城市交通分析的计算机视觉技术综述
"这篇论文是关于计算机视觉技术在城市交通分析中的应用的综合评论,重点关注了当前的技术状态、挑战和未来研究方向。随着硬件成本的降低和监控摄像头部署的增加,视频分析在智能交通系统(ITS)中的角色日益重要。文章讨论了如何利用这些摄像头进行交通拥堵、交通违规和车辆交互等的监测。尽管高速公路车辆检测和分类已有经典视觉监控技术,如背景估计和运动跟踪,但城市环境因其高密度交通、大量遮挡和多样化的道路使用者而更具挑战性。因此,来自对象分类和3D建模的方法激发了更先进的技术来应对这些挑战。然而,缺乏统一的数据集或基准测试使得算法之间的直接比较变得困难,同时,对于恶劣天气条件下的评估也亟待加强。未来的努力应该集中在开发适用于所有道路使用者的鲁棒联合检测器和分类器,并在现实条件下进行评估。"
这篇文章详细阐述了计算机视觉在城市交通分析中的应用,主要包括以下几个知识点:
1. 自动视频分析:城市监控摄像头的自动分析技术基于计算机视觉,是近年来快速发展的一个领域。这种技术可以实时处理和理解交通场景,从而实现智能化的交通管理。
2. 智能交通系统(ITS):计算机视觉技术对ITS的发展至关重要,因为它可以提供实时的交通信息,帮助预测和解决交通问题,如拥堵、事故预防和交通规则执行。
3. 背景估计和运动跟踪:这些是传统的视觉监控技术,常用于高速公路的车辆检测和分类。通过估计背景并追踪移动物体,可以识别出道路上的车辆。
4. 城市环境的挑战:与高速公路相比,城市环境的交通密度更高,相机角度较低,导致遮挡情况严重,且道路使用者多样化,这些因素都对计算机视觉技术提出了更高的要求。
5. 对象分类和3D建模:这些先进技术用于应对城市环境中的挑战,通过识别不同类型的物体(如行人、自行车、汽车等)和构建3D模型,提高分析的准确性和鲁棒性。
6. 缺乏统一数据集和基准:目前,没有广泛接受的数据集或标准测试来评估算法性能,这使得技术对比和进步受到限制。
7. 复杂环境下的评估:尽管实时分析是关键,但在恶劣天气(如雨、雾、黑暗)条件下的系统性能评估相对较少,这是未来研究的重要方向。
8. 未来研究方向:未来的研究应集中在开发能够适应各种道路用户和复杂环境的鲁棒检测和分类算法,并在实际环境中进行验证,以提高系统的实用性和可靠性。
这篇论文提供了计算机视觉技术在城市交通分析领域的全面概述,强调了现有挑战和未来研究的重点,对于该领域的研究者和技术开发者具有重要参考价值。
BUCH et al.: REVIEW OF COMPUTER VISION TECHNIQUES FOR ANALYSIS OF URBAN TRAFFIC 923
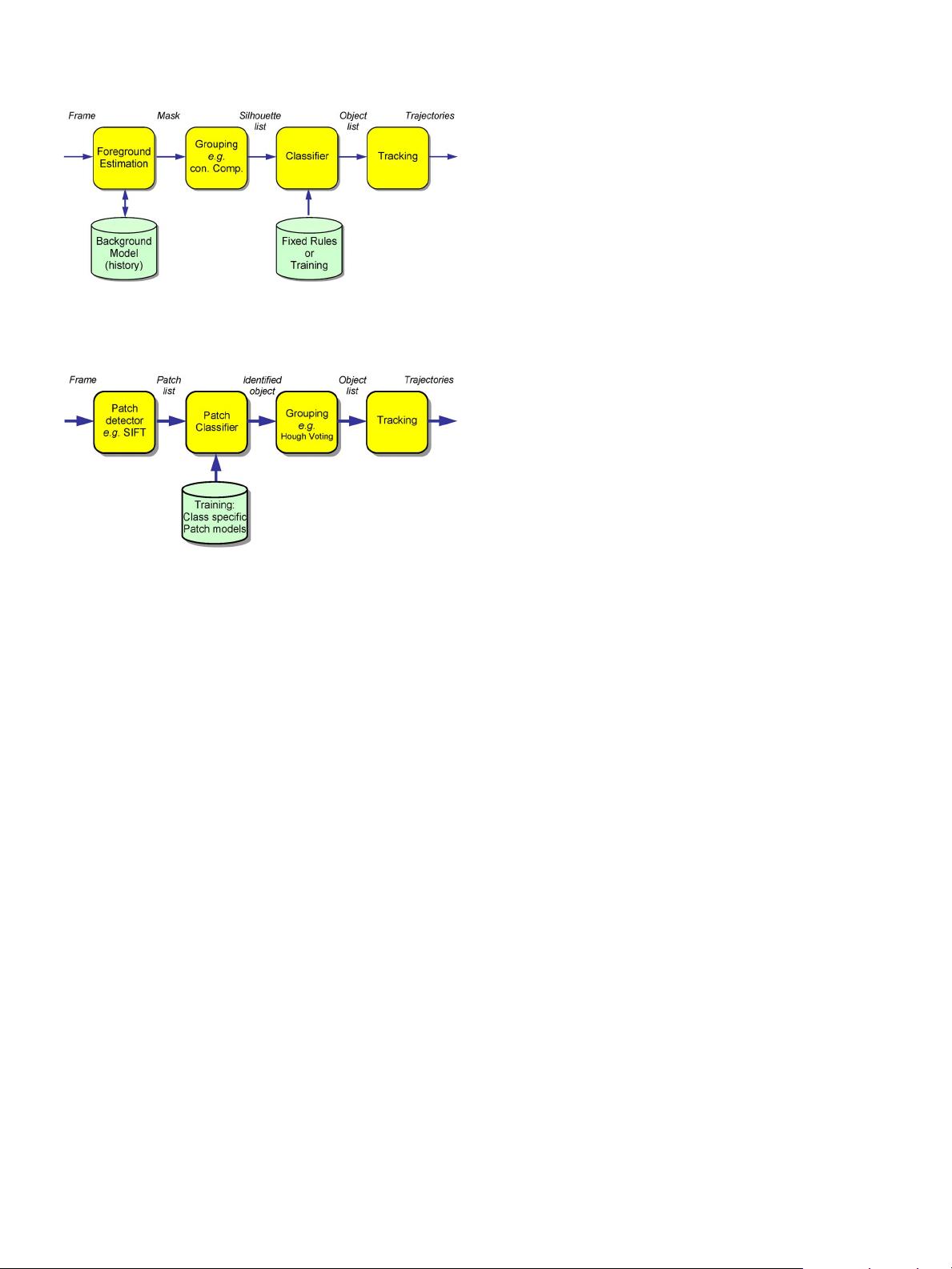
Fig. 2. Block diagram for a top–down surveillance system. The grouping of
pixels in the foreground mask into silhouettes that represent objects is done
early with a simple algorithm without knowledge of object classes.
