理解与实现:MeanShift与Camshift算法详解
需积分: 10 172 浏览量
更新于2024-07-21
收藏 1.16MB DOCX 举报
MeanShift算法是一种无参数的非监督学习方法,用于估计数据集中的高密度区域,其核心思想是迭代地寻找数据点周围概率密度最高的区域。算法流程基于以下几个关键步骤:
1. **初始选择**:选择一个初始窗口,如矩形或圆形,其中包含一个特征数据点作为起点。
2. **密度估计**:计算窗口内的数据点概率密度,这通常使用K近邻方法或基于核函数的加权平均,如高斯核,以考虑邻域内的数据分布。
3. **梯度上升**:计算概率密度函数的梯度,即窗口中心在各个方向上的密度变化率。梯度指向密度增大的方向,意味着向数据更密集的地方移动。
4. **窗口偏移**:基于梯度的方向,对窗口进行微小的移动,使其中心朝向梯度上升的方向。
5. **迭代过程**:重复步骤3和4,直至窗口中心的移动量(偏移向量的模值)足够小,表明已经接近概率密度函数的极大值区域。
6. **核函数应用**:在实际应用中,可能会引入核函数来赋予不同数据点不同的权重,因为并非所有数据点对目标判定的影响相同。常见的核函数如高斯核可以调整窗口内数据点的贡献,使算法对局部特征更加敏感。
MeanShift-CamShift算法是MeanShift的一种变体,它在视频监控中的行人跟踪中特别有用。CamShift (Camera Shift) 引入了连续性和实时性的概念,将MeanShift应用于连续帧上,通过保持窗口的位置和大小一致性,从而实现实时追踪。在每个时间步,算法会计算当前帧中窗口位置的最优移动,使得窗口内的特征匹配度最高。
理解MeanShift的关键在于认识到它是一个局部搜索过程,通过不断优化窗口中心以适应数据的全局密度模式。这个方法在无先验知识的场景下非常灵活,但可能会收敛速度较慢,且对于噪声和复杂背景的影响较为敏感。然而,通过结合合适的核函数和实时策略,MeanShift和CamShift在很多实际问题中都能展现出强大的性能。

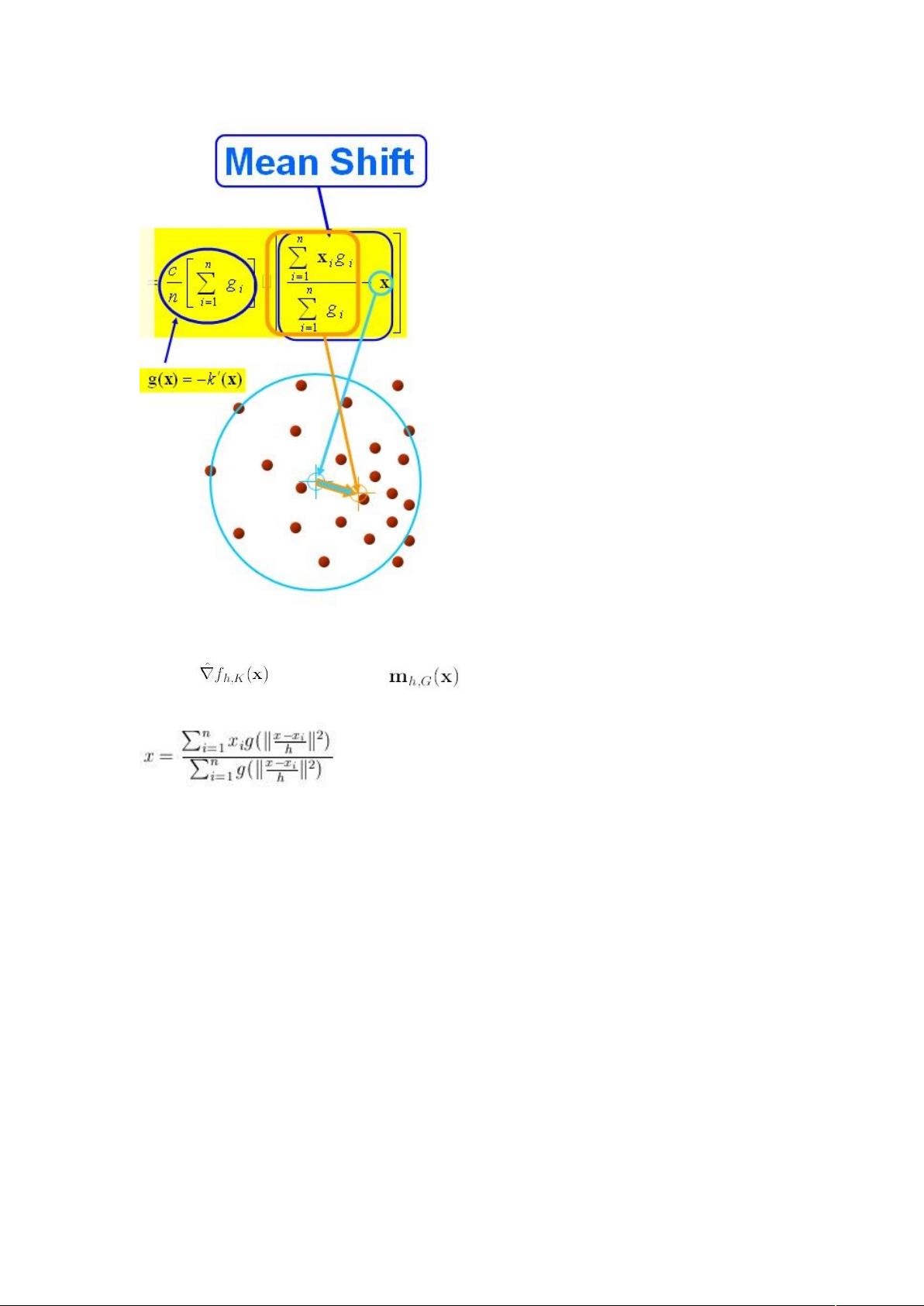
