哈夫曼树与编码:原理、算法及代码实现
53 浏览量
更新于2024-08-03
收藏 2.81MB PDF 举报
"哈夫曼树(Huffman Tree)与哈夫曼编码是数据结构与算法领域中的重要概念,主要用于数据压缩和编码优化。哈夫曼树是一种特殊的二叉树,也被称为最优二叉树,其特点在于具有最短的带权路径长度。这种树结构在各种应用中,如文本压缩、通信等领域,都能有效地提高效率。
哈夫曼树的基本概念包括以下几个方面:
1. **路径**:在树中,从一个节点到另一个节点之间的分支构成了它们之间的路径。
2. **节点的路径长度**:从一个节点到另一个节点的路径上分支的数量。
3. **树的路径长度**:从树的根节点到所有节点的路径长度之和,记作TL。
4. **权重**(Weight):在树的上下文中,节点被赋予了具有特定意义的数值,这个数值就是节点的权重,它可以代表不同的含义,如在哈夫曼树中可能代表字符出现的频率。
5. **节点的带权路径长度**:从根节点到节点的路径长度与其权重的乘积。
6. **树的带权路径长度**:树中所有叶子节点的带权路径长度之和,这也是哈夫曼树优化的目标。
哈夫曼树的特性是带权路径长度(WPL)最短,这意味着在具有相同度数的树中,它是最优的。这种特性使得哈夫曼树在数据编码和压缩中特别有效。
哈夫曼树的构造算法通常分为以下步骤:
1. **初始化**:根据给定的n个权重值创建n棵二叉树,每棵树只有一个根节点,其权重值等于对应的给定值。
2. **合并**:每次选择森林中权值最小的两棵树,将它们合并成一棵新树,新树的根节点的权重是这两棵树的根节点权重之和。
3. **迭代**:重复步骤2,直到森林中只剩下一棵树,这棵树就是哈夫曼树。
在构建哈夫曼树的过程中,会进行n-1次合并,产生n-1个新节点,这些新节点都是有两个子节点的内部节点。因此,哈夫曼树共有2n-1个节点,其中所有内部节点的度数都不为1。
为了实现哈夫曼树,我们需要定义节点的数据结构,通常包括节点的值(权重)、左子节点和右子节点的引用。在实际编码中,还会使用队列或堆来辅助构建过程,确保每次都能找到权值最小的节点进行合并。
哈夫曼编码是基于哈夫曼树构建的一种变长编码方式,每个字符或符号都会被分配一个唯一的二进制编码,短编码分配给频率高的字符,长编码分配给频率低的字符。这样,频繁出现的字符在编码后占用的位数较少,从而达到数据压缩的目的。
