Hadoop与Spark性能对比:迭代计算与实时处理中的显著差异
需积分: 9 91 浏览量
更新于2024-07-17
收藏 2.52MB DOCX 举报
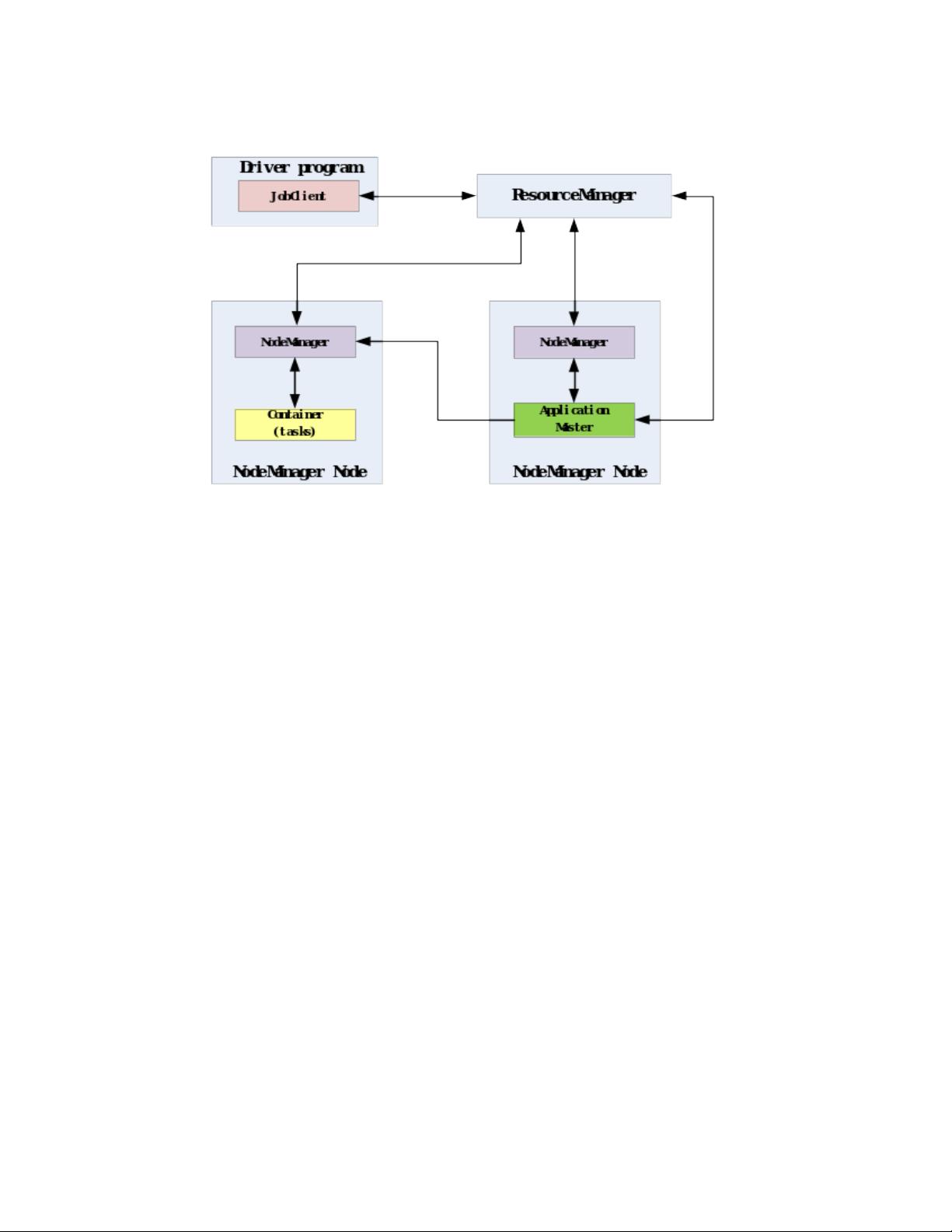
本篇英文论文深入探讨了Hadoop和Spark在大数据处理领域的性能对比,特别关注于迭代计算和实时数据分析的应用。文章首先概述了Hadoop和Spark的基本架构,指出Hadoop基于MapReduce模型,而Spark则采用弹性分布式数据集(RDD)和内存计算的核心机制。Hadoop的运行主要依赖于硬盘I/O操作,而Spark通过内存优化来提高执行速度。
论文的重点部分通过WordCount(单词计数)、按键排序和PageRank等三个实际案例,展示了随着数据量的增加和迭代次数增多,Spark在性能上相对于Hadoop的优势逐渐显现。在这些例子中,Spark由于其对内存的高效利用和避免频繁的磁盘I/O,显示出更快的处理速度。然而,这伴随着对内存资源的需求增加,如果内存不足,可能会影响整体性能。
为了提升系统性能,作者详细介绍了如何在Hadoop和Spark中进行优化,比如调整数据压缩类型、内存分配策略以及数据分割方式。Spark提供了额外的优化选项,如内存带宽利用率、降低磁盘I/O操作频率和减少任务初始化时间,使得Spark在性能优化方面更为出色。
此外,论文还包含了安装和启动Hadoop和Spark的指南,以及如何使用Java编程实现这三个案例研究的步骤。同时,为了确保结果的准确性,文中也提到了验证运行结果的方法。
关键词:MapReduce、RDD、延迟、排序、排名、执行器、优化
文章的结构清晰,从介绍两者的背景和运行架构开始,再到生态系统的对比,最后是实验设计、性能优化和实施步骤。这篇论文提供了一个全面且深入的分析,帮助读者理解Hadoop和Spark在大数据处理中的优缺点,并指导用户如何在实际场景中选择和优化这两者。

--
A $3A $3
>--?*0
->-?
>4?
*0@,
-@,
Framework Components Description
%*
B%*C
>-?
A
$3
BA $3C
"
>-?
#$ H
I( I(G
I(F%6,
/%6, I(!
>4?
>4?
#(( #(
>4?
5!@
>4?

剩余63页未读,继续阅读
2021-03-21 上传
2021-07-06 上传
2021-06-04 上传
2021-05-21 上传
2022-07-13 上传
2021-03-10 上传
2021-04-02 上传
2021-03-05 上传

weixin_40364869
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- matlab教程关于命令方面
- SQL2005语句详解
- ASP.net中md5加密码的方法
- 内存调试技巧:C 语言最大难点揭秘
- 随着计算机的发展和普及,计算机系统数量与日俱增,为了保证计算机系统安全可靠工作,网络监控系统的应用也日渐广泛。本文主要介绍机房网络监控系统的现状和发展。
- ORACLE财务讲解.pdf
- 计算机外文翻译基于J2EE
- 所有的网络协议关系(ip,udp,tcp)
- 高质量C、C++编程指南
- 动态抓取网页内容,蜘蛛程序
- 会话初始协议(SIP)第三方呼叫控制的研究
- 网络工程师必懂的十五大专业术语
- 高质量C_C编程指南
- 浅谈E1线路维护技术与应用.doc
- java试题及答案下载
- Delphi 7 程序设计与开发技术大全
