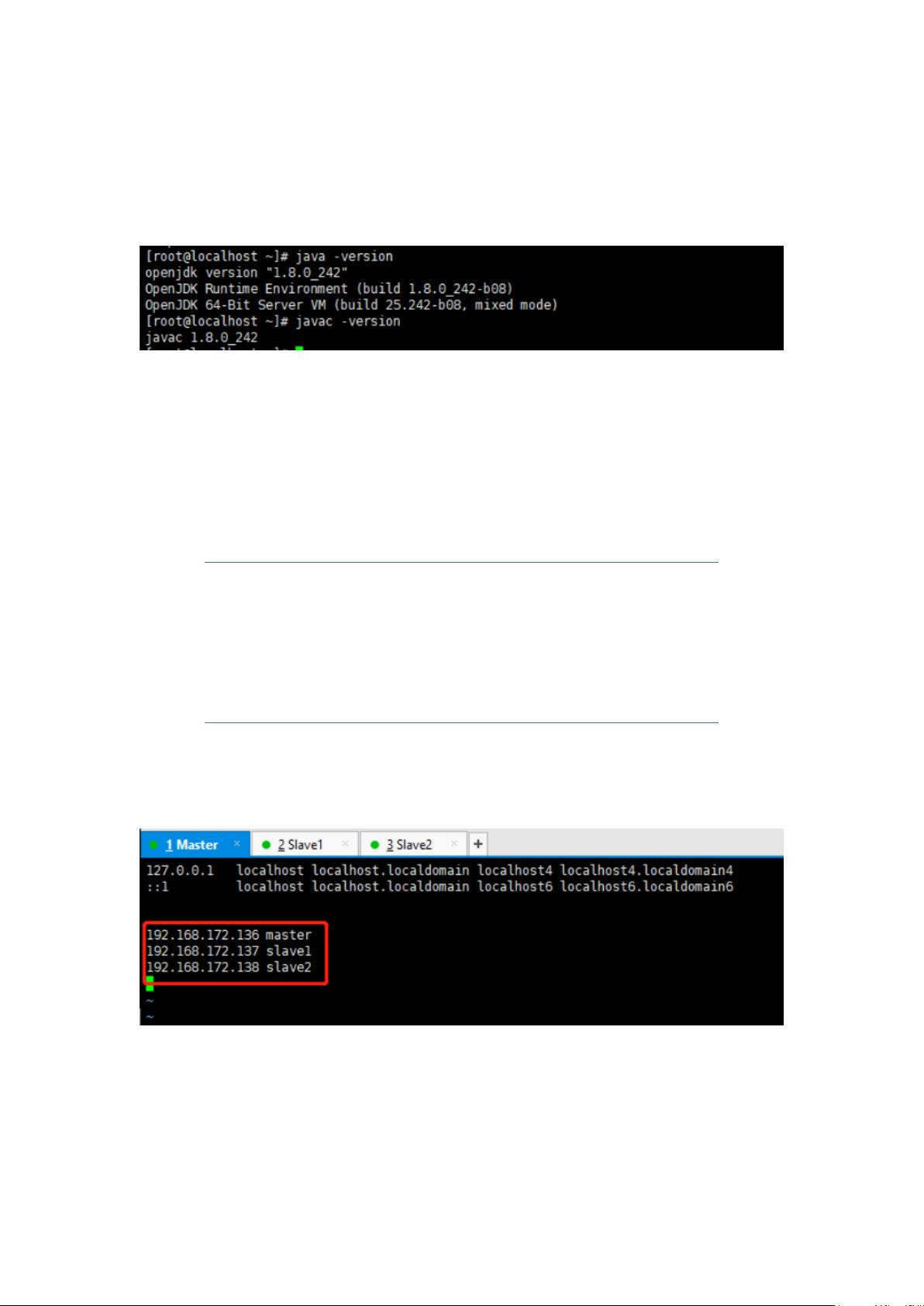
本文档首先介绍了准备工作,强调了建立一个包含一台Master节点和两台Slave节点的Hadoop集群,并使用Xshell工具来远程连接和管理这些虚拟机。在Linux环境中配置静态IP地址是关键,确保各节点间的通信。
接下来,文档详细阐述了Hadoop的安装步骤,包括切换到Master节点,安装和配置JDK,设置HOST配置,以及安装和配置Hadoop本身。这些步骤确保了Hadoop环境的正常运行。
然后,文档转向了MySQL数据库的安装,包括检查系统是否已有MySQL,安装MySQL,设置权限,初始化数据库,启动服务,检查运行状态,登录,修改密码并验证修改是否成功。这些步骤旨在提供一个安全且功能完备的数据库服务。
在Hive的安装部分,文档详细描述了下载、安装和配置Hive的过程,以及启动Hive并解决与${HIVE_HOME}相关的路径问题。这部分帮助用户建立Hive与Hadoop的集成,以便进行大数据处理。
接着,文档进入Spark的安装,先讲解了Scala的安装,包括解压、重命名、配置环境变量和验证安装。然后,介绍了Spark的下载、解压、配置环境变量、配置conf文件、创建slaves文件以及启动Spark。这些步骤确保Spark能够在Hadoop集群上运行。
最后,文档提到了升级Python的流程,包括下载、解压、安装依赖包、编译、安装、备份Python2、创建新的Python软连接以及更新和设置pip软链接。这部分对于使用Python进行大数据分析的用户尤其重要。
这个文档为在CentOS7环境下构建一个完整的大数据处理环境提供了详尽的指导,包括从基础设施准备到各个组件的安装和配置,是学习和实践大数据技术的宝贵资源。
10 / 63
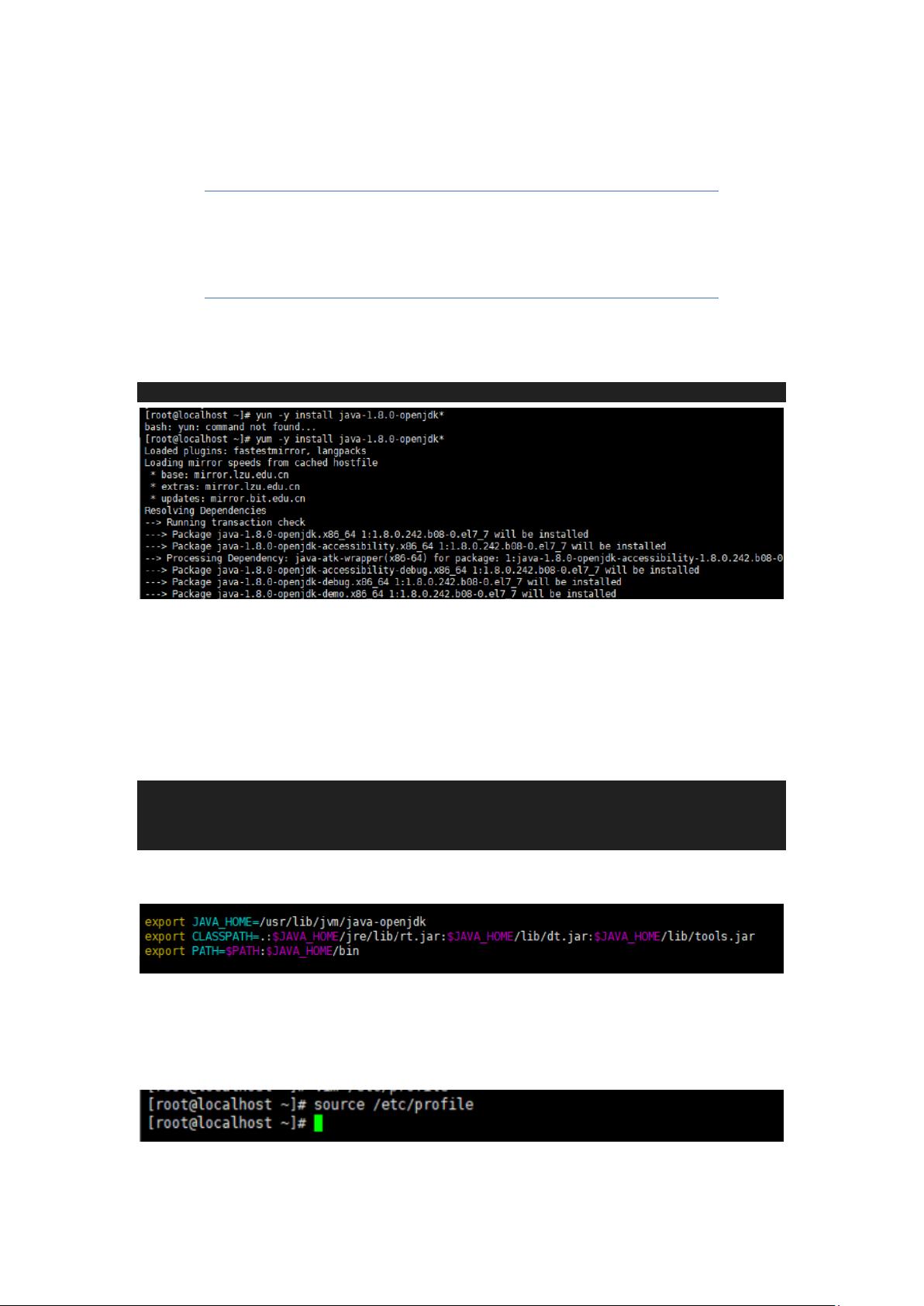
2.2.1.5 安装所需的 JDK 版本
这里有个地方要注意,上图中我用红框圈起来的两个 java 版
本,要选择-devel 的安装,因为这个安装的是 jdk,而那个不
