阿里巴巴HBase堆外内存读取优化:30%性能提升
需积分: 14 118 浏览量
更新于2024-09-09
收藏 565KB PPTX 举报
"这篇文章讲述了阿里巴巴如何应对2016年双十一期间阿里巴巴-Search HBase集群面临的每秒数千万请求的挑战。通过实现堆外内存读取路径(read-path off-heaping),阿里巴巴成功提升了30%的吞吐量,并实现了可预测的延迟。"
在HBase的高并发场景下,内存管理是性能优化的关键。传统的HBase读取路径中,缓存(如L1 Cache)通常位于堆内存中,以提高数据读取速度。然而,随着缓存规模的扩大,会引发Java堆内存的增大,进而带来垃圾收集(GC)问题,这可能对系统性能产生负面影响,尤其是在处理大量请求时。
为了解决这个问题,阿里巴巴引入了堆外内存(Off-Heap Memory)的读取路径,即L2 Bucket Cache。这个缓存层存储在堆外,不受Java堆大小限制,可以支持更大的缓存容量,例如4MB的物理内存缓冲区,分为不同大小的桶(buckets),如5KB、9KB到513KB等。每个桶至少有4个槽位,用于存放HFile块。这样的设计允许数据按适合的桶大小分配,即使一个块跨越两个缓冲区也能高效处理。
HBase的读取路径假设数据存储在字节数组中,包括行键、列族和值等部分。当读取请求到达时,系统会通过region server的扫描器层层解析,对于堆内Block,数据会被复制到堆外的Bucket Cache中的Java ByteBuffer,然后在适当的桶槽位获取Block。这个过程减少了对堆内存的依赖,从而避免了因大缓存导致的GC问题,提升了读取吞吐量并改善了延迟的可预测性。
为了实现堆外读取路径,阿里巴巴需要构建一个新的机制来处理Cell的数据结构。这个过程中,他们可能需要重新设计数据的封装方式,确保即使在堆外内存中,也能正确地处理和访问数据的各个部分。这种优化不仅提高了系统性能,还降低了双十一等大型促销活动期间的系统风险,展示了阿里巴巴在大数据处理和优化方面的深厚技术积累。
总结来说,阿里巴巴通过采用堆外内存的HBase读取路径,成功地解决了大规模并发请求下的性能瓶颈问题,提升了系统的稳定性和效率。这一策略对于其他处理海量数据的公司和项目具有重要的参考价值,尤其是在面临类似挑战时,堆外内存的利用可以成为优化系统性能的一个有效途径。
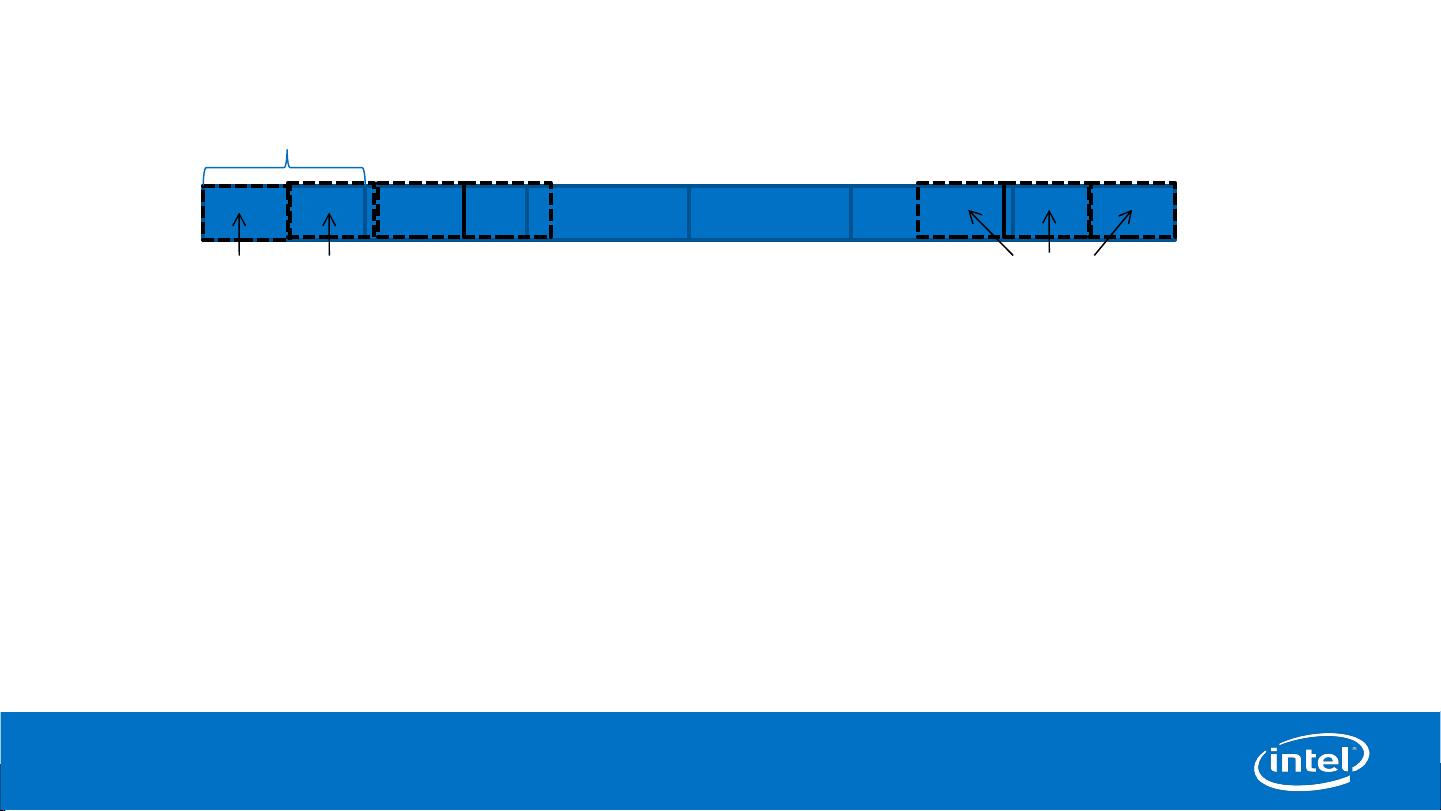
▪
L2 offheap cache can give large cache size
▪
4 MB physical memory buffers.
▪
Different sized buckets 5 KB, 9 KB,… 513 KB. Each bucket having at least 4 slots
▪
HFile blocks placed in appropriate sized bucket
▪
One Block may span across 2 ByteBuffers.
▪
Read path assumption of data being in a byte array.
▪
Cells having assumption of data parts being in byte array. (ie. Rowkey, family, value
etc)
Bucket Cache overview
4 MB
5
K
B
b
u
c
k
e
t
s
9
K
B
b
u
c
k
e
t
s
513 KB buckets
剩余13页未读,继续阅读
2018-09-03 上传
2021-11-21 上传
2021-10-11 上传
2021-10-19 上传
2022-07-11 上传
2019-08-28 上传
2021-02-25 上传

flexy
- 粉丝: 5
- 资源: 23
 我的内容管理
展开
我的内容管理
展开







