硬盘分区指南:从Fdisk到逻辑分区的步骤解析
需积分: 1 185 浏览量
更新于2024-07-31
收藏 715KB DOC 举报
"分布式文件系统的教程"
分布式文件系统是一种在多台计算机之间共享和存储数据的系统,它通过网络连接这些计算机,并将它们的存储资源统一管理,形成一个虚拟的大型存储设备。这样的系统允许用户和应用程序透明地访问分布在不同位置的数据,而无需关心数据实际存储在哪里。在本教程中,我们将探讨分布式文件系统的概念、操作步骤以及相关知识点。
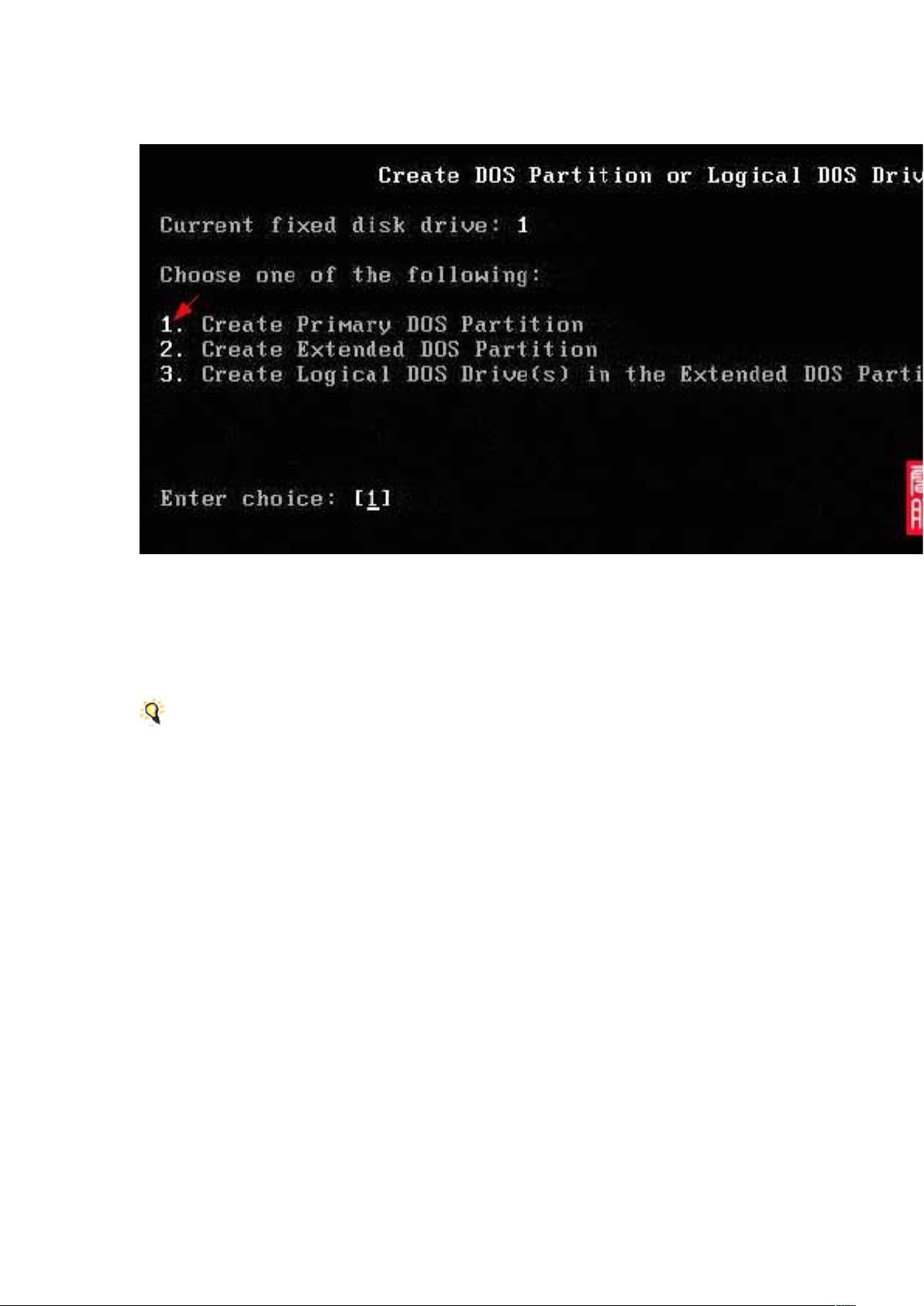
在介绍分布式文件系统之前,让我们回顾一下传统的磁盘分区过程,这是理解分布式文件系统的基础。在传统的磁盘管理中,我们需要使用像Fdisk这样的工具来对硬盘进行分区。例如,创建主分区、扩展分区和逻辑分区。主分区通常用于安装操作系统,如Windows的C盘。扩展分区则是在主分区之外划分的空间,可以进一步划分为多个逻辑分区。逻辑分区是在扩展分区内部创建的,用于存储数据,比如D盘、E盘等。在创建过程中,用户需要根据自己的需求决定每个分区的大小。
然而,随着数据量的急剧增长,单个服务器的存储能力已无法满足需求,分布式文件系统应运而生。分布式文件系统通过将数据分割成多个块,然后在集群中的多台服务器上分布存储,提供了高可用性、容错性和可扩展性。常见的分布式文件系统有Hadoop HDFS(Hadoop Distributed File System)、Google的GFS(Google File System)、Amazon S3(Simple Storage Service)等。
Hadoop HDFS是开源的分布式文件系统,广泛应用于大数据处理。它设计的目标是处理大规模数据集,能够容忍硬件故障,并且具有高吞吐率。HDFS的核心原理是将大文件分割成多个数据块,并在不同的节点上复制,以确保数据的安全性和可靠性。HDFS的写入过程是写一次,读多次,适合批处理作业。同时,HDFS提供了NameNode和DataNode的概念,NameNode负责元数据管理,DataNode则是数据的实际存储节点。
GFS是Google为内部大数据处理设计的分布式文件系统,它具有高吞吐量、低延迟的特点,适用于实时分析和流式计算。GFS的核心设计包括一个主控服务器(Master)和多个数据节点(Chunkservers)。Master维护文件系统的全局视图,而Chunkservers负责存储数据块。
