数据爬取深度解析:社交媒体内容抓取策略与限制
需积分: 0 100 浏览量
更新于2024-08-04
收藏 1.39MB DOCX 举报
本次数据爬取调研主要针对的是社交媒体平台上的公开信息抓取,包括新浪微博、豆瓣、贴吧、知乎、CSDN、科学网、领英、小木虫、人人和QQ空间等。这些平台在提供用户信息时,存在不同程度的隐私保护和访问限制。
首先,我们关注的内容点包括用户的唯一标识码(如微博的ID号、知乎的唯一ID字符串)、基本信息(昵称、性别年龄/生日、地点、教育/工作背景、头像和个人简介),社交网络(关注列表、被关注列表、发布的内容),以及特定功能的互动(如豆瓣的广播、微博的热门微博、知乎的问题和答案)。值得注意的是,部分平台如人人网、QQ空间和百度贴吧,需要用户添加好友后才能访问个人信息,且百度动态通常不完全公开,导致爬取内容有限。而博客类网站如CSDN虽然可以获取发布内容,但标签信息可能较少。
豆瓣和微博提供了丰富的用户关系链,可以从关注列表和好友的列表中获取更多用户ID,便于进一步挖掘社交网络。豆瓣还包含用户对书籍、电影和音乐的喜好记录,形成独特的兴趣标签。微博则是此次调研的重点,因为其界面直观,提供了主页、个人信息、粉丝列表和微博内容的直接链接,方便数据抓取。
为了实现这些爬取,主要采用的技术手段包括使用cookies或表单模拟登录,通过requests库获取网页HTML文件,然后利用正则表达式(re)、BeautifulSoup或类似工具解析HTML结构,提取所需信息。在策略上,以微博为例,首先从关注者列表开始,逐步扩展到个人主页和粉丝页,以此构建用户的社交网络图。
此外,调研还提到可以融合知乎、微博和豆瓣的内容,虽然这些跨平台的链接反映了用户在不同社区的活跃度,但并不能直接表明用户身份的一致性,因为它们可能代表不同的个体或兴趣点。
这项数据爬取调研旨在研究如何有效地从各种社交媒体平台上获取有价值的信息,但同时尊重用户的隐私和平台的规则,确保在合法范围内进行数据采集和分析。
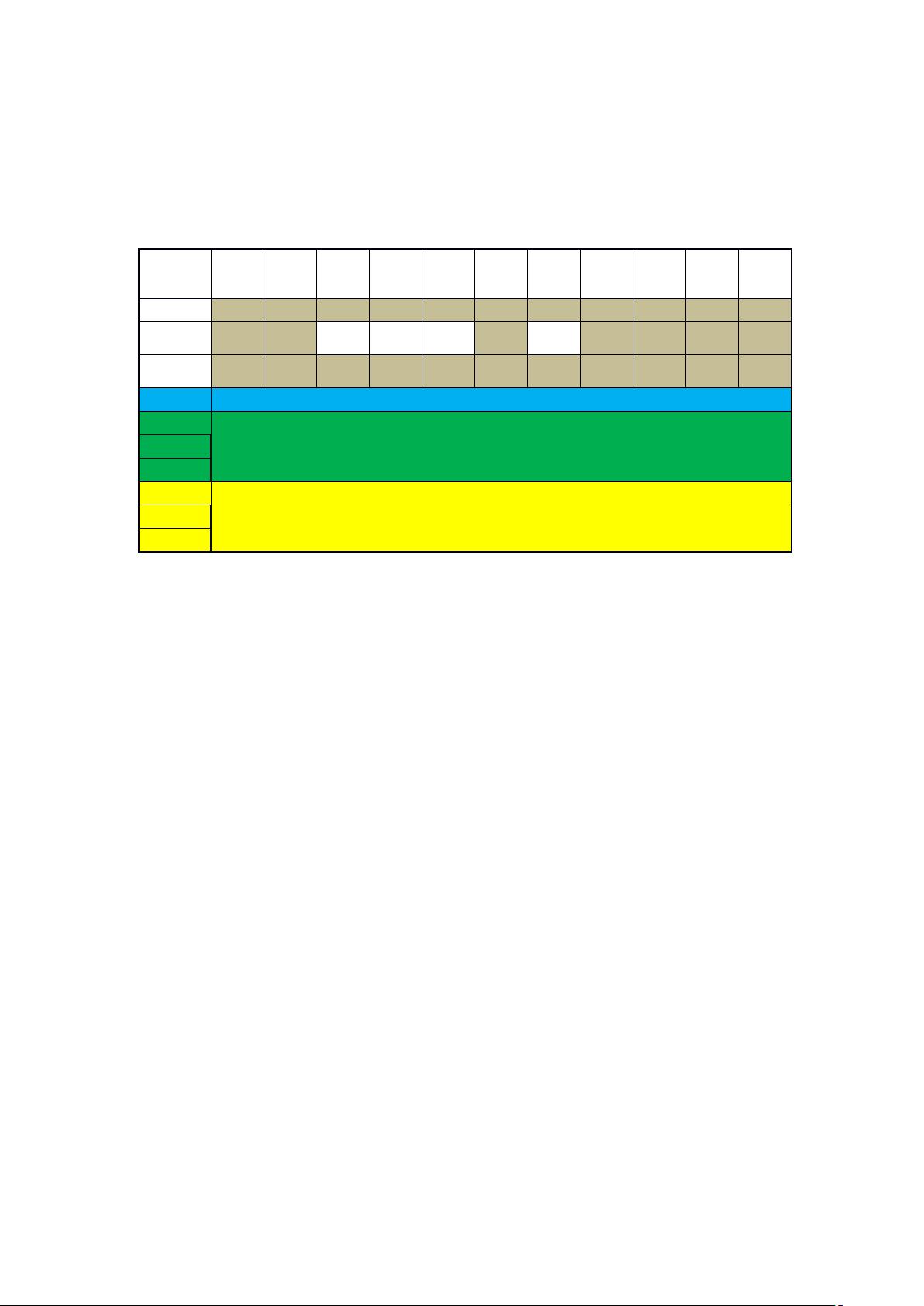
一、爬取内容选择:
预爬取网站:
新浪微博、豆瓣、贴吧、知乎、CSDN、科学网、领英、小木虫、人人、QQ 空间
【1】唯一标识码【2】昵称【3】性别年龄/生日【4】地点【5】教育/工作【6】头像【7】
简介【8】关注列表【9】被关注列表【10】发布内容【11】标签【12】其他
唯一
标识
昵称
性别
年龄
生日
教育
工作
头像
简介
关注
列表
粉丝
列表
发布
内容
标签
新浪微博
ID 号
豆瓣
字符
串
知乎
字符
串
贴吧
访问需要登陆账号,只能查看非隐藏动态,而大部分人都选择隐藏。
领英
人人
QQ 空间
访问需要权限,必须加好友之后才能访问网页内容,不能大规模爬取。
科学网
小木虫
CSDN
访问需要登陆账号,发布内容多数都是长篇博客,标签化的信息不多。
1. 人人网,QQ 空间,领英
