TensorFlow 2.0.4快速构建与训练模型指南
需积分: 8 5 浏览量
更新于2024-07-09
收藏 1.17MB PDF 举报
本章节深入探讨了在TensorFlow 2.0.4 beta 版本中如何利用Keras高效地建立和训练模型。首先,对于理解和操作TensorFlow模型,你需要具备一定的Python面向对象编程基础,包括类和方法的定义、继承机制、构造函数和析构函数,以及如何使用`super()`函数调用父类方法。此外,理解多层感知机、卷积神经网络(CNN)、循环神经网络(RNN)和强化学习的基本原理也是必不可少的。
Keras是TensorFlow的重要组件,作为高级神经网络API,它简化了模型构建过程,提供了易用性和灵活性。Keras模型的核心概念是模型(Model)和层(Layer)。模型是计算图的抽象,它将输入数据通过一系列层进行处理,形成预测输出。层则是计算单元,封装了特定的数学运算和参数,如全连接层、卷积层和池化层。
在Keras中,模型通常是以类的形式实现,通过继承`tf.keras.Model`基类创建自定义模型。`__init__`方法作为构造函数,用于初始化模型参数和层,而`call(input)`方法则定义了模型的实际计算流程。例如,一个简单的自定义模型可能包含以下步骤:
```python
class MyModel(tf.keras.Model):
def __init__(self):
super(MyModel, self).__init__()
# 初始化层
self.layer1 = Dense(units=64) # 假设这是全连接层
self.layer2 = Conv2D(filters=32, kernel_size=(3, 3)) # 假设这是卷积层
def call(self, inputs):
x = self.layer1(inputs)
x = self.layer2(x)
# 其他可能的层和操作...
return x
```
模型的训练涉及到设置损失函数(`tf.keras.losses`,如均方误差或交叉熵)、优化器(`tf.keras.optimizers`,如SGD、Adam等)以及评估指标(`tf.keras.metrics`,如准确率、精度等)。整个流程可以概括为:
1. 模型构建:使用`tf.keras.Sequential`或自定义类构建模型,定义输入和输出维度。
2. 设置损失函数:根据问题类型选择适当的损失函数,例如`model.compile(loss='binary_crossentropy', optimizer='adam')`。
3. 数据预处理:加载和准备训练数据,可能涉及标准化、归一化等步骤。
4. 模型编译:配置模型进行训练,指定优化器、损失函数和可能的额外回调函数。
5. 训练:使用`model.fit(x_train, y_train, epochs=10, validation_data=(x_val, y_val))`进行训练。
6. 评估:使用`model.evaluate(x_test, y_test)`或`model.predict(x_test)`评估模型性能。
理解这些概念并结合实际案例操作,你可以快速上手TensorFlow 2.0.4的模型建立和训练过程,从而有效地构建和优化深度学习模型。
−
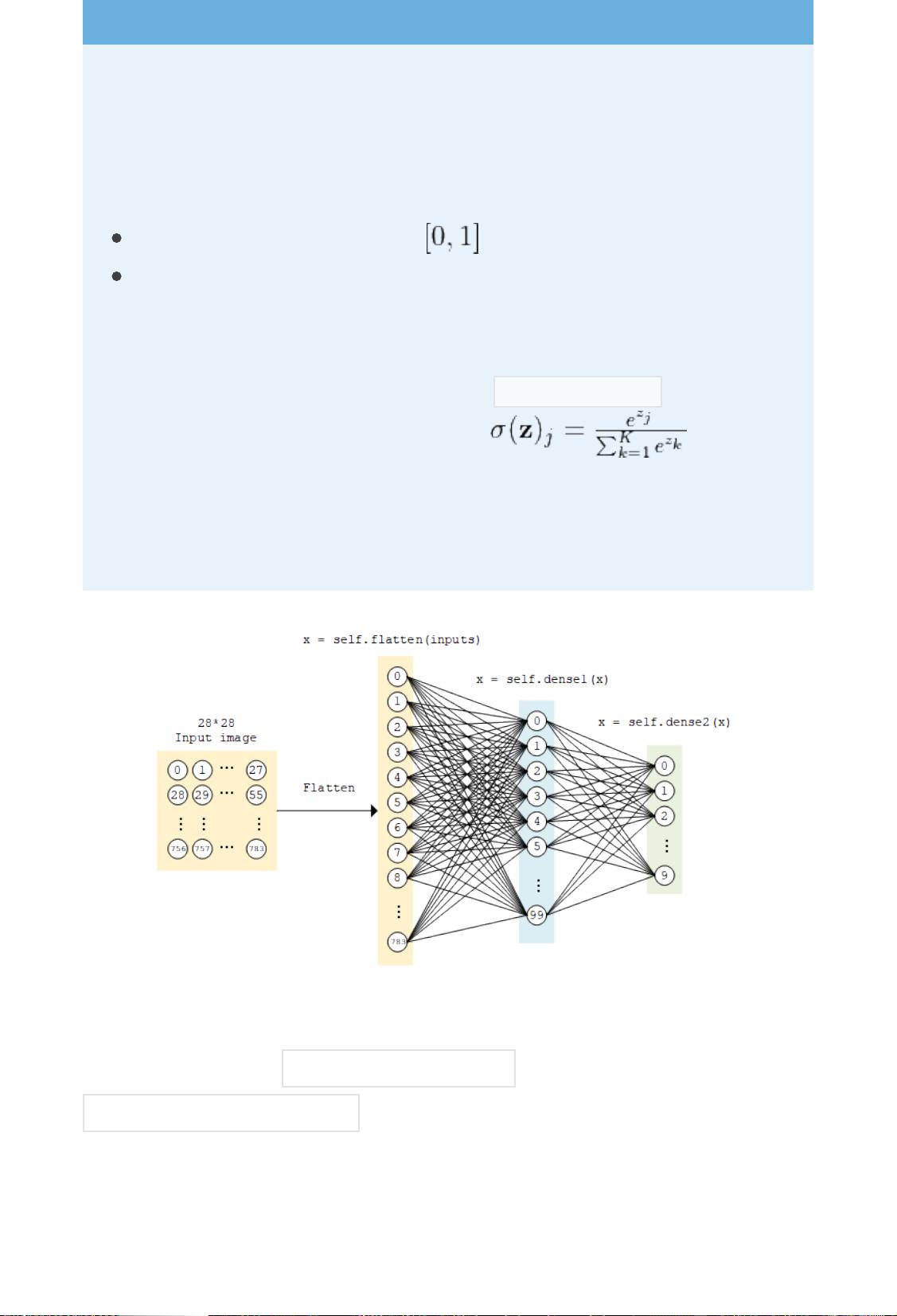
! TensorFlow 的图像数据表示
