"解密深度学习泛化之谜:神经网络训练与梯度下降的奥秘"
需积分: 0 86 浏览量
更新于2024-03-16
收藏 4.01MB PDF 举报
The generalization mystery in deep learning refers to the phenomenon where over-parameterized neural networks trained with gradient descent successfully generalize well on real datasets, despite being able to fit random datasets of similar size. This raises the question of how gradient descent is able to find a solution that not only fits the training data but also generalizes well on unseen data. In their paper "ON THE GENERALIZATION MYSTERY IN DEEP LEARNING," Satrajit Chatterjee and Piotr Zielinski delve into this issue and argue that the key lies in the optimization process of gradient descent. They propose that through the iterative update of network parameters, gradient descent is able to navigate the solution space and converge on a well-generalizing solution. By understanding the underlying principles of generalization in deep learning, researchers can further enhance the performance and robustness of neural networks in real-world applications.
0 50 100 150 200 250 300
0.0
2.5
5.0
7.5
10.0
12.5
15.0
17.5
Real Data
Loss
Train
Test
0 50 100 150 200 250 300
0
20
40
60
80
100
Accuracy
Train
Test
0 50 100 150 200 250 300
0
20
40
60
80
m
/
m
(
m
= 50, 000)
Train
Test
012345678
0
20
40
60
80
m
/
m
(
m
= 50, 000)
Train
Test
0 50 100 150 200 250 300
Epoch
0.0
2.5
5.0
7.5
10.0
12.5
15.0
17.5
Random Data
Train
Test
0 50 100 150 200 250 300
Epoch
0
20
40
60
80
100
Train
Test
0 50 100 150 200 250 300
Epoch
0
20
40
60
80
Train
Test
012345678
Train Loss
0
20
40
60
80
Train
Test
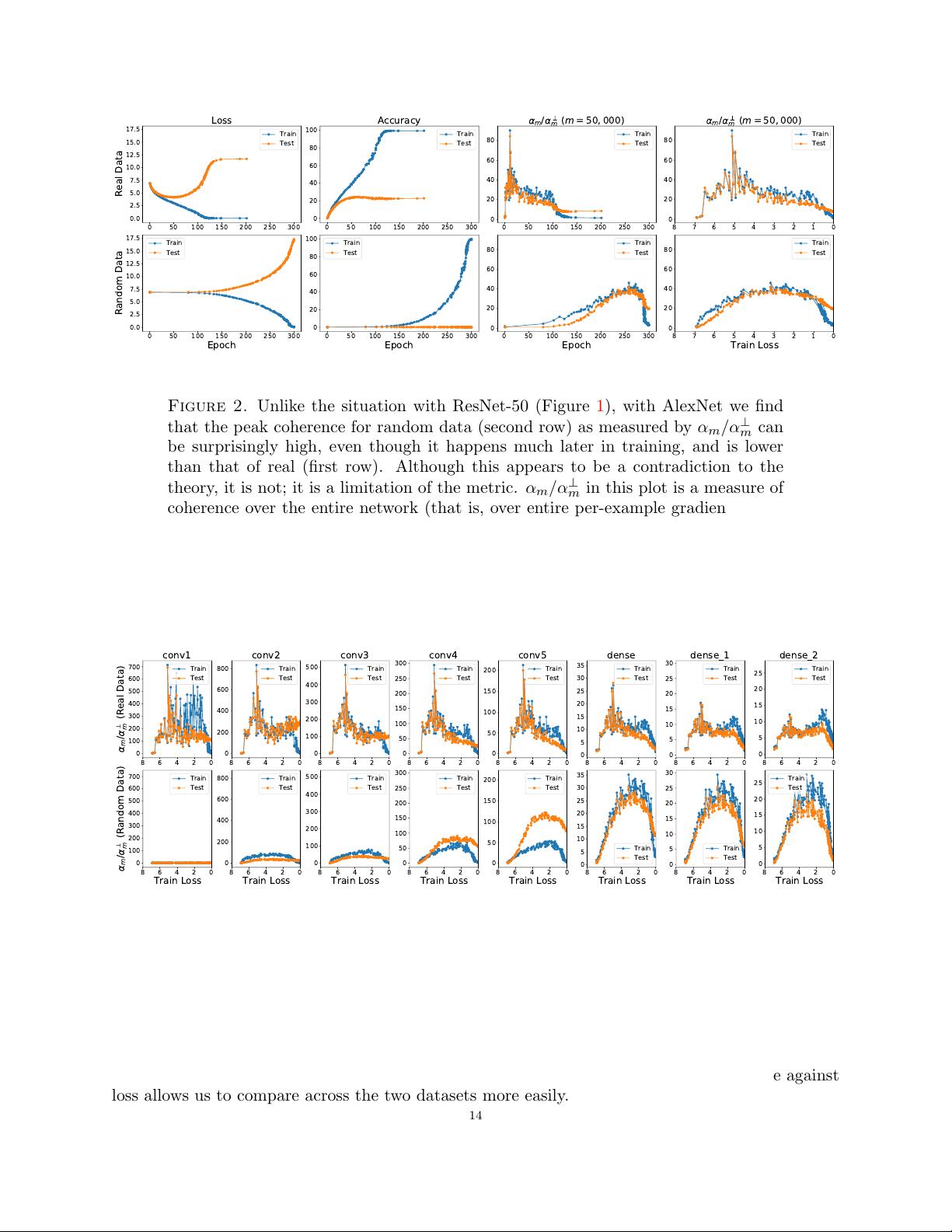
Figure 2. Unlike the situation with ResNet-50 (Figure 1), with AlexNet we find
that the peak coherence for random data (second row) as measured by α
m
/α
⊥
m
can
be surprisingly high, even though it happens much later in training, and is lower
than that of real (first row). Although this appears to be a contradiction to the
theory, it is not; it is a limitation of the metric. α
m
/α
⊥
m
in this plot is a measure of
coherence over the entire network (that is, over entire per-example gradients), and
