Python动态网页爬取:解析‘精品图书’模块
版权申诉
"Python网络应用开发-动态网页爬取"
这篇实验报告主要探讨了如何使用Python进行网络应用开发,特别是针对动态网页的爬取。在Python爬虫领域,动态网页的爬取比静态网页更具挑战性,因为它们的内容往往在页面加载后通过JavaScript或者其他异步方式动态生成。
首先,实验中提到的常规爬取方法,即使用`requests`库获取网页内容,对于动态网页来说可能无效。在尝试爬取"http://www.ptpress.com.cn"这个网站时,使用`requests.get()`只能获取到HTML框架,而无法获取到实际展示的内容。这是因为动态网页的内容在原始HTML中并不存在,而是由后续的Ajax请求填充。
为了爬取动态网页的内容,我们需要深入浏览器的开发者工具,查看网络请求。在本例中,学生通过观察"Element"和"Sources",发现网页的"精品图书"模块的数据是通过网络请求获取的。在"Network"面板中,找到了相关的HTTP请求,特别是包含了"精品图书"模块信息的JSON数据。
接着,代码展示了如何模拟这个请求来获取动态内容。使用`requests`库发送GET请求,携带特定的请求头`User-Agent`,确保请求看起来像是来自浏览器。接收到的响应内容是JSON格式,通过`json.loads()`解析成Python字典结构。然后遍历数据,提取出'bookName'和'picPath'等关键信息。
此外,实验还提到了`selenium`库,它是处理动态网页的强大工具。当网页内容依赖用户交互或者JavaScript执行时,`selenium`可以模拟浏览器行为,等待页面完全加载,甚至模拟点击、滚动等操作。虽然在提供的代码中没有详细展示`selenium`的使用,但提到了使用`pip`安装`selenium`作为后续动态爬取的前期准备。
这个实验涵盖了Python网络爬虫的基础知识,包括静态网页的爬取失败、动态网页的识别、利用开发者工具分析网络请求,以及使用`requests`库模拟请求抓取动态内容。同时,也引出了`selenium`这一高级爬虫工具,用于处理更复杂的动态网页抓取场景。这些技能对于Python网络应用开发者和数据抓取者来说至关重要。
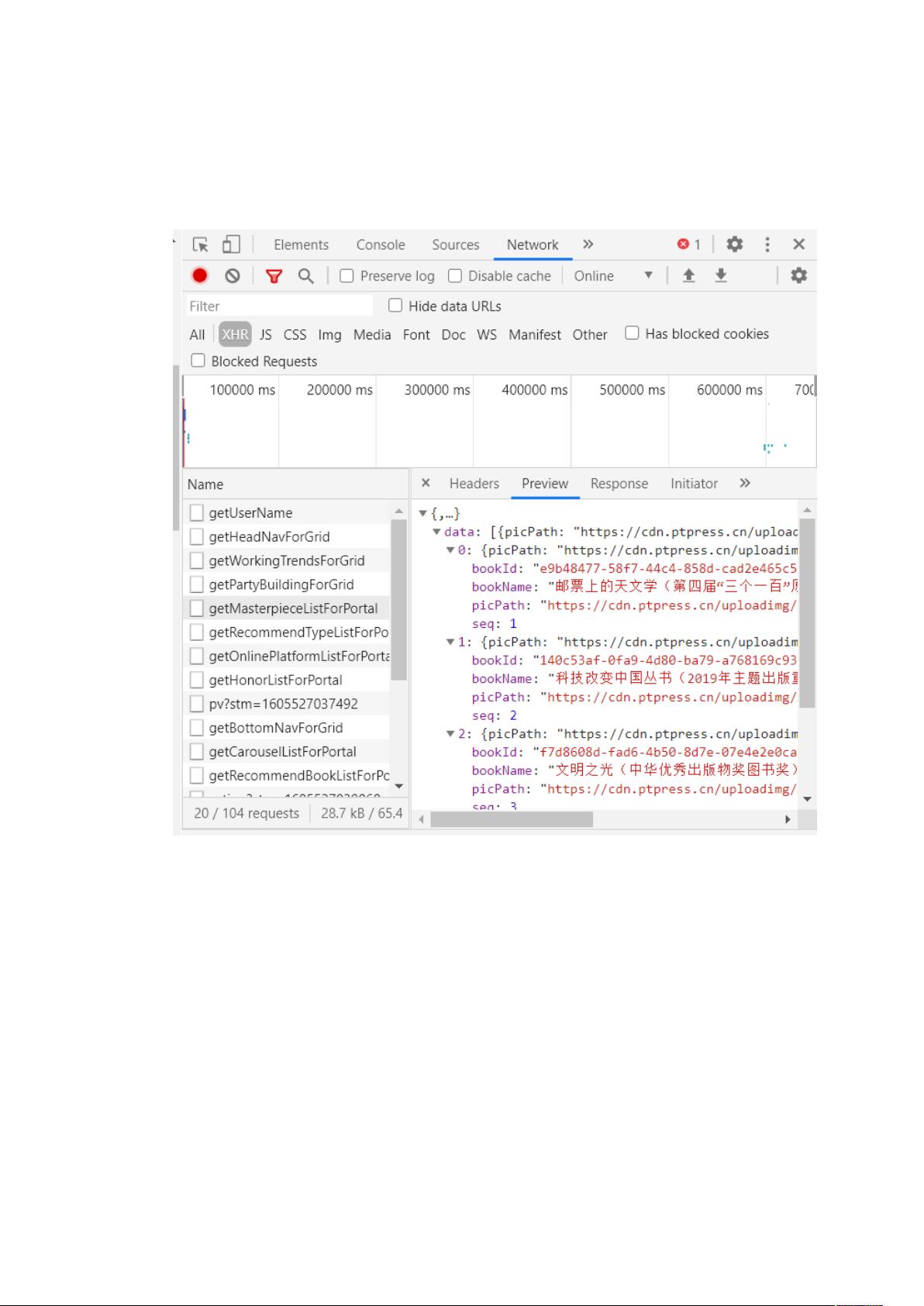
三、 对网页进行分析(以该网页的“精品图书”模块为例)
在开发者工具的 Network 中找到了如下信息:
有内容可知这就是“精品图书”模块的 HTML 信息,分析 Headers,得到
Request URL 以及请求头的 User-Agent
剩余10页未读,继续阅读
1464 浏览量
287 浏览量
2022-07-01 上传
139 浏览量
2022-10-24 上传
2022-06-11 上传
2021-10-23 上传

我慢慢地也过来了
- 粉丝: 1w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- React项目开发:从构建到部署的详细指南
- CC254x蓝牙4.0协议栈官方安装包下载
- MySQL Connector/C++ x64便携版v1.1发布
- React Native松露盒项目开发与部署指南
- 亚特兰大公司应用开发与TypeScript实践
- rlwrap在Linux环境下的oracle命令回调功能指南
- 掌握VNC远程控制技巧及C++实现方法
- 解压缩Qualcomm QHSUSB驱动程序指南
- 城市生活环保主题PPT模板设计——绿色城市生活新风尚
- 雷电冲击波形的双指数拟合参数提取技术
- 仿制QQ游戏大厅框架与五子棋游戏实现
- Haskell项目HelloWorldYesod的搭建与开发
- 快速上手Express框架开发TodoList应用
- 全面解析VR材质库:探索20080304713728压缩包内容
- MyLogPHP.class - PHP程序员的日志记录利器
- 中国电信宽带测速器:快速了解网络速度
