MeanShift算法详解:历史发展、推广与应用
MeanShift算法是一种基于密度估计的非参数聚类方法,最初由Fukunaga等人在1975年提出,旨在寻找数据中的模式或密度峰值。它最初的含义是将每个点向其邻域的密度极大化方向移动,通过迭代过程不断更新位置,直至达到稳定状态。算法的核心思想是利用概率密度函数(PDF)的概念,每个点根据其周围点的分布计算移动向量,从而聚集在一起形成聚类。
Yizong Cheng在1995年的关键论文中对MeanShift进行了扩展,引入了核函数,使得距离较远的点对均值向量的影响减小,提高了算法的灵活性和适应性。他还引入了权重系数,根据样本的重要性调整偏移量,进一步扩展了算法的应用范围,并指出了MeanShift在诸如图像处理中的潜在用途,如图像平滑、图像分割和模态检测。
Comaniciu等人在后续的研究中将MeanShift应用于特征空间分析,特别是在非刚体物体跟踪和实时处理中,他们证明了在特定条件下,MeanShift确实会收敛到概率密度函数的局部极值点,这些极值点通常对应于数据集中的聚类中心。此外,MeanShift在实际应用中展现出强大的能力,包括数据聚类,通过平滑过程去除噪声,精确分割图像,以及在实时场景下进行目标追踪。
MeanShift的基本步骤包括:
1. 初始化:选择一个起始点。
2. 计算密度:对于每个点,计算其邻域内的点密度。
3. 计算偏移向量:基于核函数和权重,计算每个点向密度最大的方向移动的距离。
4. 移动点:将当前点移动到新的位置。
5. 重复步骤2-4,直到达到停止条件(例如,达到最大迭代次数或点的位置变化小于阈值)。
算法背后的物理含义在于,它模拟了粒子在高密度区域的自然聚集行为,类似于气体分子倾向于聚集在能量最低的地方。这使得MeanShift成为一种直观且有效的无监督学习工具,尤其适用于没有预定义类别信息的数据集。
MeanShift算法是一种强大的数据分析工具,具有广泛的应用前景,尤其在图像处理、聚类分析和实时跟踪等领域展现出了卓越性能。通过理解其基本原理、扩展及背后的物理解释,我们可以更好地利用MeanShift解决实际问题。
3
(
)
2
()
Kxkx
= (3)
并且满足:
(1)
k
是非负的.
(2)
k
是非增的,即如果
ab
<
那么
()()
kakb
≥
.
(3)
k
是分段连续的,并且
0
()krdr
∞
<∞
∫
那么,函数
()
Kx
就被称为核函数.
举例:在 Mean Shift 中,有两类核函数经常用到,他们分别是,
单位均匀核函数:
1 if 1
()
0 if 1
x
Fx
x
<
=
≥
(4)
单位高斯核函数:
2
()
x
Nxe
−
= (5)
这两类核函数如下图所示.
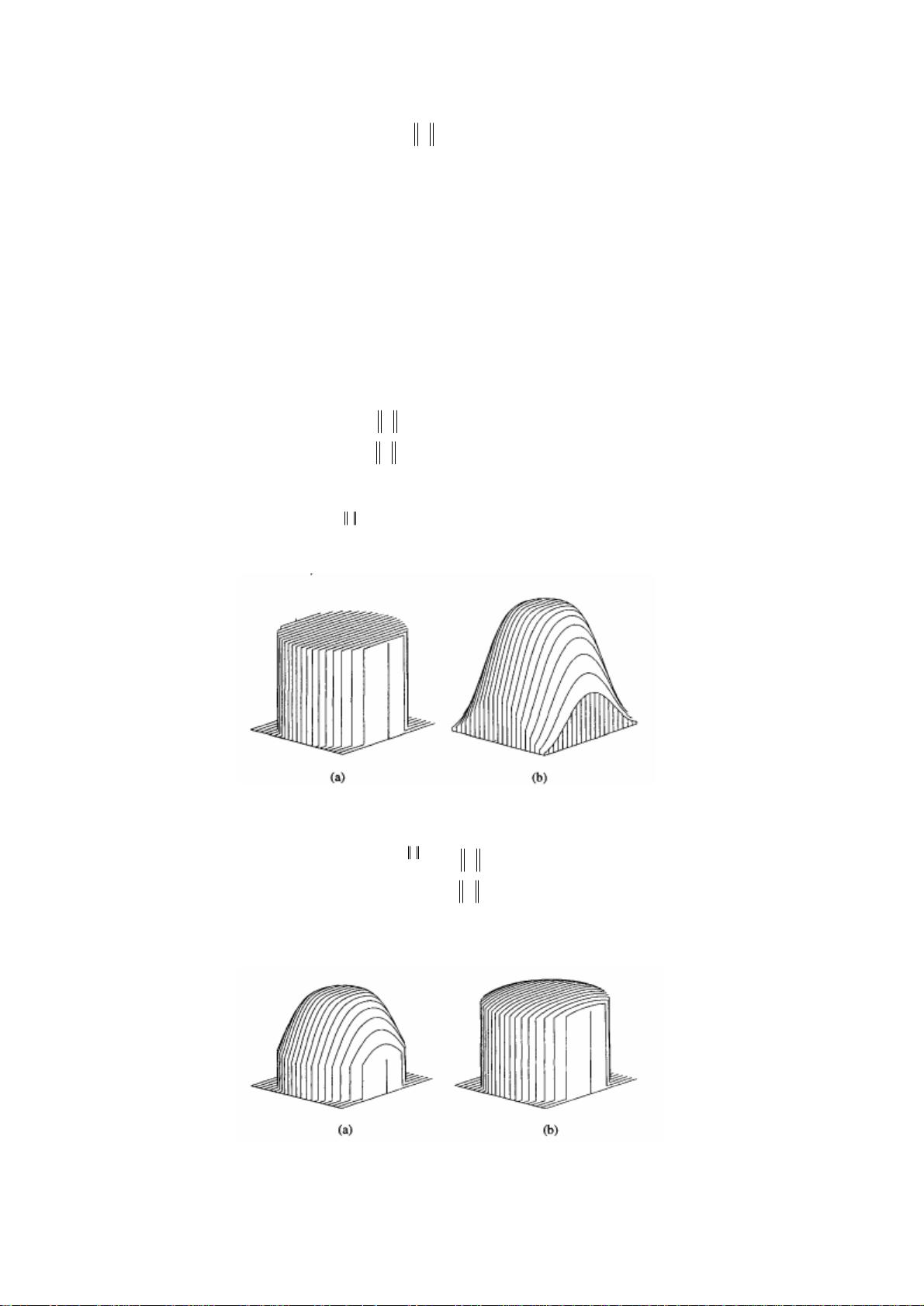
图 2, (a) 单位均匀核函数 (b) 单位高斯核函数
一个核函数可以与一个均匀核函数相乘而截尾,如一个截尾的高斯核函数为,
( )
2
if
()
0 if
x
ex
NFx
x
β
β
λ
λ
λ
−
<
=
≥
(6)
图 3 显示了不同的
,
βλ
值所对应的截尾高斯核函数的示意图.
图 3 截尾高斯核函数 (a)
1
1
NF
(b)
0.1
1
NF
剩余14页未读,继续阅读
2021-08-09 上传
2009-08-12 上传
2014-04-01 上传
2013-12-13 上传
2009-04-20 上传
2013-11-20 上传
2024-11-18 上传

mingzunn
- 粉丝: 0
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