在 TensorFlow 中,图像数据集的⼀种典型表示是
[图像数⽬,⻓,宽,⾊彩通道数] 的四维张量。在上⾯的
DataLoader 类中, self.train_data 和 self.test_data 分别
载⼊了 60,000 和 10,000 张⼤⼩为 28*28 的⼿写体数字图
⽚。由于这⾥读⼊的是灰度图⽚,⾊彩通道数为 1(彩⾊ RGB
图像⾊彩通道数为 3),所以我们使⽤ np.expand_dims() 函
数为图像数据⼿动在最后添加⼀维通道。
模型的构建: tf.keras.Model 和 tf.keras.layers
多层感知机的模型类实现与上⾯的线性模型类似,使⽤
tf.keras.Model 和 tf.keras.layers 构建,所不同的地⽅在于层
数增加了(顾名思义,“多层” 感知机),以及引⼊了⾮线性激活
函数(这⾥使⽤了 ReLU 函数 , 即下⽅的
activation=tf.nn.relu )。该模型输⼊⼀个向量(⽐如这⾥是拉
直的 1×784 ⼿写体数字图⽚),输出 10 维的向量,分别代表这
张图⽚属于 0 到 9 的概率。
class MLP(tf.keras.Model):
def __init__(self):
super().__init__()
self.flatten = tf.keras.layers.Flatten() #
Flatten
层将除第⼀维(
batch_size
)以外的维度展平
self.dense1 = tf.keras.layers.Dense(units=100,
activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs): # [batch_size, 28, 28,
1]
x = self.flatten(inputs) # [batch_size, 784]
x = self.dense1(x) # [batch_size, 100]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
剩余46页未读,继续阅读
153 浏览量
2021-10-30 上传
107 浏览量
2021-10-30 上传
125 浏览量
2021-10-30 上传
109 浏览量
110 浏览量
165 浏览量

山居秋暝LS
- 粉丝: 201
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网络电视压缩包内容解析
- Verilog实现贪吃蛇游戏的FPGA源码解析
- iOS PanCardView动画拖动效果实现教程
- Eclipse插件spket-1.6.23实现JS和JQuery代码提示功能
- Angular自定义组合框指令及模糊搜索功能介绍
- C#实现Textbox智能提示功能指南
- STM32MP157单通道ADC采集DMA读取HAL库驱动程序
- 将Woz的SWEET16 16位处理器移植至C64的Kick汇编程序
- MATLAB时频分析工具箱TFTB-0.2使用教程
- Netty实例5.0:全面解析IO通信框架及其应用
- 基于51单片机的16按键计算器设计与实现
- iOS开发中MBProgressHUD网络加载视图的应用
- STM32MP157 HAL库驱动PCF8563实时时钟程序教程
- 淘宝卖家不可或缺的钻展教程指南
- librender渲染器: C++实现的单对象渲染技术
- 安卓设备USB驱动安装与更新教程
