kd树与最近邻搜索:实例学习与数据结构详解
需积分: 10 23 浏览量
更新于2024-08-01
收藏 182KB PDF 举报
"本资源是一篇关于实例学习中的最近邻算法(Nearest Neighbors)和kD树(k-Dimensional Trees)的基础教程,由Steve Renals撰写,适合于Informatics 2B课程的第六次讲座,日期为2007年1月。这篇教程主要涵盖了以下几个关键知识点:
1. 实例基础学习:实例学习方法强调直接存储训练数据样本,无需估计模型参数。这种方法的核心是将未知测试点分类为训练集中与其最相似的样本所属的类别。
2. 最近邻方法:通过计算测试点与训练集中的每个样本的距离,确定最近邻(Nearest Neighbor),即距离最近的那个样本。这种方法用于模式识别,但其有效性取决于如何高效地找到最近邻。
3. 问题与挑战:教程指出,对于高维数据,直接对所有训练样本进行比较会导致复杂度急剧上升,因为搜索时间会随着维度n和样本数量k线性增长,效率低下。这就引出了如何在多维空间中更有效地寻找最近邻的问题。
4. kD树的引入:为了克服高维空间搜索的难题,kD树作为一种数据结构被提出。kD树是一种有序的多叉树,通过分割数据维度,将多维空间划分为较小的子区域,使得搜索最近邻的时间复杂度降低到对数级别(O(log n))。
5. kD树的构建和搜索:kD树的构建过程包括选择一个最优的分割维度和阈值,然后递归地将数据集划分。搜索时,通过对比测试点和当前节点的特征,可以在树中快速缩小搜索范围,显著提高了查找最近邻的效率。
6. 应用和讨论:尽管最近邻方法可能看起来像是一个启发式方法,但它确实有概率论基础,比如在某些假设下可以转化为概率模型。教程还将探讨这些方法在实际应用中的效果,以及它们如何适应不同场景和挑战。
这篇教程为学习者提供了深入理解最近邻算法及其与kD树相结合的有效处理高维数据的方法,是理解实例学习和数据结构在机器学习中角色的重要参考资料。"
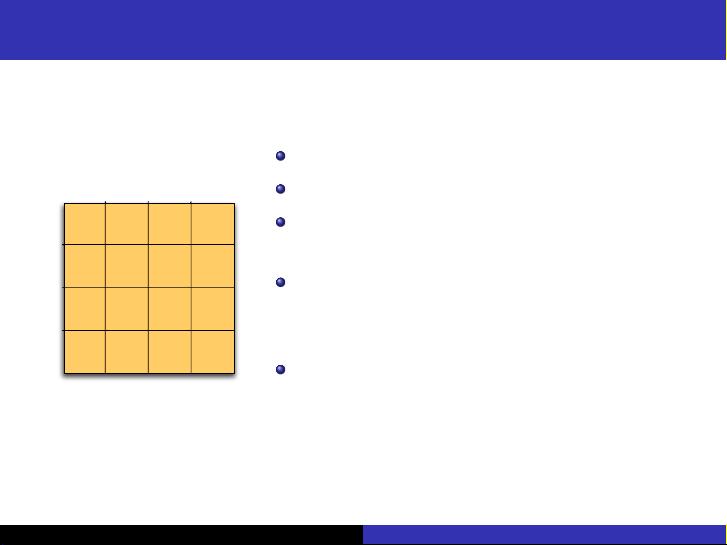
Structuring multidimensional data: Grid
k-dimensional array of buckets
Uniformly partition each dimension
Different dimensions can be cut in a
different number of pieces
Accessing a point involves checking each
dimension to determine in which bucket
it falls
Ideal if the data is uniformly distributed
(which is never the case in high
dimensions)
Steve Renals Nearest neighbours and kD-trees
剩余21页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-05-09 上传
2018-09-11 上传
2021-05-30 上传
2021-03-29 上传
2021-05-23 上传
2022-09-19 上传

waenng
- 粉丝: 1
- 资源: 25
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