Fig. 3. Block diagram for a bottom–up surveillance system. Local image
patches are first extracted from the input image and classified as a specific
part of a trained object class. The identified parts are combined into objects
based on the class through a grouping or voting process. Advanced tracking
concepts [83] allow this grouping to be performed in the spatial–temporal
domain, which directly produces an object trajectory rather than frame-per-
frame object detections.
the processing pipeline of a typical video analytics application:
foreground estimation (see Section III-A), classification (see
Section III-B), and tracking (see Section III-D). See Fig. 2
for a block diagram. A statistical model typically estimates
foreground pixels, which are then grouped with a basic model
(e.g., connected regions) and propagated through the system
until the classification stage; for example, see [14], [21], [29],
[45], [51], [56], and [98]. Classification then uses prior infor-
mation (previously learned or preprogrammed) about the object
classes to assign a class label. For the remainder of this paper,
we will refer to this class of algorithms as “top–down” or
“object based,” because pixels are grouped into objects early
during the processing.
In contrast, we define a “bottom–up” approach as an ap-
proach that first detects and classifies parts of an object (see
Fig. 3). This initial classification of the parts uses learned prior
information (e.g., training) about the final object classes (e.g.,
an image area is classified to be a car wheel or a pedestrian
head based on previously learned appearances of wheels and
heads). The combination of these parts into valid objects and
trajectories is the final step of the algorithm; for example, see
[83], [85], and [104]. This type of approach is typically used in
generic object recognition.
In the next section, we will first describe the top–down
approach in more detail, including foreground segmentation
and top–down vehicle classification. This approach is followed
by relevant bottom–up classification approaches for traffic
surveillance. The last section considers tracking, which can
equally be applied after both classification methods.
A. Foreground Segmentation
Foreground estimation and segmentation is the first stage of
several visual surveillance systems. The f oreground regions are
marked (e.g., mask image) for processing in the subsequent
steps. The foreground is defined as every object, which is
not a fixed furniture of a scene, where fixed could normally
mean months or years. This definition conforms to human
understanding, but it is difficult to algorithmically implement.
There are two main different approaches to estimate the fore-
ground, which both use strong assumptions to comply with the
aforementioned definition. First, a background model of some
kind can be used to accumulate information about the s cene
background of a video sequence. The model is then compared
to the current frame to identify differences (or “motion”),
provided that the camera is stationary. This concept lends itself
well for computer implementation but leads to problems with
slow-moving traffic. Any car should be considered foreground,
but stationary objects are missed due to the lack of motion. The
next five sections discus different solutions for using motion as
the main cue for foreground segmentation.
A different approach performs segmentation based on whole
object appearances and will be discussed in Section VI. This
approach can be used for moving and for stationary cameras but
requires prior information f or foreground object appearances.
This way, the review moves from the simple frame differ-
ence method in the next section to learning based methods in
Section VI.
1) Frame Differencing: Possibly, the simplest method for
foreground segmentation is frame differencing. A pixel-by-
pixel difference map is computed between two consecutive
frames. This difference is thresholded and used as the fore-
ground mask. This algorithm is very fast; however, it can-
not cope with noise, abrupt illumination changes, or periodic
movements in the background such as trees. In [110], frame
differencing is used to detect street-parking vehicles. Special
care is taken in the algorithm to suppress the influence of noise.
Motorcycles are detected in [102] based on frame differencing.
However, using more information than only the last frame for
subtraction is preferable. This approach leads to the background
subtraction techniques described in the next sections.
2) Background Subtraction: This group of background
models estimates a background image (i.e., fixed scene), which
is subtracted from the current video frame. A threshold is
applied to the resulting difference image to give the foreground
mask. The threshold can be constant or dynamic, as used in
[51]. The following methods differ in the way the background
picture is obtained, resulting in different levels of image quality
for different levels of computational complexity.
a) Averaging: In the background averaging method, all
video frames are summed up. The learning rate specifies the
weight between a new frame and the background. This al-
gorithm has little computational cost; however, it is likely to
produce tails behind moving objects due to the contamination
of the background with the appearance of the moving objects.
剩余19页未读,继续阅读
2020-04-13 上传
2009-01-18 上传
2015-04-23 上传
2021-09-23 上传
2021-09-25 上传
2021-09-23 上传
2021-01-06 上传
2021-02-11 上传

O天涯海阁O
- 粉丝: 1553
- 资源: 90
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
