Flink初学者实验:WordCount与实时词频统计
版权申诉
"本次实验是关于Flink初级编程实践,包括使用IntelliJ IDEA开发WordCount程序和实现数据流词频统计。实验者在Linux环境下安装了IntelliJ IDEA、Flink以及Maven,通过编写Java代码,使用Maven打包成JAR文件,并在Flink上运行。此外,还利用NC程序模拟数据流,对实时单词进行处理和词频计算。"
实验详细步骤及知识点:
1. **Flink环境搭建**:
- 安装Flink:Flink是一个分布式流处理框架,用于处理无界和有界数据流。实验中,首先需要在Linux环境中安装Flink,这通常涉及到下载最新稳定版本的Flink,解压并配置环境变量。
2. **开发环境准备**:
- 安装IntelliJ IDEA:作为Java开发的集成开发环境,IntelliJ IDEA提供了便捷的代码编辑、调试和打包功能,是开发Flink应用程序的常用工具。
3. **构建WordCount程序**:
- 使用Java编写WordCount:WordCount是大数据处理中的经典例子,用于统计文本中各个单词出现的次数。在Flink中,可以使用DataStream API来实现。核心代码包括定义Source(数据源)、Transformation(转换)和Sink(数据接收器)。
4. **Maven项目管理**:
- Maven是Java项目的构建工具,它管理依赖关系,帮助构建和打包项目。在实验中,使用Maven将WordCount项目打包成可执行的JAR文件,命令通常是`mvn clean package`。
5. **运行Flink程序**:
- 提交JAR包到Flink集群:打包完成后,通过Flink的命令行工具提交JAR包到集群,例如`bin/flink run path/to/your/jar.jar`,这样Flink就会启动一个作业并执行Java代码。
6. **数据流模拟**:
- 使用NC(NetCat)模拟数据流:NC是网络工具,可用于创建数据流。在实验中,它被用来模拟不断生成单词的源,这些单词被Flink程序实时处理。
7. **实时词频统计**:
- 实时处理与计算:Flink的DataStream API支持实时处理,实验中编写了Java代码来接收NC发送的数据,对单词进行分组和计数,实现词频统计。
8. **监控与结果查看**:
- 在Flink的Web UI或控制台查看结果:运行JAR包后,可以在Flink的Web界面或者命令行输出中观察到词频统计的结果。
9. **虚拟机配置**:
- 实验环境使用了Windows上的Oracle VM VirtualBox,配置了一个Ubuntu虚拟机,内存2GB,4个处理器核心,64MB显存。这种配置足以支持基本的大数据开发和测试。
通过这个实验,学生可以掌握Flink的基本操作,理解流处理的概念,以及如何在实际环境中部署和运行Flink程序。同时,也了解了使用IntelliJ IDEA和Maven进行Java项目开发的流程。