is therefore an average quantity. A closer look at the layer-by-layer values of α
m
/α
⊥
m
as shown in Figure 3 reveals, once again, a significant difference between real and
random data.
02468
0
100
200
300
400
500
600
700
m
/
m
(Real Data)
conv1
Train
Test
02468
0
200
400
600
800
conv2
Train
Test
02468
0
100
200
300
400
500
conv3
Train
Test
02468
0
50
100
150
200
250
300
conv4
Train
Test
02468
0
50
100
150
200
conv5
Train
Test
02468
0
5
10
15
20
25
30
35
dense
Train
Test
02468
0
5
10
15
20
25
30
dense_1
Train
Test
02468
0
5
10
15
20
25
dense_2
Train
Test
02468
Train Loss
0
100
200
300
400
500
600
700
m
/
m
(Random Data)
Train
Test
02468
Train Loss
0
200
400
600
800
Train
Test
02468
Train Loss
0
100
200
300
400
500
Train
Test
02468
Train Loss
0
50
100
150
200
250
300
Train
Test
02468
Train Loss
0
50
100
150
200
Train
Test
02468
Train Loss
0
5
10
15
20
25
30
35
Train
Test
02468
Train Loss
0
5
10
15
20
25
30
Train
Test
02468
Train Loss
0
5
10
15
20
25
Train
Test
Figure 3. A layer-by-layer breakdown of α
m
/α
⊥
m
for AlexNet from Figure 2 shows
that on random data (second row), α
m
/α
⊥
m
is indeed close to 1 and much lower than
that of real data (first row) for the first few layers. For the higher (dense) layers,
coherence is comparable between real and random, though note the difference in
scale of α
m
/α
⊥
m
between the convolutional and dense layer plots.
different for the two datasets (the real data is learned in fewer epochs), plotting coherence against
loss allows us to compare across the two datasets more easily.
14



剩余81页未读,继续阅读
200 浏览量
点击了解资源详情
142 浏览量
270 浏览量
314 浏览量
404 浏览量
2021-03-03 上传
293 浏览量
2021-05-01 上传

尹子先生
- 粉丝: 30
- 资源: 324
 我的内容管理
展开
我的内容管理
展开







最新资源
- vip会员统计表excel模版下载
- containerBooking
- like-me
- node-async-await-example:具有异步等待用法的Node.js应用程序的简单示例
- F460dll_for_TOT_KLS.rar
- NRRD 格式文件阅读器:NRRD 文件阅读器-matlab开发
- upptime:Up Upptime的正常运行时间监视器和状态页面,由@upptime提供支持
- 幼儿园财务报表excel模版下载
- Calculator:在Android Studio上使用Kotlin的基本计算器
- luckytuan-fast-loader-master.zip
- adc-analysis:SciCRT的跟踪分析
- SCANProject:堆叠式交叉注意项目页面
- 公司会议室3D模型
- pushNaNs:将 NaN 推送到 X 的每一列的底部。-matlab开发
- ManuelGil:个人资料
- 爱普生(Epson)L805 原版清零软件
