深度学习驱动的图像与视频压缩技术
下载需积分: 12 | PDF格式 | 9.4MB |
更新于2024-07-15
| 83 浏览量 | 举报
"VCIP_Tutorial.pdf - 2020 IEEE International Conference on Visual Communications and Image Processing (VCIP) 演讲文档,探讨了利用深度神经网络进行图像和视频压缩的技术,由多位专家共同撰写,包括来自悉尼大学、北京理工大学和瑞士苏黎世联邦理工学院的研究者。"
在当今数字化时代,图像和视频数据的生成量巨大,但终端设备的带宽和存储空间有限。例如,一个7296x5472像素的未经压缩图像就需要约120MB的存储空间,而如果以60帧每秒的速度播放,不压缩的视频仅18秒就需要128GB的存储。这突显了图像/视频压缩的重要性,它在多媒体流媒体、在线会议和数据存储等领域扮演着关键角色。
传统的图像压缩如PNG(无损)和JPEG(有损)已经在一定程度上解决了这个问题,但随着深度学习的发展,学者们开始探索更先进的方法,即深度神经网络(DNNs)在图像和视频压缩中的应用。这部分教程的第一部分专注于学习型图像压缩。
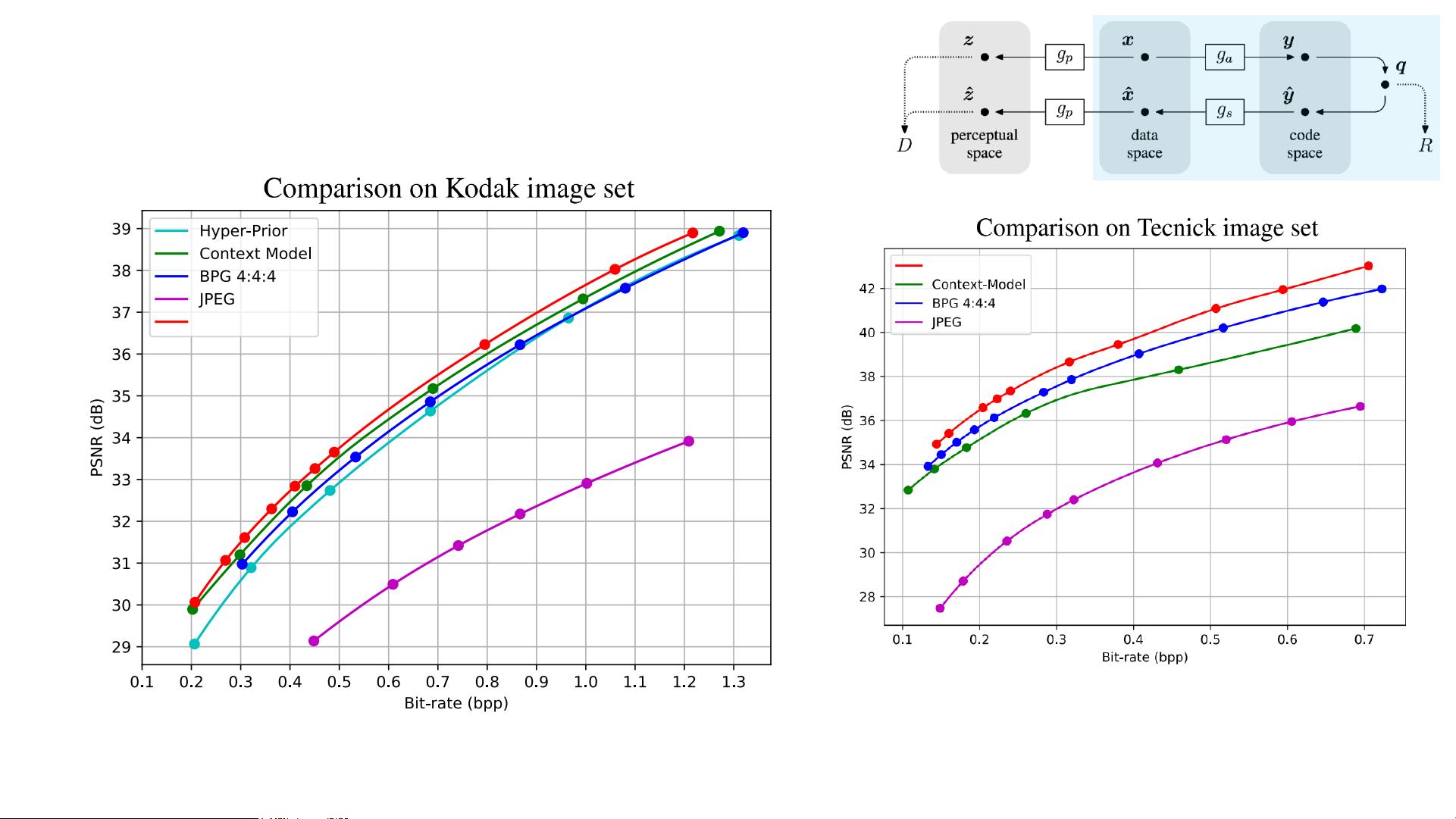
深度学习驱动的图像压缩方法通过训练神经网络模型来实现率失真优化(Rate-Distortion Optimization),即在保持一定图像质量的同时,尽可能地减少文件大小。这种技术能实现比传统方法更高效的压缩比率,同时还能处理高分辨率的图像和视频。
