Hadoop MapReduce详解:分布式计算的核心框架
需积分: 5 115 浏览量
更新于2024-07-09
收藏 11.5MB DOC 举报
"这篇文档详细介绍了Hadoop中的MapReduce技术,包括MapReduce的概念、核心思想、进程以及编程规范。"
MapReduce是Hadoop生态系统中的关键组件,它为处理和存储大规模数据提供了强大的分布式计算框架。MapReduce的核心在于将复杂的分布式计算任务分解为两个主要阶段:Map和Reduce,简化了开发人员在大数据分析应用中的工作。
1. MapReduce概念
MapReduce是一种编程模型,用于处理和生成大规模数据集。它通过将计算任务分布到集群中的多台机器上,解决了单机处理海量数据的局限性。MapReduce框架处理了分布式计算的复杂性,如任务切片、任务调度、监控和容错,使得开发者可以专注于编写业务逻辑。
1.1 为何使用MapReduce
- 单机处理能力有限,面对海量数据时难以胜任。
- 分布式运行增加了程序设计的复杂性和难度。
- MapReduce框架承担了分布式计算中的复杂性,让开发人员只需关注业务逻辑。
- MapReduce解决分布式运算的逻辑划分、任务分配、启动协调和监控等问题。
1.2 MapReduce核心思想
- Map阶段:数据预处理,将原始输入数据转化为中间键值对。
- Reduce阶段:数据聚合,将Map阶段产生的中间结果进行合并处理,生成最终结果。
1.3 MapReduce进程
- MrAppMaster:应用程序管理者,负责调度整个MapReduce作业,协调状态。
- MapTask:执行Map阶段,对输入数据进行处理,生成中间键值对。
