使用R进行文本挖掘:整洁方法
需积分: 10 185 浏览量
更新于2024-07-18
收藏 7.4MB PDF 举报
"朱莉娅·希尔吉和大卫·罗宾逊的《R语言文本挖掘:整洁的方法》是O'Reilly Media出版的一本书,主要探讨如何使用R语言进行文本挖掘和自然语言处理(NLP)。\n\n这本书的第一章介绍了整洁文本格式。作者对比了整洁文本与其他数据结构的区别,并详细讲解了`unnest_tokens`函数的用法。通过分析简·奥斯汀的作品,展示了如何将文本转换成整洁的数据格式,并介绍了`gutenbergr`包在获取和处理古腾堡项目文本中的作用。此外,还讨论了词频统计。\n\n第二章专注于情感分析。书中介绍了`sentiments`数据集,展示了如何使用内连接进行情感分析,并比较了三种不同的情感词典。此外,书中还展示了最常见的正面和负面词汇,以及如何生成词云来可视化这些数据。最后,扩展到分析词语组合,而不仅仅是单个单词。\n\n第三章深入到词频和文档频率分析,特别是tf-idf概念。希尔吉和罗宾逊分析了简·奥斯汀小说中的词频,并讨论了齐普夫定律。他们介绍了一个名为`bind_tf_idf`的函数,并应用到物理学文本的语料库中。\n\n第四章则关注词与词之间的关系,如n-grams和相关性。作者解释了如何通过n-gram进行分词,并展示了计数和过滤n-gram的方法,以及如何探索词与词之间的关联。"
《R语言文本挖掘:整洁的方法》是一本面向R语言使用者的文本分析指南,作者Julia Silge和David Robinson通过实际案例,深入浅出地讲解了如何利用R语言进行有效的文本挖掘。书中的核心理念是采用“整洁的数据”方法,即数据应具有清晰的结构,使得分析过程更为高效和直观。
在文本挖掘的基础部分,书中详细介绍了如何将原始文本转换成符合tidyverse框架的数据结构,特别强调了`unnest_tokens`函数的使用,该函数能够将文本拆分成单独的词项。此外,`gutenbergr`包的应用展示了如何获取和预处理公开的文学作品,例如简·奥斯汀的小说,以便进一步分析。
情感分析章节中,作者提供了使用R进行情感倾向分析的方法,包括如何利用内置的`sentiments`数据集和不同的情感词典进行情感极性的判断。同时,通过词云和词的组合分析,读者可以理解情感分析在实际应用中的多维度考虑。
在词汇和文档频率分析章节,书中提到了tf-idf(词频-逆文档频率)这一重要概念,它可以帮助识别哪些词在文档集合中具有重要意义。作者通过实例展示了如何计算tf-idf值,并构建了物理文本的语料库,以进一步演示这种方法。
最后,关于n-grams和相关性分析,作者引导读者探索词组间的关联,这是理解文本结构和主题的关键步骤。通过n-gram分析,可以发现词与词之间的联系,从而揭示文本的潜在模式。
这本书为R语言使用者提供了一套完整的文本挖掘工具箱,无论是在学术研究还是实际工作中,都能帮助读者有效地理解和处理文本数据。通过实例和详细讲解,使得复杂的技术变得易于理解和应用。

