大数据处理技术演进:从Hadoop到Storm实时架构
需积分: 18 153 浏览量
更新于2024-08-24
收藏 1.38MB PDF 举报
"大数据处理技术架构的演进"
大数据处理技术随着互联网应用的发展经历了显著的变化,尤其是对于实时性需求的提升。本文主要讨论了Hadoop离线处理架构的局限性和Storm实时处理架构的优势,以及在实际项目中如何进行架构的转变以满足实时业务需求。
Hadoop是大数据处理领域的里程碑,它基于GFS和MapReduce的理念,通过分布式计算解决了大规模数据处理的问题。Hadoop架构的核心是HDFS和MapReduce。HDFS是一个主从结构的文件系统,NameNode作为主节点管理文件系统的元数据,而Datanodes则存储实际的数据块。这种设计使得Hadoop能处理PB级别的数据,但其批量处理的特性导致在实时性方面存在不足。
随着Web2.0时代的到来,如微博等应用的出现,对数据处理的实时性提出了更高的要求。Hadoop在处理这些实时需求时表现出明显的瓶颈,主要体现在以下几个方面:
1. 批量处理:Hadoop的计算模型是基于批量数据输入和输出的,这使得它无法快速响应实时查询或流式数据处理。
2. 延迟问题:由于Hadoop需要等待数据完全收集并进行批量处理,因此在处理时间敏感的业务时,延迟问题尤为突出。
3. 效率限制:在数据更新频繁的场景下,Hadoop需要频繁地重读和重写数据,这降低了处理效率。
为解决这些问题,Twitter开发了Storm实时处理框架。Storm采用流式处理模式,能够持续处理无界数据流,提供低延迟的实时计算。与Hadoop不同,Storm处理数据是连续不断的,一旦数据到达,就会立即进行处理,无需等待数据集的完整收集。
在实施架构变更过程中,关键的技术包括:
1. 数据迁移:从Hadoop迁移到Storm可能涉及到大量数据的迁移,需要考虑数据的完整性和一致性。
2. 流处理设计:在Storm中,需要重新设计数据处理流程,确保实时性和准确性。
3. 性能优化:针对实时处理,需要对系统进行性能调优,如减少延迟、提高吞吐量等。
4. 故障恢复:实时系统需要强大的容错机制,确保在节点故障时仍能保持服务的连续性。
通过实验验证,采用Storm实时处理架构可以有效提高大数据处理的实时性,满足业务需求。然而,选择合适的架构取决于具体业务场景,例如,对于历史数据分析或离线任务,Hadoop仍然是一个高效的选择。
大数据处理技术架构的演进反映了技术对业务需求的适应性变化。从Hadoop的离线处理到Storm的实时处理,不仅揭示了技术的进步,也体现了对数据处理实时性追求的不断提升。随着技术的不断演进,未来可能会有更多适应各种业务场景的处理架构出现,以满足多样化的数据处理需求。
Research & DeveIopment
47
Hadoop诞生于大数据时代
,
是Apache基金会受
到Google开发的GFS(Google File System