访问需要权限,必须加好友之后才能访问网页内容,不能大规模爬取。
2. 百度用户(贴吧)
访问需要登陆账号,只能查看非隐藏动态,而大部分人都选择隐藏,可爬取内容不多。
3. 博客类(如 CSDN)
访问需要登陆账号,【10】发布内容多数都是长篇博客,标签化的信息不多。
4. 豆瓣
【1】ID 号或者字符串
【2】【6】
【8】【9】能从这两个列表获得所有好友的 ID 号
【10】广播,一个豆瓣活动的日志,也有一些类似微博的短消息
【11】豆瓣小组,类似标签
【12】有大量的“喜欢”内容,如书、电影、音乐
5. 微博
【1】ID 号
【2】【3】【4】【5】【6】【7】
【8】【9】能从这两个列表获得所有好友的 ID 号
【10】微博,可判别哪些是热门微博
【11】从微博给出的选择
6. 知乎
【1】知乎指定唯一 ID 字符串
【2】【3】【4】【5】【6】【7】
【8】【9】能从这两个列表获得所有好友的 ID 号
【10】提问、回答,可以提取回答的内容
【11】关注了话题作为标签,以及设置自己擅长
【12】有部分人已经和微博进行关联,可作为测试集
下载后可阅读完整内容,剩余8页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2017-12-11 上传
2022-09-19 上传
2022-09-20 上传
2017-12-10 上传
2010-12-23 上传

FloritaScarlett
- 粉丝: 28
- 资源: 308
 我的内容管理
展开
我的内容管理
展开







最新资源
- Niushop Saas 多开运营版 v4.zip
- osdep_service.rar_V2
- (FZY351)91单机网单机游戏触屏版自适应手机wap游戏网站模板.zip
- Java毕业设计-基于springboot+vue校运会管理系统-付源代码+论文+mysql(大作业).zip
- Fb_friend_listing:简单的 ruby 应用程序,列出所有朋友的显示图片和指向他们个人资料的链接。 需要 fb 访问代码
- PickView:超级牛B的日历控件,基于RecycleView打造
- 【批量下载】readme等.zip
- pdfbox-2.0.17.jar.zip
- 中国大学MOOC-浙江大学-翁恺老师网课-C语言程序设计,我从零开始自学编程的记录。.zip
- esp32-fota-canairio-loader:尝试从一个简单的Arduino文件启动远程OTA更新的概念证明
- dlg.zip_zip
- lizportfolio:Liz的图片组合
- Mp3play VST:VST乐器播放mp3文件-开源
- Java毕业设计-基于springboot+vue乡村养老服务管理系统-付源代码+论文+mysql(大作业).zip
- asp_login_excel.rar_WEB开发_Delphi_
- leetcode