words that are not useful for an analysis, typically extremely common words such as
“the,” “of,” “to,” and so forth in English. We can remove stop words (kept in the tidy‐
text dataset stop_words) with an anti_join().
data(stop_words)
tidy_books <- tidy_books %>%
anti_join(stop_words)
The stop_words dataset in the tidytext package contains stop words from three lexi‐
cons. We can use them all together, as we have here, or filter() to only use one set
of stop words if that is more appropriate for a certain analysis.
We can also use dplyr’s count() to find the most common words in all the books as a
whole.
tidy_books %>%
count(word, sort = TRUE)
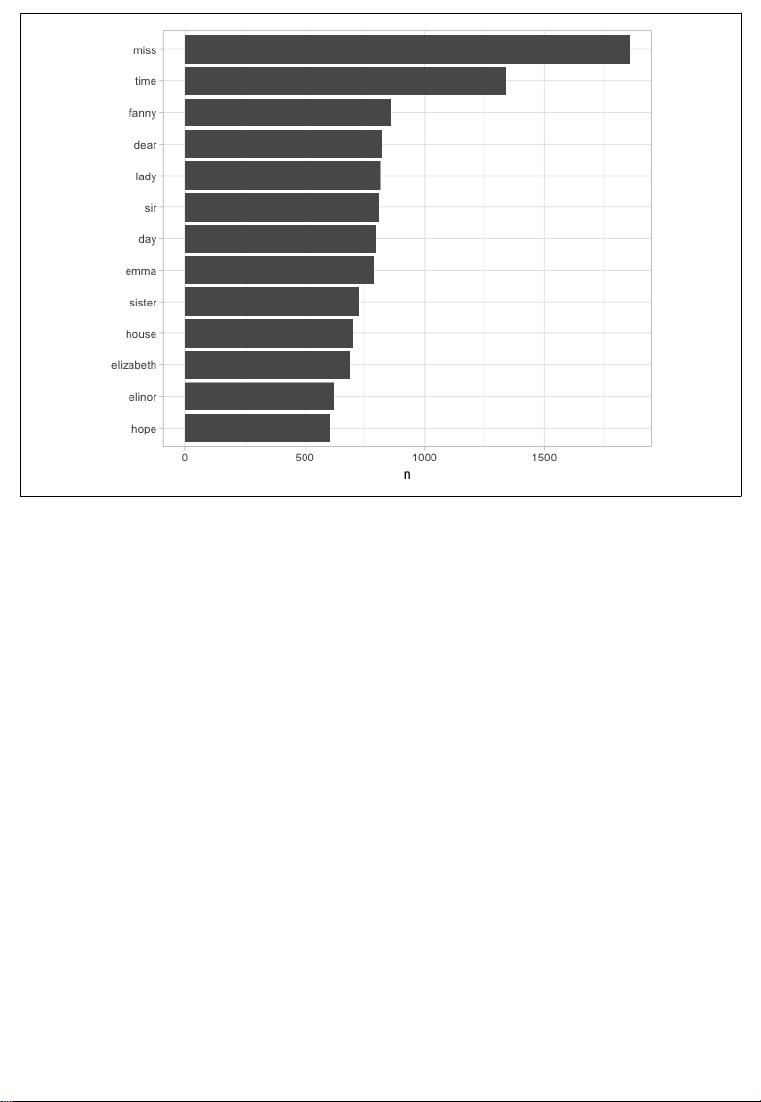
## # A tibble: 13,914 × 2
## word n
## <chr> <int>
## 1 miss 1855
## 2 time 1337
## 3 fanny 862
## 4 dear 822
## 5 lady 817
## 6 sir 806
## 7 day 797
## 8 emma 787
## 9 sister 727
## 10 house 699
## # ... with 13,904 more rows
Because we’ve been using tidy tools, our word counts are stored in a tidy data frame.
This allows us to pipe directly to the ggplot2 package, for example to create a visuali‐
zation of the most common words (Figure 1-2).
library(ggplot2)
tidy_books %>%
count(word, sort = TRUE) %>%
filter(n > 600) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n)) +
geom_col() +
xlab(NULL) +
coord_flip()
6 | Chapter 1: The Tidy Text Format


剩余183页未读,继续阅读
2018-03-16 上传
2021-10-03 上传
2021-02-05 上传
2022-07-14 上传
2021-08-21 上传
2021-04-16 上传
2017-12-02 上传
2021-08-31 上传
2020-03-28 上传

chenheng1114
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