,
谷歌文件
系统)和MapReduce计算框架的启发引入的开源项目
。
Hadoop使用大量的廉价Linux PC机组成集群
,
可谓是
大数据处理商用技术架构的开端
。
Hadoop作为经典的
大数据离线处理技术架构
,
很好地满足了人们对于大数
据的离线处理需求
[1]
。
然而
,
随着Web2.0的兴起
,
琳琅满目的各式应用
和服务如雨后春笋般地涌现
。
这其中出现了以微博为代
表的一批典型应用
,
海量的用户
、
碎片化的信息流
、
极快的传播速度
,
使得它们对业务实时性的要求大幅
度提高
[2]
。
当业务需求允许的时延降低到一定限度时
,
Hadoop架构会达到本身的瓶颈
,
已经不能满足大数据
处理的需求
。
Twitter出于自身的业务需求开发了Storm
实时处理框架
,
使用流式处理架构
,
对传统离线处理技
术架构进行了变革
。
Hadoop是优秀的大数据离线处理技术架构
,
主要
采用的思想是
“
分而治之
”,
对大规模数据的计算进行
分解
,
然后交由众多的计算节点分别完成
,
再统一汇总
计算结果
[3]
。
Hadoop架构通常的使用方式为批量收集
输入数据
,
批量计算
,
然后批量吐出计算结果
。
然而
,
Hadoop结构在处理实时性要求较高的业务时
,
却显得
力不从心
。
本章内容对Hadoop架构这种瓶颈的产生原
因进行了探究
。
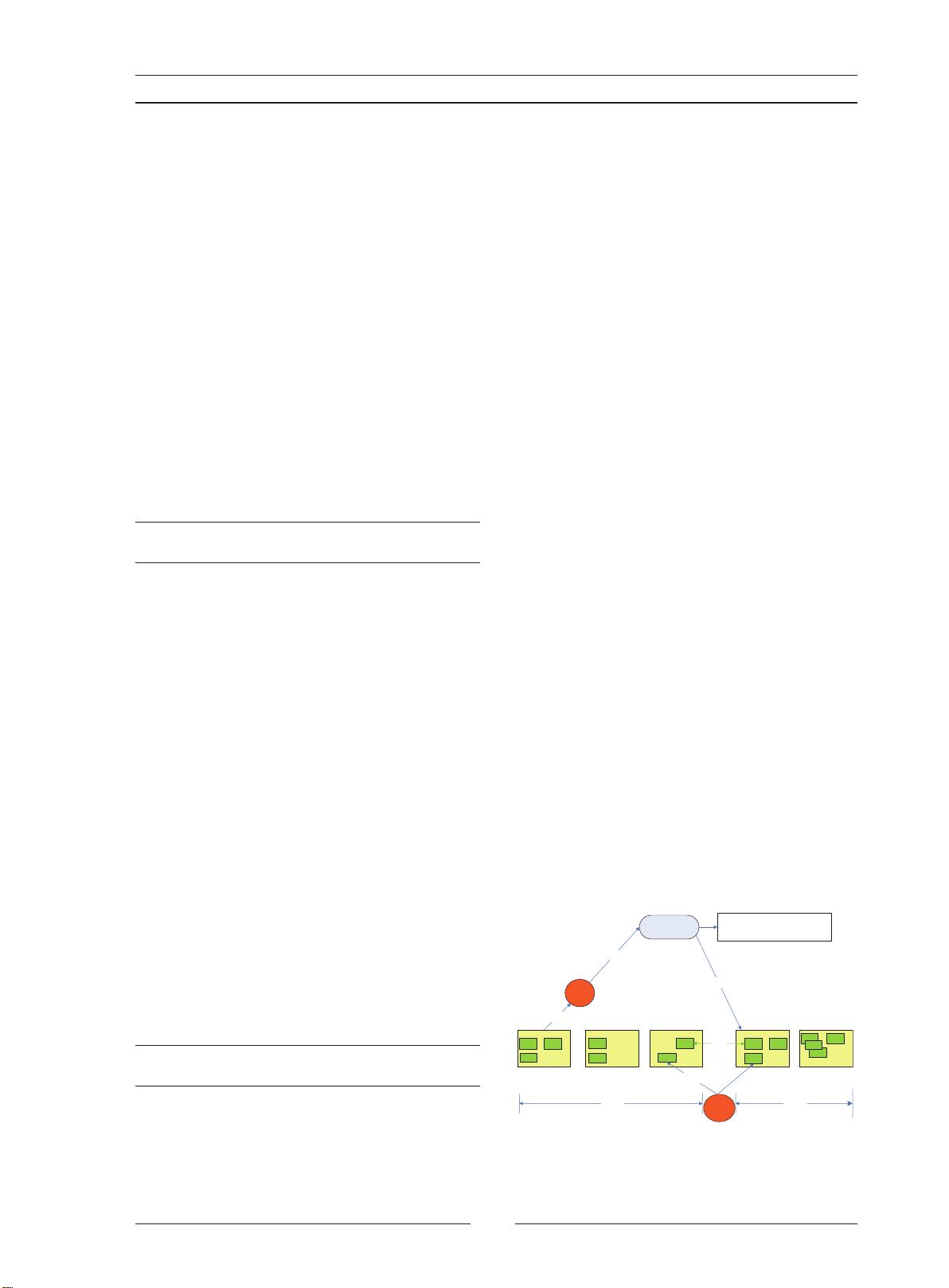
Hadoop架构的核心组成部分是HDFS(Hadoop
Distributed File System
,
Hadoop分布式文件系统)和
MapReduce分布式计算框架
。
HDFS采用Master/Slave
体系结构
,
在集群中由一个主节点充当NameNode
,
负责文件系统元数据的管理
,
其它多个子节点充当
Datanode
,
负责存储实际的数据块
[4]
。
如图1所示
。
名字节点
元数据(名字,备份,…,):
/home/foo/data,3,…
客户端
客户端
读操作
数据节点
元数据
块
数据节点
块
复制
写操作
机架1 机架2
浅谈大数据处理技术架构的演进
1 北京邮电大学网络与交换技术国家重点实验室 北京 100876
2 东信北邮信息技术有限公司 北京 100191
摘 要
关键词
下载后可阅读完整内容,剩余4页未读,立即下载
2021-08-15 上传
2019-04-04 上传
2021-01-27 上传
2021-02-20 上传
2021-01-19 上传
2022-08-04 上传
2021-09-27 上传
2022-06-18 上传
2020-10-26 上传

weixin_38747025
- 粉丝: 129
- 资源: 1108
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