Amazon S3是云存储服务,提供简单、安全的在线存储解决方案。用户可以通过API接口访问S3,存储和检索任何数量的数据,无论何时何地。S3支持对象存储,每个对象都是由数据和元数据组成,可以设置权限和生命周期策略。
分布式文件系统的优点包括:
1. 高可用性:通过数据复制,即使部分节点故障,也能保证数据的可访问性。
2. 扩展性:随着硬件的增加,系统可以无缝地扩展存储容量和处理能力。
3. 故障恢复:自动的数据备份和恢复机制,提高了系统的稳定性和可靠性。
4. 并行处理:多个节点可以并行处理数据,提高处理速度。
然而,分布式文件系统也存在挑战,如数据一致性、网络延迟、复杂性管理等问题,需要通过精心设计和优化来解决。
分布式文件系统是现代大数据处理和云计算不可或缺的一部分,它改变了我们管理和处理海量数据的方式,为企业和个人提供了高效、可靠的存储解决方案。通过学习和理解分布式文件系统的原理和实践,我们可以更好地适应数据驱动的时代。
剩余14页未读,继续阅读
942 浏览量
2012-04-06 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
121 浏览量
908 浏览量
点击了解资源详情
点击了解资源详情

q274208375
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- easypanel虚拟主机控制面板 v1.3.2
- Coursera
- wind-js-server:用于将Grib2风向预报数据公开为JSON的服务
- 生命源头论坛 LifeYT-BBS V2.1
- TUTK_IOTC_Platform_14W42P2.zip TUTK IOTC官方sdk
- WeatherJournalApp
- 电商小程序源码项目实战
- 美女婚纱照片模板下载
- GB 50231-1998 机械设备安装工程施工及验收通用规范.rar
- MPT-开源
- facebook-archive:使用Facebook的存档数据可以享受一些乐趣
- 阿普奇工业显示器PANEL2000.zip
- action_react
- Torus-开源
- 应用js
- WPF将控件中的文字旋转.zip