论文中提到的“率-失真”权衡是压缩理论的核心概念。更高的比特率意味着更大的文件大小,但可以提供更好的图像质量(更低的失真)。相反,降低比特率可以减小文件尺寸,但可能会牺牲一定的质量。DNNs在这一领域提供了一种新的平衡方式,能够自适应地学习如何以最小的失真来压缩数据。
通过这种方式,深度学习不仅能够捕获图像的复杂视觉特性,还能在编码和解码过程中减少信息损失。这些技术的应用可以显著提升压缩效率,尤其在实时流媒体和移动通信等对带宽需求敏感的场景下,具有巨大的潜力。
这篇VCIP教程深入介绍了深度神经网络如何革新图像和视频压缩的领域,展示了未来多媒体数据处理的新方向。通过理解和应用这些先进技术,我们可以期待更加高效、高质量的多媒体体验。
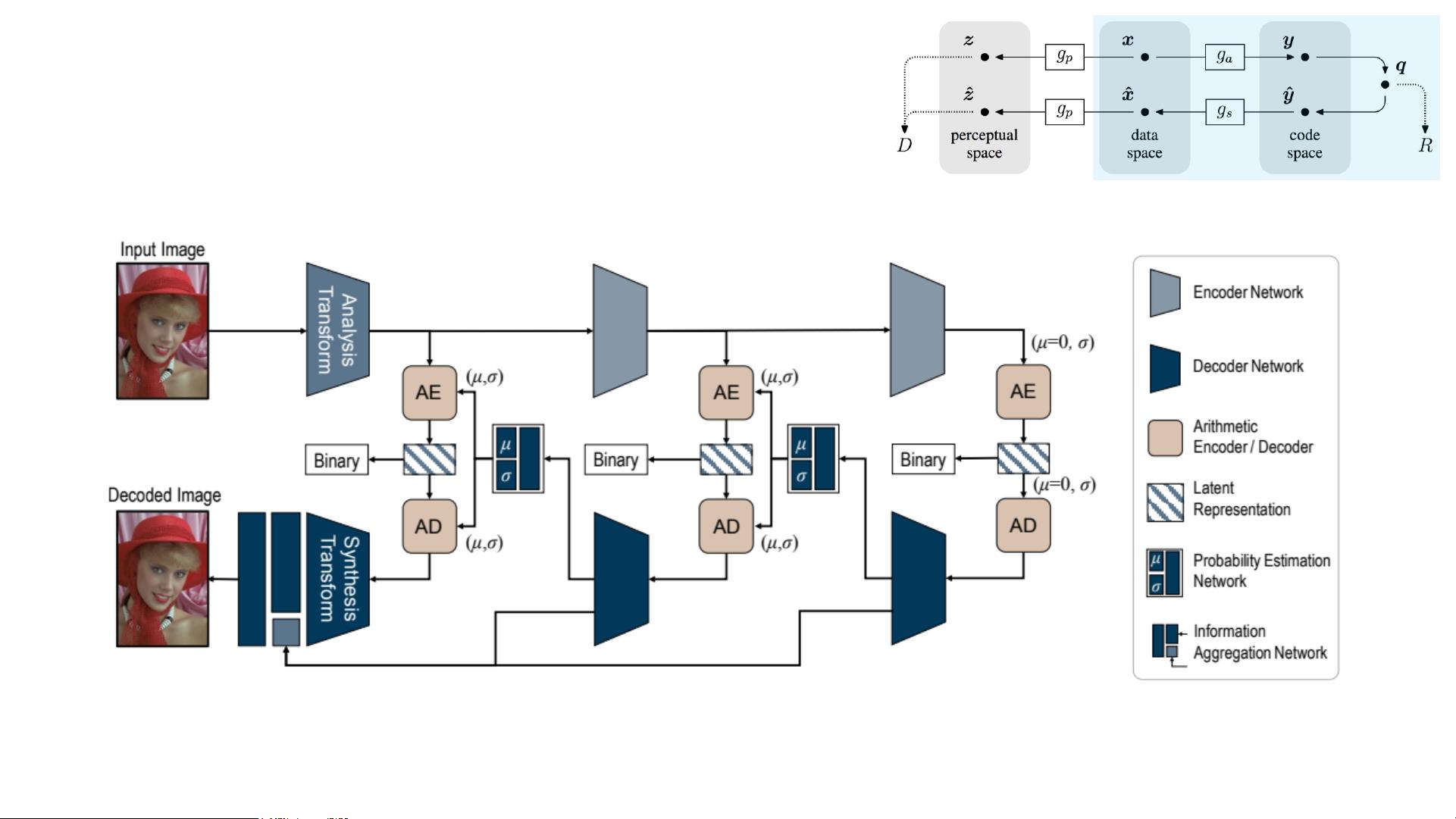
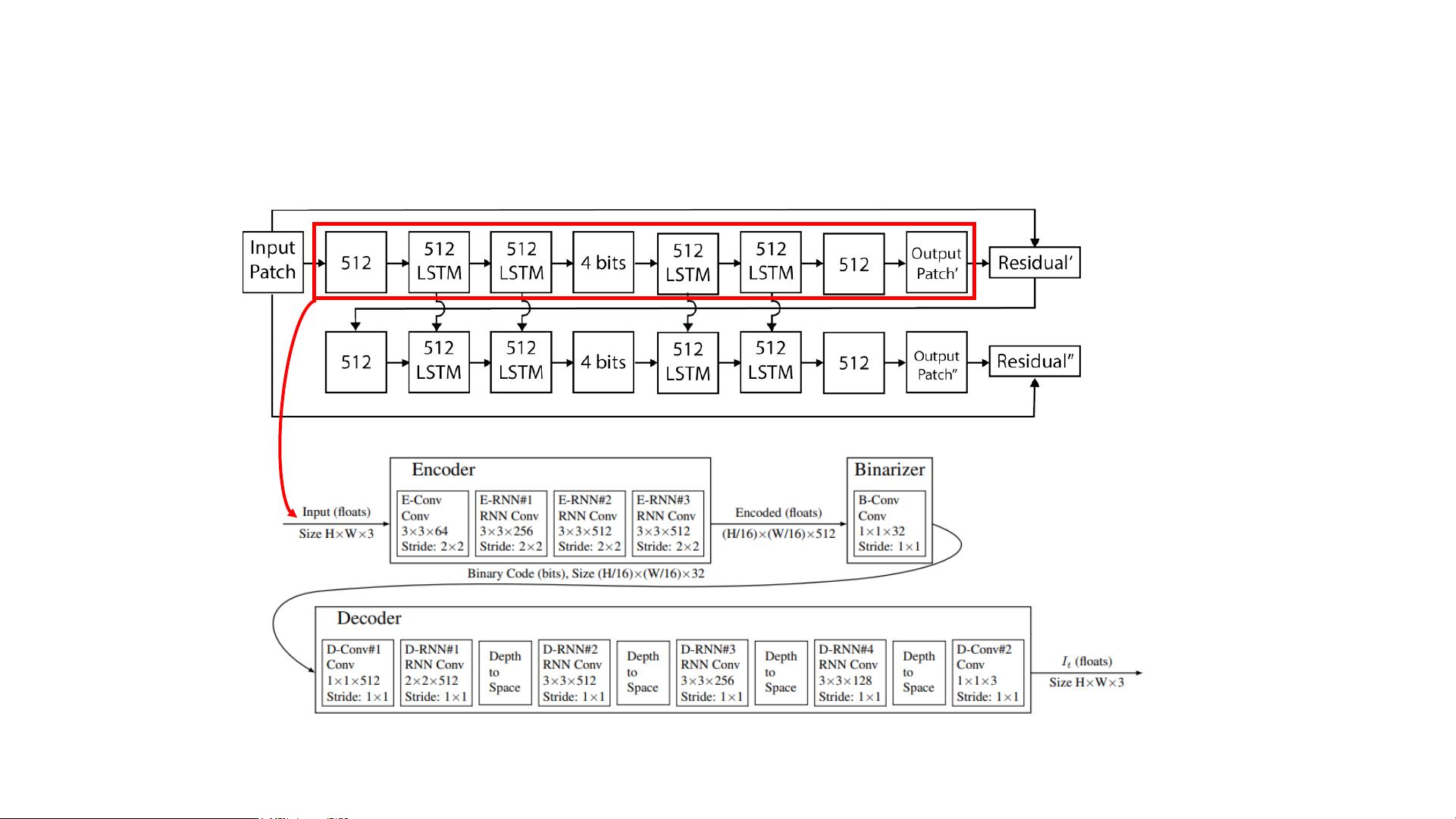
