构建哈夫曼树:编码、译码与文件操作详解
需积分: 10 188 浏览量
更新于2024-09-19
收藏 235KB DOC 举报
哈夫曼树编码与译码是一种基于数据压缩的技术,通过构建最优二叉树来实现对数据的高效存储。以下是主要知识点的详细阐述:
1. **哈夫曼树的构建**:
哈夫曼树是通过给定一组字符及其出现频率(权值)来构建的。首先,创建一个初始的二叉树集合F,包含每个字符作为一个独立的树,根节点的权值等于其对应的字符频率。然后,不断从F中选择权值最小的两棵树合并,形成新的树,新树的根节点权值为其子树权值之和,直至只剩下一棵树,即为哈夫曼树。这个过程可以用递归的方式实现。
2. **编码过程**:
一旦哈夫曼树生成,从根节点到每个叶子节点的路径就决定了字符的编码规则。从左分支代表'0',右分支代表'1',这样构建的路径可以形成一个独特的二进制编码。例如,如果字符A的编码路径是左-右-左,那么其编码就是101。
3. **编码与保存**:
创建编码表huffmanlink.txt,记录每个字符与其对应的二进制编码。将原始文本按照这些编码进行替换,生成压缩后的huffman.txt文件。
4. **解码与还原**:
读取huffman.txt文件时,需要通过哈夫曼树的结构确定每个字符的解码路径。从根节点开始,根据编码路径向左或向右移动,最终到达叶子节点,恢复出原始字符。这个过程可能需要存储结点的父节点和子节点信息,以便于解码。
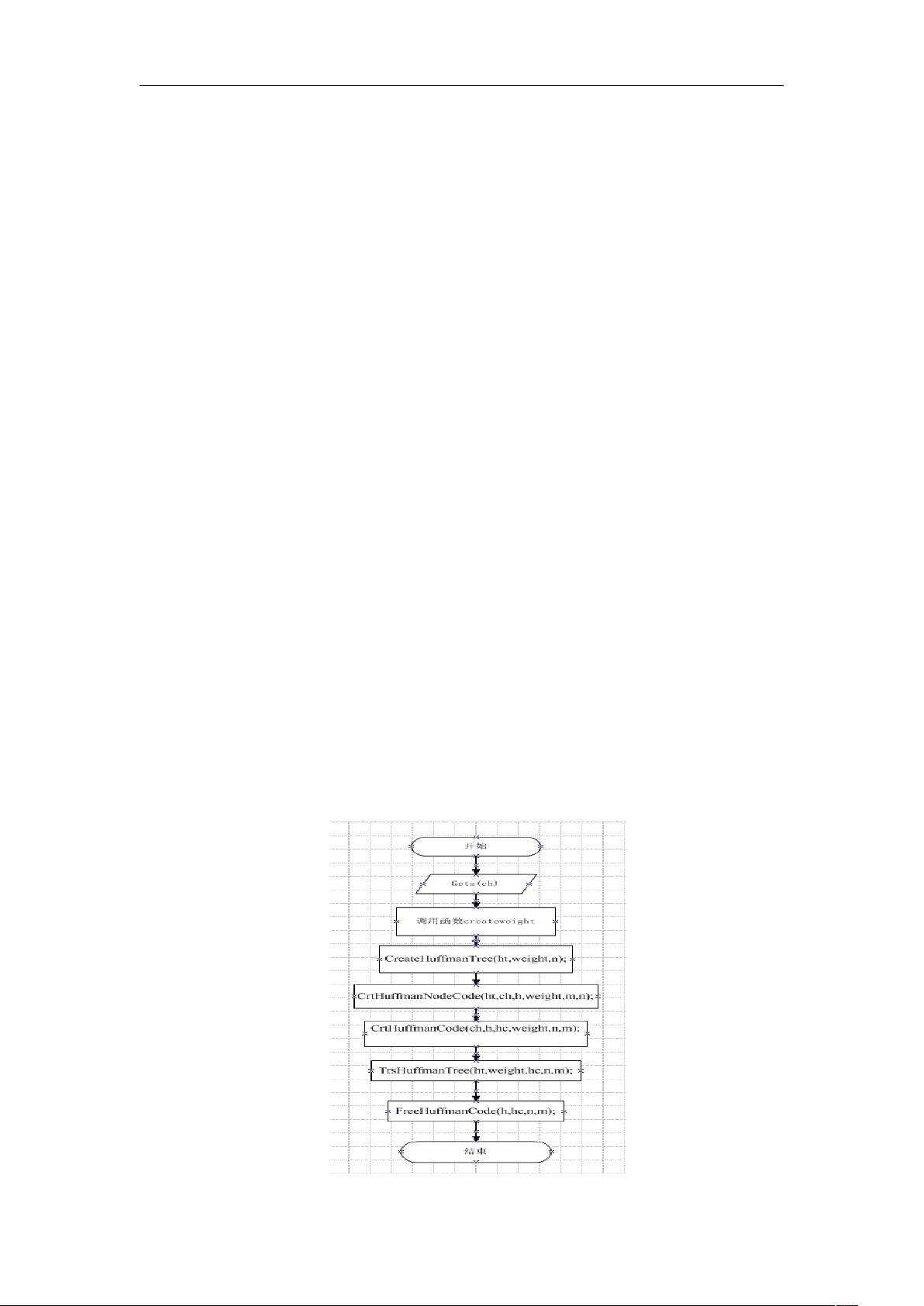
5. **算法流程图**:
提供了多个流程图,如主函数流程图展示了整个编码和解码的控制流程;createweight算法可能是计算权值的过程;CreateHuffmanTree算法是构建哈夫曼树的核心;CrtHuffmanNodeCode和CrtHuffmanCode算法分别处理节点编码和整个树的编码;TrsHuffmanTree则是从编码后的树还原原文的过程。
6. **源代码**:
源代码部分包含实际的编程实现,可能会包括定义哈夫曼树节点、合并节点、编码生成和解码等函数,这些函数按照算法流程图中的步骤进行操作。
总结起来,哈夫曼树编码与译码是一个基于概率和二叉树的数据压缩技术,通过构建最优二叉树来减少数据的存储空间。整个过程包括构建哈夫曼树、字符编码、存储编码表、解码还原以及相关的算法实现和数据处理流程。
用两种方式实现表达式自动计算
一、 设计思想
哈夫曼树又称最优树,是一种带权路径最短的树。树中任何一个结点到其子节
点的指尖的分支构成两点之间的路径,分支的个数称为路径长度。树的路径长度是
指从跟到每一个结点的路径长度与结点权值的乘积。树的带权路径长度是指所有叶
子结点带权路径长度之和。
1.假设有 N 个权值{W1,W2,…,Wn},试构造以一棵有 N 个叶子结点的二叉树,
每个叶子结点带权为 Wi,则其中带权路径长度 WPL 最小的二叉树称做最优二叉
树或哈夫曼树。