K(x)叫做 g(x)的影子核,名字听上去听深奥的,也就是求导的负方向,那么上
式可以表示
对于上式,如果才用高斯核,那么,第一项就等于 f
h,k
第二项就相当于一个 meanshift 向量的式子:
那么(2)就可以表示为
下图分析 的构成,如图所以,可以很清晰的表达其构成。
剩余46页未读,继续阅读
1805 浏览量
134 浏览量
2022-09-14 上传
2010-07-14 上传
2010-08-05 上传
2022-07-14 上传
2023-03-31 上传

artlife_sun
- 粉丝: 2
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 中国项目管理师培训讲义——费用管理
- SWF:一些用于处理SWF文件的python脚本
- 作品集:专为展示我的所有作品而创建的项目
- neural_network_projects:这是一些基本的神经网络
- STSensNet_Android:“ ST BLE StarNet” Android应用程序源代码-Android application source code
- SLIC-ImageSegmentation:基于SLIC图像分割算法实现一个比PS魔棒工具还方便的抠图工具
- yet-another-istanbul-mocha-no-coverage
- 四卡功能
- android 一个杀进程 程序分享,包含源代码-网络攻防文档类资源
- babel_pug_project:通过babel,pug,node,express进行Web服务器教育.....
- 爱普生7710 7720l免芯片固件刷rom附安装说明
- GenericInstsBenchmark
- AK_Lab2
- MADSourceCodes:“使用Android移动应用程序开发”课程源代码-Android application source code
- themeweaver:使用设计标记在浏览器中创建kick-ass IDE主题!
- oo-way-getonboard中的战舰:GitHub Classroom创建的oo-way-getonboard中的战舰