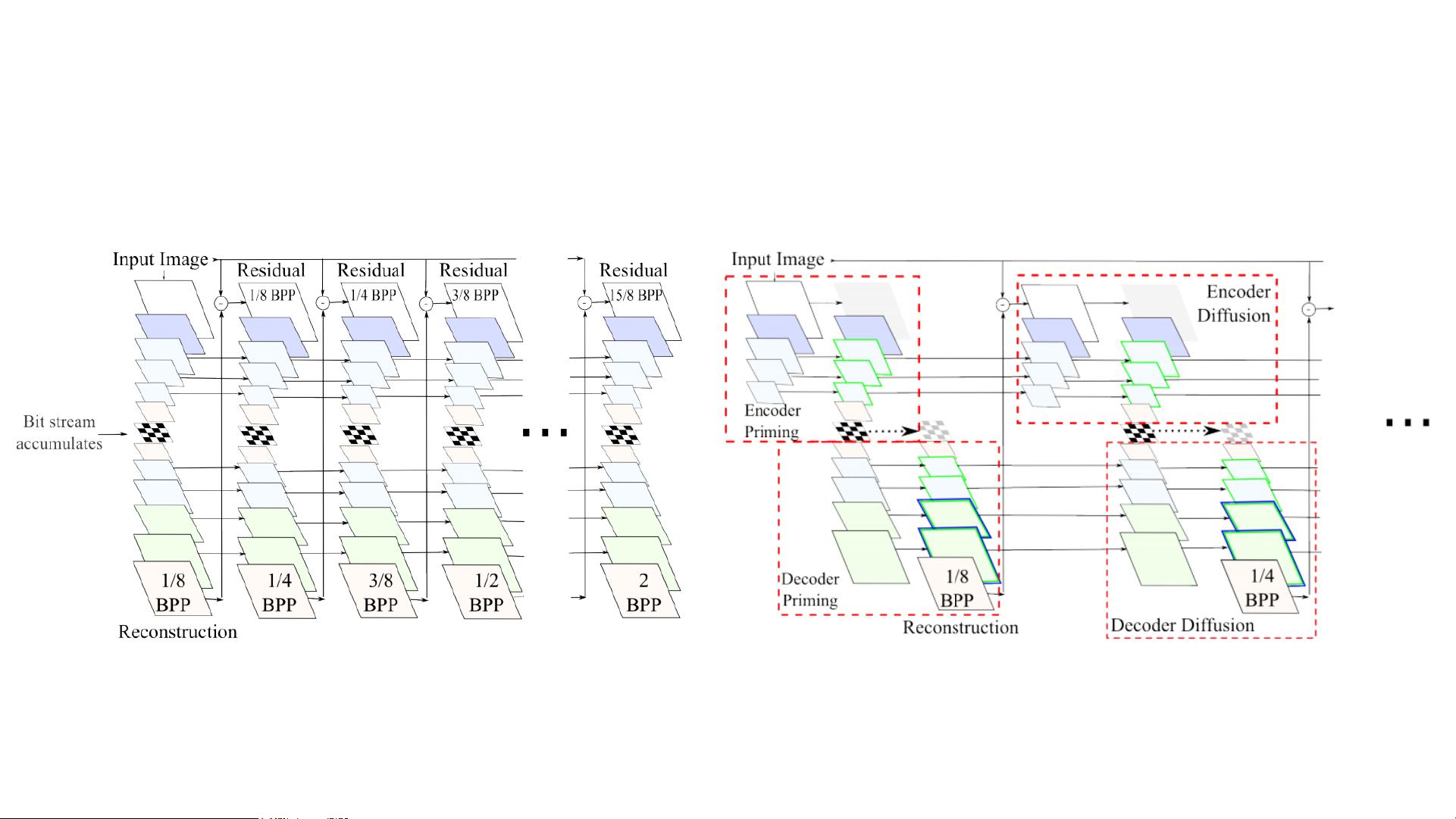
Learned Image Compression
• CNN transformer + coarse-to-fine model
[7]
[7] Hu, Yueyu, et al. "Coarse-to-Fine Hyper-Prior Modeling for Learned Image Compression." in AAAI. 2020.
剩余88页未读,继续阅读
相关推荐



FnYI
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- ITween插件实用教程:路径运动与应用案例
- React三纤维动态渐变背景应用程序开发指南
- 使用Office组件实现WinForm下Word文档合并功能
- RS232串口驱动:Z-TEK转接头兼容性验证
- 昆仑通态MCGS西门子CP443-1以太网驱动详解
- 同步流密码实验研究报告与实现分析
- Android高级应用开发教程与实践案例解析
- 深入解读ISO-26262汽车电子功能安全国标版
- Udemy Rails课程实践:开发财务跟踪器应用
- BIG-IP LTM配置详解及虚拟服务器管理手册
- BB FlashBack Pro 2.7.6软件深度体验分享
- Java版Google Map Api调用样例程序演示
- 探索设计工具与材料弹性特性:模量与泊松比
- JAGS-PHP:一款PHP实现的Gemini协议服务器
- 自定义线性布局WidgetDemo简易教程
- 奥迪A5双门轿跑SolidWorks模型下载