2. 在 统 计 完 各 个字 符 出 现 的 次 数 之 后 , 以 其 出 现 的 次 数 作 为 权 值 建 立 起
HumanTree.并且约定左分支表示字符‘0’,右分支表示‘1’,则可以从根结点的
路径上分支字符组成字符串作为该叶子结点字符的编码。然后根据建立起的树实
现各个字符的编码,生成编码表文件 humanlink.txt。
3.哈夫曼树建立之后,求每一个字符的编码需要走一条从叶子结点出发,走一条从
叶子结点到根结点的路径。实现各个字符的编码之后,在将原英文文章编码,将
所得的文章编码的结果保存在一个文件 human.txt 当中。
4.读文件 human.txt,需要从根结点到叶子结点的路径,因而对于每一个结点既
需要知道其双亲结点的信息,又要知道其孩子结点的信息读编码生成原文件,并
将所得结果保存在文件 yuan.txt 当中。
5.HumanTree 的建法为:
( 1 ) . 根 据 给 定 的 n 个 权 值 {W1 , W2 , … ,Wn} 构 成 n 棵 二 叉 树 的 集 合
F={T1,T2,…,Tn}其中每棵二叉树 Ti 中只有一个带权为 Wi 的根结点,其左
右子树均为空。
(2).在 F 中选两棵根结点的权值最小的树作为左右子树构造一个新的二叉树,并
置新二叉树的根结点的权值为其左右子树上根结点的权值之和。
(3).在 F 中删除这两棵树,同时将新得到的二叉树加入到 F 中。
(4).重复(2)( 3),直到含有一棵树为止。这棵树便是 HumanTree.
二、算法流程图
- 1 -
下载后可阅读完整内容,剩余9页未读,立即下载
3957 浏览量
1413 浏览量
103 浏览量
794 浏览量
126 浏览量
516 浏览量
443 浏览量

single0307
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 富文本编辑器图片获取与缩略图设置方法
- 亿图画图工具:便捷流程图设计软件
- C#实现移动二次曲面拟合法在DEM内插中的应用
- Symfony2中VreshTwilioBundle:Twilio官方SDK的扩展包装器
- Delphi调用.NET DLL的Win32交互技术解析
- C#基类库大全:全面解读.NET类库与示例
- 《计算机应用基础》第2版PPT教学资料介绍
- VehicleHelpAPI正式公开:发布问题获取使用权限
- MATLAB车牌自动检测与识别系统
- DunglasTorControlBundle:Symfony环境下TorControl的集成实现
- ReactBaiduMap:打造React生态的地图组件解决方案
- 卡巴斯基KEY工具:无限期循环激活解决方案
- 简易绿色版家用FTP服务器:安装免、直接配置
- Java Mini Game Collection解析与实战
- 继电器项目源码及使用说明
- WinRAR皮肤合集:满足不同风格需求