哈夫曼树和哈夫曼编码是数据压缩技术的核心,通过构建最优的二叉树结构,可以实现高效的数据编码,广泛应用于文件压缩、网络传输等领域。理解和掌握这些概念对于提升算法设计和分析能力至关重要。"
超
详
细
讲解
哈
夫
曼树
(Huffman Tree)
以
及 哈
夫
曼
编
码 的
构
造
原
理
、
⽅
法
,
并
⽤
代
码
实
现
。
1
哈
夫
曼树
基
本
概
念
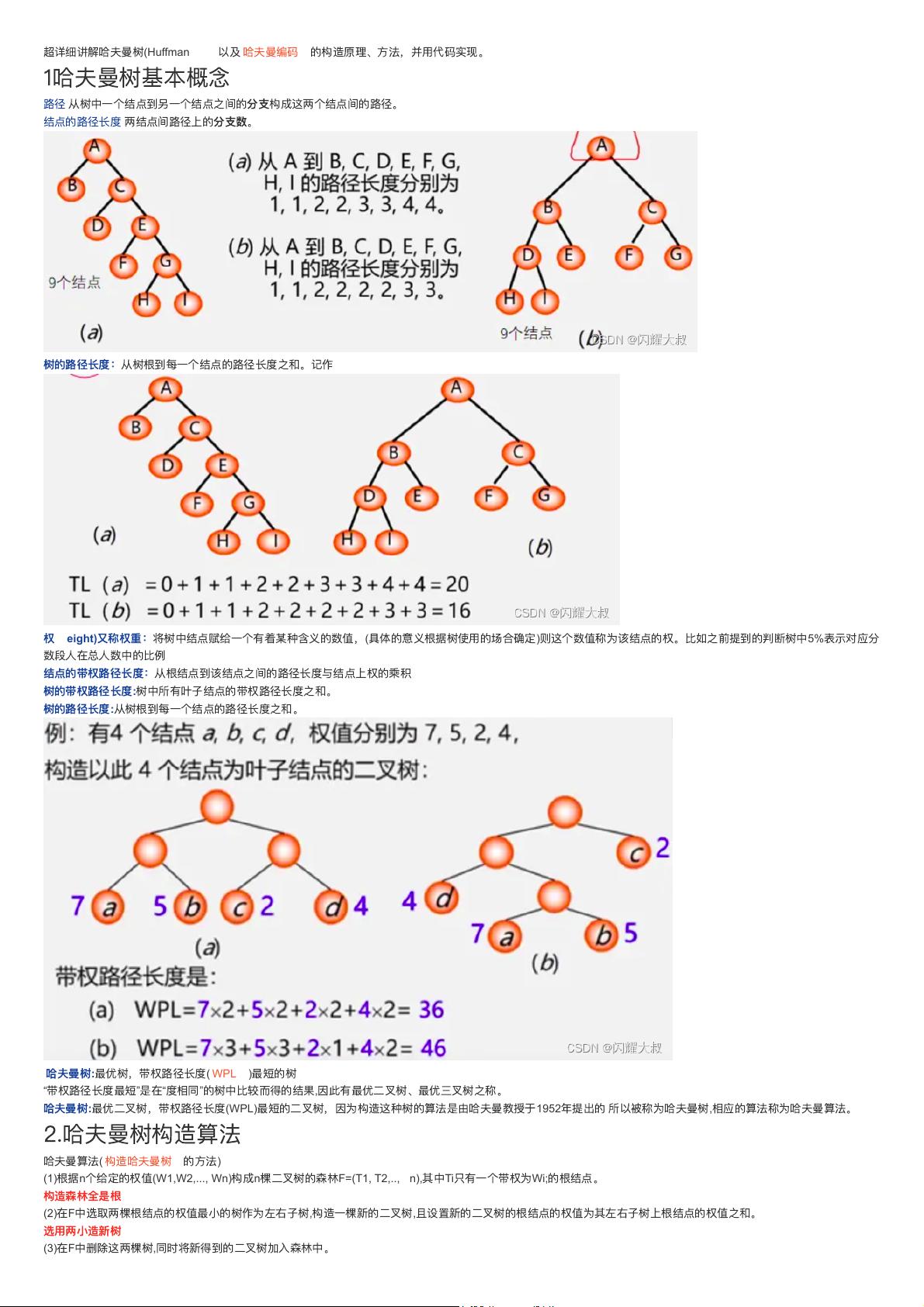
路
径
:
从
树
中
⼀个
结
点
到
另
⼀个
结
点
之
间
的
分
⽀
构
成
这
两个
结
点
间
的
路
径
。
结
点
的
路
径
⻓
度
:
两
结
点
间
路
径
上
的
分
⽀数
。
树
的
路
径
⻓
度
:
从
树根
到
每
⼀个
结
点
的
路
径
⻓
度
之
和
。
记
作
: TL
权
(weight)
⼜
称
权
重
:
将
树
中
结
点
赋
给
⼀个
有
着
某
种
含
义
的
数
值
,
(
具
体
的
意
义
根
据
树
使
⽤
的
场
合
确
定
)
则
这
个
数
值
称
为
该
结
点
的
权
。
⽐
如
之
前
提
到
的
判
断
树
中
5%
表
示
对
应
分
数
段
⼈
在
总
⼈
数
中
的
⽐
例
结
点
的
带
权
路
径
⻓
度
:
从
根
结
点
到
该
结
点
之
间
的
路
径
⻓
度
与
结
点
上
权
的
乘
积
树
的
带
权
路
径
⻓
度
:
树
中
所
有
叶
⼦
结
点
的
带
权
路
径
⻓
度
之
和
。
树
的
路
径
⻓
度
:
从
树根
到
每
⼀个
结
点
的
路
径
⻓
度
之
和
。
哈
夫
曼树
:
最
优
树
,
带
权
路
径
⻓
度
( WPL )
最
短的
树
“
带
权
路
径
⻓
度
最
短
”
是
在
“
度
相
同
”
的
树
中
⽐
较
⽽
得
的
结
果
,
因
此
有最
优⼆
叉
树
、
最
优
三
叉
树
之
称
。
哈
夫
曼树
:
最
优⼆
叉
树
,
带
权
路
径
⻓
度
(WPL)
最
短的
⼆
叉
树
,
因
为
构
造这
种
树
的
算
法
是
由
哈
夫
曼
教授
于
1952
年
提
出
的
,
所
以
被
称
为
哈
夫
曼树
,
相
应
的
算
法
称
为
哈
夫
曼
算
法
。
2.
哈
夫
曼树构
造
算
法
哈
夫
曼
算
法
(
构
造
哈
夫
曼树
的
⽅
法
)
(1)
根
据
