Python实现低精度模型训练与部署:TensorFlow与TensorRT优化
 已收录资源合集
已收录资源合集
需积分: 0 158 浏览量
更新于2024-07-01
收藏 981KB PDF 举报
本文主要探讨了如何在Python环境下利用TensorFlow和TensorRT进行低精度模型的训练和部署,重点关注了16-bit半精度浮点数(FP16)和8-bit定点数(Int8)在深度学习中的应用。作者张校捷在2019年9月21日撰写了这篇文章,旨在阐述低精度计算在节约内存和显存、硬件加速以及实际应用中的优势。
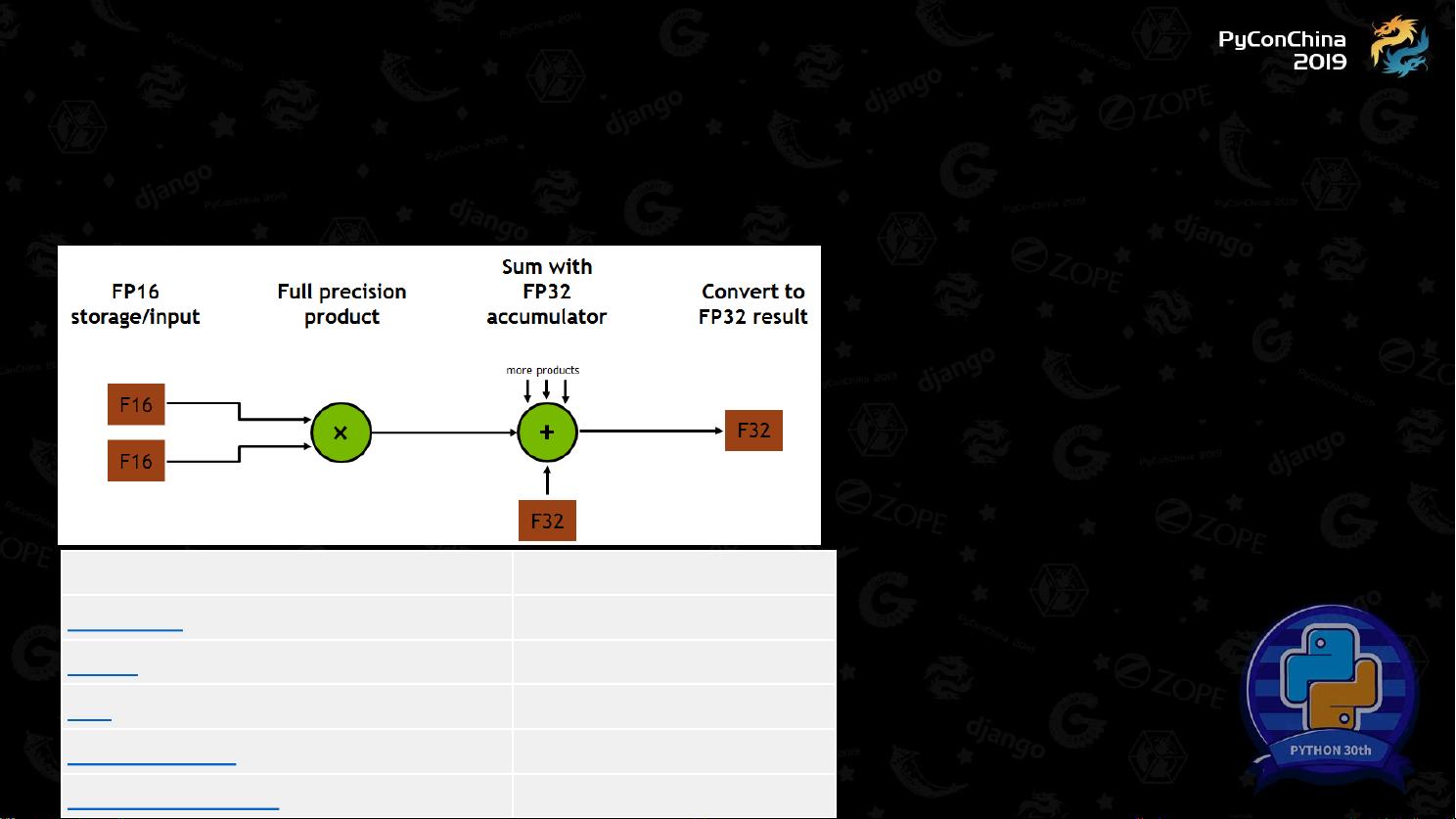
首先,文章介绍了低精度的概念,如16-bit的FP16(E8M7)与FP32(E8M23)的区别,以及8-bit的Int8(通常在TPU和GPU上使用tf.bfloat16)。低精度浮点数的优势在于能显著减少内存需求,例如FP16是FP32占用空间的一半,而Int8则更进一步,节省了一半存储。此外,特定硬件如TensorCore被设计用于加速这些低精度计算,如在卷积(K输入通道和C输出通道)和通用矩阵乘法(GEMM)任务中,它们的性能提升明显。
在TensorFlow中,作者提到如何通过设置环境变量来强制某些层使用FP16(如TF_ENABLE_CUBLAS_TENSOR_OP_MATH_FP32和TF_ENABLE_CUDNN_TENSOR_OP_MATH_FP32等)。例如,创建一个输入占位符并将其转换为FP16类型,然后用`tf.keras.layers.Conv2D`构建一个卷积层时,可以通过指定数据类型为tf.float16来确保其采用低精度运算。
文章还列举了一些实际应用案例,如BERT模型的3.3倍速度提升,GNMT的1.7倍,NCF的2.6倍,以及ResNet-50-v1.5和SSD-RN50-FPN-640模型的速度优化。这些例子展示了在特定任务中,通过低精度模型部署可以带来的性能改善。
对于Int8模型的推断过程,虽然没有详细说明,但可以推测这部分内容可能涉及如何将模型转换为支持Int8计算,并在保持准确性的同时实现更高效的推理。整体来说,这篇文章提供了实用的指导,帮助开发者理解低精度模型的使用方法,选择合适的工具和技术,以及在实际项目中优化模型性能。
剩余23页未读,继续阅读
2023-10-25 上传
2021-05-25 上传
2021-08-09 上传
2021-09-30 上传
2022-03-20 上传
2021-09-30 上传
2024-08-19 上传
2023-04-27 上传
2023-05-10 上传

阿汝娜老师
- 粉丝: 32
- 资源: 309
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