带-devel 的安装完了其实是 jre。
这里我选择的是:java-1.8.0-openjdk-devel.x86_64 : OpenJDK Development
Environment
yum -y install java-1.8.0-openjdk*
2.2.1.6 配置全局环境
vim /etc/profile
在最后面添加:
export JAVA_HOME=/usr/lib/jvm/java-openjdk
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
如下图:
保存!!!
全局变量立即生效:
source /etc/profile
剩余63页未读,继续阅读
2021-10-20 上传
点击了解资源详情
2022-10-27 上传
119 浏览量
2021-07-13 上传
2023-04-18 上传
103 浏览量
2021-10-10 上传

ZeroIce
- 粉丝: 434
 我的内容管理
展开
我的内容管理
展开







最新资源
- 华为毫米波雷达挑战:Matlab实现DOA算法
- 解决ASP.NET GridView滚动标题问题的源码分析
- Visual Log开源CMS:功能强大、支持多插件与多语言
- 世界名画陈列馆源代码分析与问题解决
- Android自定义AlertDialog实现加载提示
- 如何在右上角添加自定义图标并优化源码工具
- 中文版HTML+DHTML+DOM开发指南CHM文档集
- Android图片颜色变换处理ColorMatrix演示
- LL(1)文法的递归下降语法分析程序实现
- Oracle数据库实战优化与开发经验分享
- MATLAB北航程序精通指南与实例解析
- 浅谈简单排序算法与其实现工具
- 轻松制作个性化MP3铃声的剪切工具
- 中国上市公司MBO绩效实证分析研究
- Android平台短信与通话记录信息的获取教程
- 掌握Cisco路由管理:实用CookBook实例解析