“大数据技术原理与应用”课程实验报告
题目:实验 8 Flink 初级编程实践 姓名:朱小凡 日期:2022.5.16
实 验 环 境 : 本 机 : Windows 10 专 业 版 Intel(R) Core(TM) i7-4790 CPU @
3.60GHz 8.00 GB RAM 64 位操作系统, 基于 x64 的处理器 Oracle VM VirtualBox
虚拟机:Linux Ubuntu 64-bit RAM 2048MB 处理器数量 4 显存大小 64MB
实验内容与完成情况:
1. 使用 IntelliJ IDEA 工具开发 WordCount 程序
在 Linux 操作系统中安装 IntelliJ IDEA,然后使用 IntelliJ IDEA 工具开发
WordCount 程序,并打包成 JAR 包,提交到 Flink 中运行。
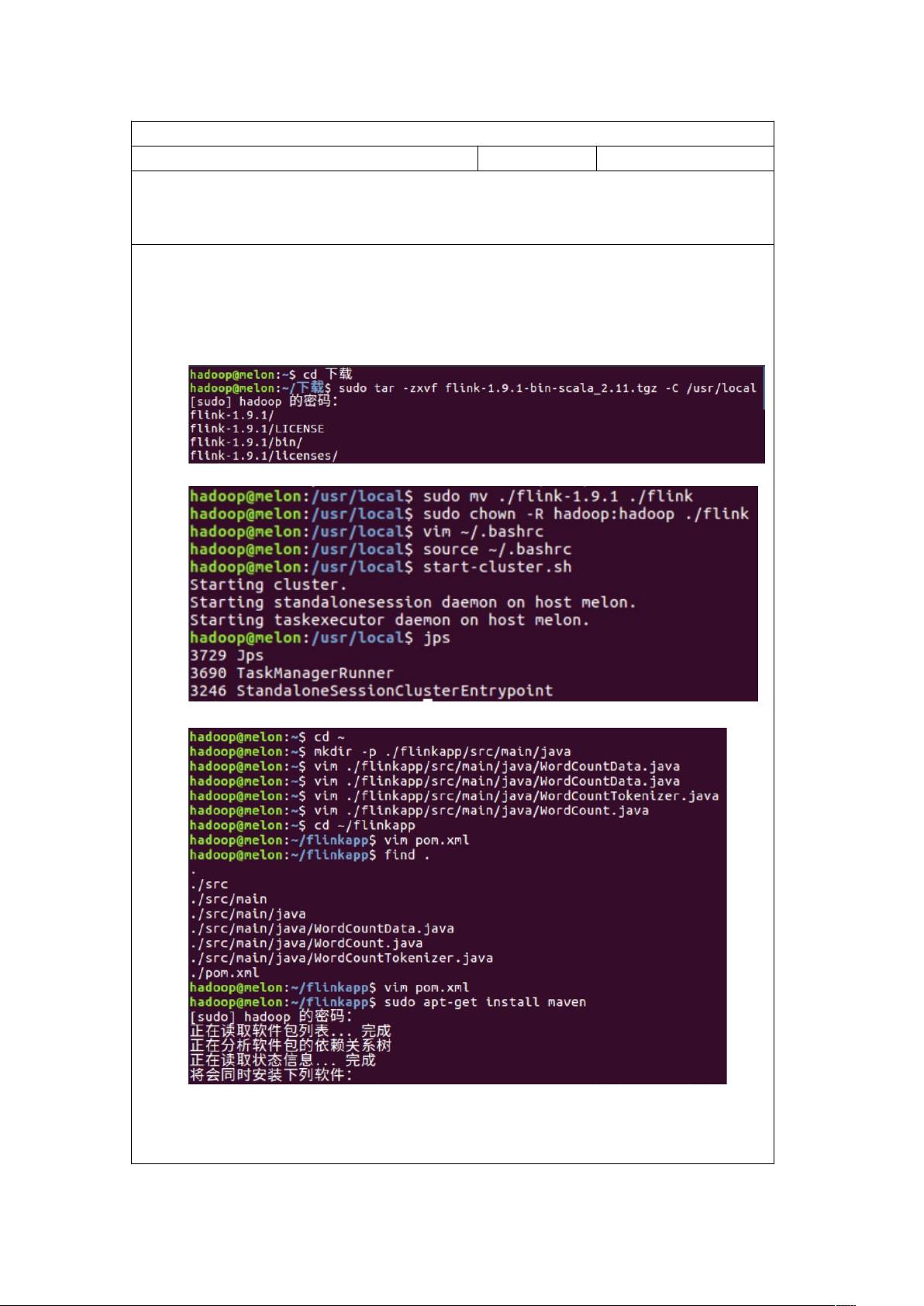
安装 Flink 并启动:
安装 maven:
下载后可阅读完整内容,剩余4页未读,立即下载
2024-01-16 上传
2022-04-20 上传
2018-06-27 上传
点击了解资源详情
2023-08-31 上传
2024-01-16 上传
2023-11-19 上传
2023-11-19 上传

是小猪猪哦
- 粉丝: 135
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- iamjoshbraun博客
- Password-Management-System-Nodejs-Mini_Project:使用Node js,Express js和Mongoose的初学者密码管理系统迷你项目
- reactjs-starter-kit:用于webpack捆绑包上的React JS应用的入门工具包(带有SCSS模块)
- SCA_SCA优化算法_正弦余弦优化算法_SCA_优化算法_正弦余弦算法
- Excel模板居民消费价格指数分析统计.zip
- algorithms-text-answers:在算法入门第3版中跟踪我的进度
- node-craigslist:搜索Craigslist.com列表的节点驱动程序
- physics_based_learning:计算成像系统的学习变得简单
- Python库 | python-google-places-1.2.0.tar.gz
- PMSM-vector-control_pmsm_BLDC_foc_滑膜观测器
- Ox_covid_data_and_charts
- react-native-smaato:Smaato支持** Android **和** iOS **
- Memoria-fox:用javascript编写的简单记忆游戏
- Python-Projects
- COMP397-KIIONICS-隐藏
- foundations_course:自治系统硕士课程新生的预备课程材料