- ReduceTask:执行Reduce阶段,接收所有MapTask的输出,进行汇总处理。
1.4 MapReduce编程规范
用户编写的MapReduce程序通常包括三个主要部分:
1. Mapper:实现Map函数,将输入数据转化为中间键值对。
2. Reducer:实现Reduce函数,对Map阶段的输出进行聚合,产生最终结果。
3. Driver:驱动程序,设置作业参数,提交作业到Hadoop集群。
总结来说,Hadoop的MapReduce是处理大数据的关键工具,它通过分治策略简化了大数据处理,让开发人员能够高效地构建和运行分布式数据处理应用程序。MapReduce的设计允许并行化执行,提高了数据处理的速度和效率,同时其容错机制确保了系统的可靠性。在实际应用中,开发者可以结合HDFS(Hadoop分布式文件系统)和YARN(资源调度器)等其他Hadoop组件,构建完整的数据处理解决方案。

大数据技术之 Hadoop(MapReduce)
—————————————————————————————
2.2.3 自定义 InputFormat
)概述
()自定义一个 :;
()改写 ,实现一次读取一个完整文件封装为 &'
()在输出时使用 Q;.CK; 输出合并文件
)案例实操
详见 +( 小文件处理(自定义 :;)。
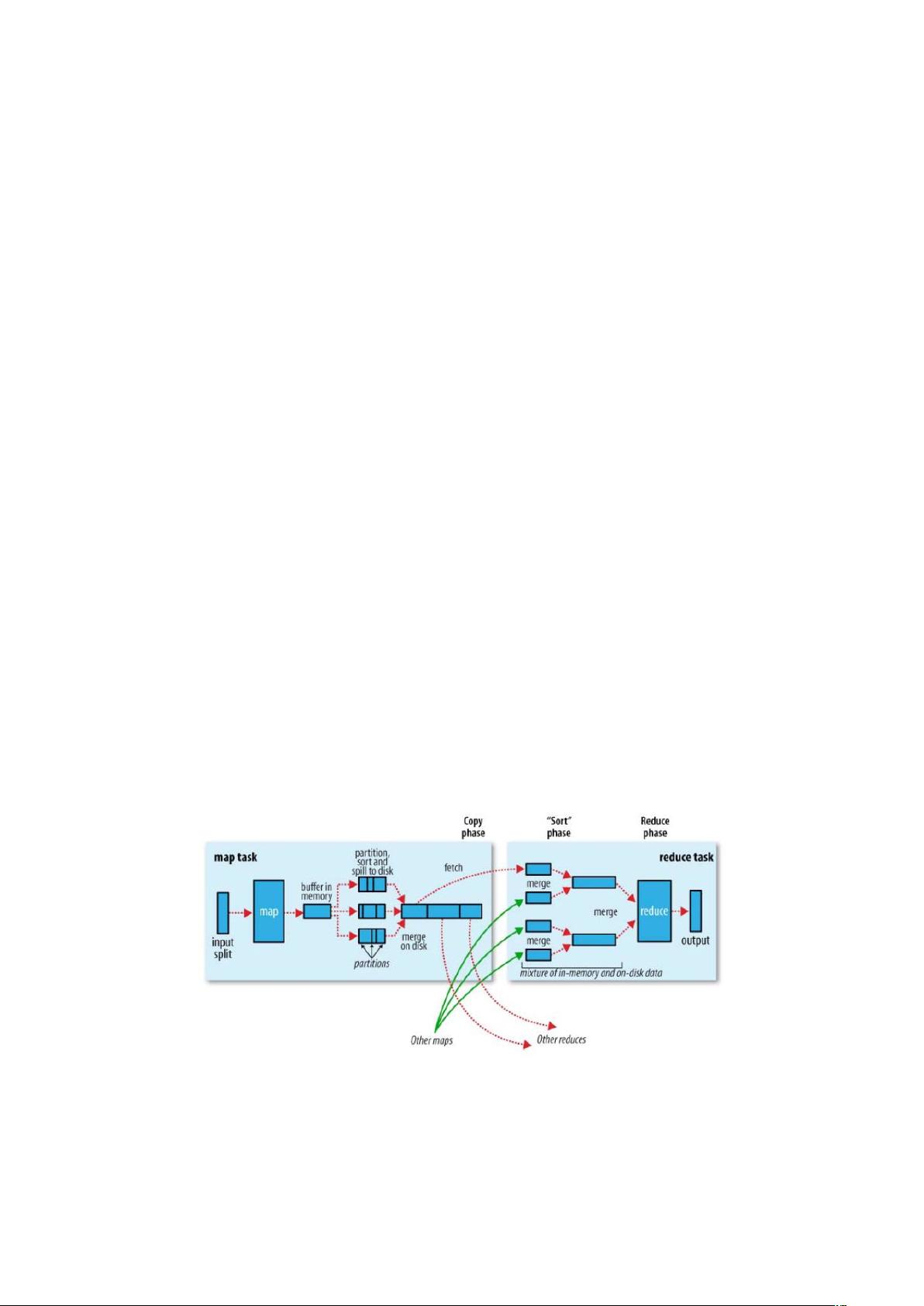
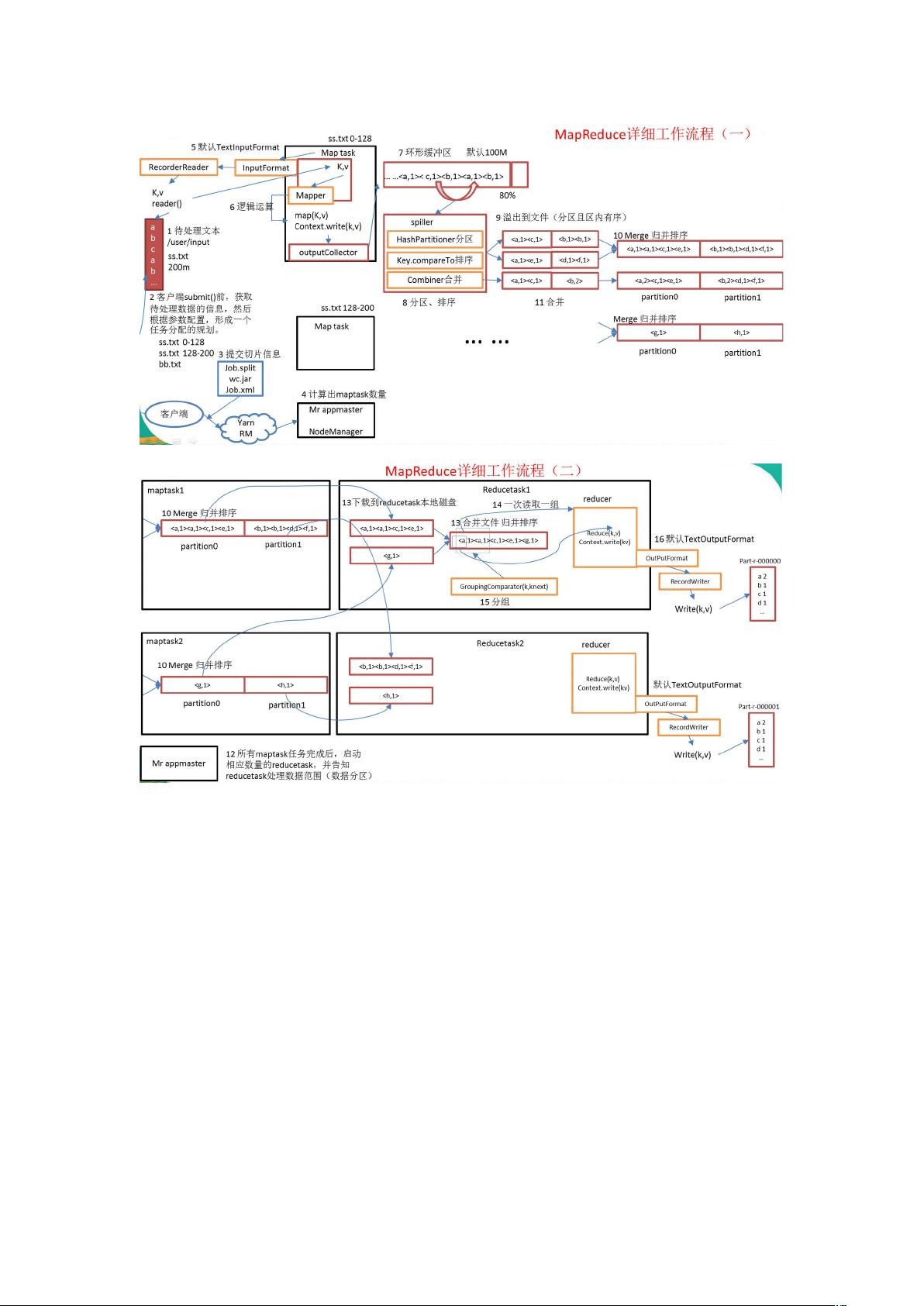
2.3 MapTask 工作机制
)问题引出
的并行度决定 阶段的任务处理并发度,进而影响到整个 )* 的处理速度。
那么, 并行任务是否越多越好呢?
) 并行度决定机制
一个 )* 的 阶段 并行度(个数),由客户端提交 )* 时的切片个数决定。
) 工作机制
() 阶段: 通过用户编写的 ,从输入 :. 中解析出
一个个 0?.。
() 阶段:该节点主要是将解析出的 0?. 交给用户编写 函数处理,并
产生一系列新的 0?.。
()-.. 阶段:在用户编写 函数中,当数据处理完成后,一 般 会调用
C-..+..输出结果。在该函数内部,它会将生成的 0?. 分区(调用
K),并写入一个环形内存缓冲区中。
().. 阶段:即“溢写”,当环形缓冲区满后, 会将数据写到本地磁盘上,
生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地
排序,并在必要时对数据进行合并、压缩等操作。
溢写阶段详情:
步骤 :利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编
号 进行排序,然后按照 0 进行排序。这样,经过排序后,数据以分区为单位聚
集在一起,且同一分区内所有数据按照 0 有序。
步骤 :按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时
剩余63页未读,继续阅读
2022-10-31 上传
2022-10-31 上传
2020-09-15 上传
2019-05-19 上传
2021-08-11 上传
2021-01-09 上传
2021-10-06 上传
2021-11-15 上传

hqx_2008
- 粉丝: 1
- 资源: 22
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