n
个
给
定
的
权
值
(W1,W2,..., Wn)
构
成
n
棵
⼆
叉
树
的
森
林
F=(T1, T2,.., Tn),
其
中
Ti
只
有
⼀个
带
权
为
Wi;
的
根
结
点
。
构
造
森
林
全
是根
(2)
在
F
中
选
取
两
棵
根
结
点
的
权
值
最
⼩
的
树
作为
左
右
⼦
树
,
构
造
⼀
棵
新
的
⼆
叉
树
,
且
设
置
新
的
⼆
叉
树
的
根
结
点
的
权
值
为
其
左
右
⼦
树
上
根
结
点
的
权
值
之
和
。
选
⽤
两
⼩
造
新
树
(3)
在
F
中
删
除
这
两
棵
树
,
同
时
将
新
得
到
的
⼆
叉
树
加⼊
森
林
中
。
下载后可阅读完整内容,剩余8页未读,立即下载
2022-09-20 上传
2013-02-06 上传
2023-11-03 上传
2023-11-24 上传
2022-09-23 上传
2022-07-15 上传
2023-06-13 上传

番茄小能手
- 粉丝: 5070
- 资源: 234
 我的内容管理
展开
我的内容管理
展开







最新资源
- cassandra-schema-fix:比较Cassandra架构和数据文件夹内容并修复差异
- c代码-ID sorted
- nodejs-practice:node.js的个人实践和参考(javascript)
- nitrogen-css:一个非常出色CSS前端框架,还不错
- 火车售票管理系统-java.zip
- delta-green-foundry-vtt-system-unofficial:Delta Green的Foundry VTT游戏系统
- strimpack:直播者为观众打造家园的平台
- 单向:单向恢复客户端
- cpp代码-(一维数组)计算n位学生成绩的平均分与均方差
- pysha3:hashlib.sha3的2.7到3.5的反向移植
- 用FPGA实现数字锁相环.7z
- 嵌入式数据库使用java进行开发的一款android端的学生信息管理系统
- thegarage-template:Rails应用模板
- React-Website-BoilerPlate:通用零件的锅炉板
- ansible-role-certbot
- pyspark-testing:使用PySpark进行单元和集成测试可能很困难,让我们更轻松地进行
