深度学习进阶:RNN与GRU模型详解及实现
132 浏览量
更新于2024-08-30
收藏 431KB PDF 举报
"《动手学习深度学习》之三:3.RNN循环神经网络(进阶)-4种模型(打卡2.6),通过介绍RNN循环神经网络的进阶概念,特别是GRU(门控循环神经网络)模型,帮助读者深入理解时间序列数据处理的机制。"
在深度学习领域,循环神经网络(Recurrent Neural Network, RNN)是一种用于处理序列数据的强大模型,尤其在自然语言处理、语音识别和时间序列预测等任务中表现优秀。然而,传统的RNN存在一个主要问题,即在反向传播过程中,由于长时间依赖问题导致的梯度消失(vanishing gradient)和梯度爆炸(exploding gradient)现象,这限制了模型学习长期依赖的能力。
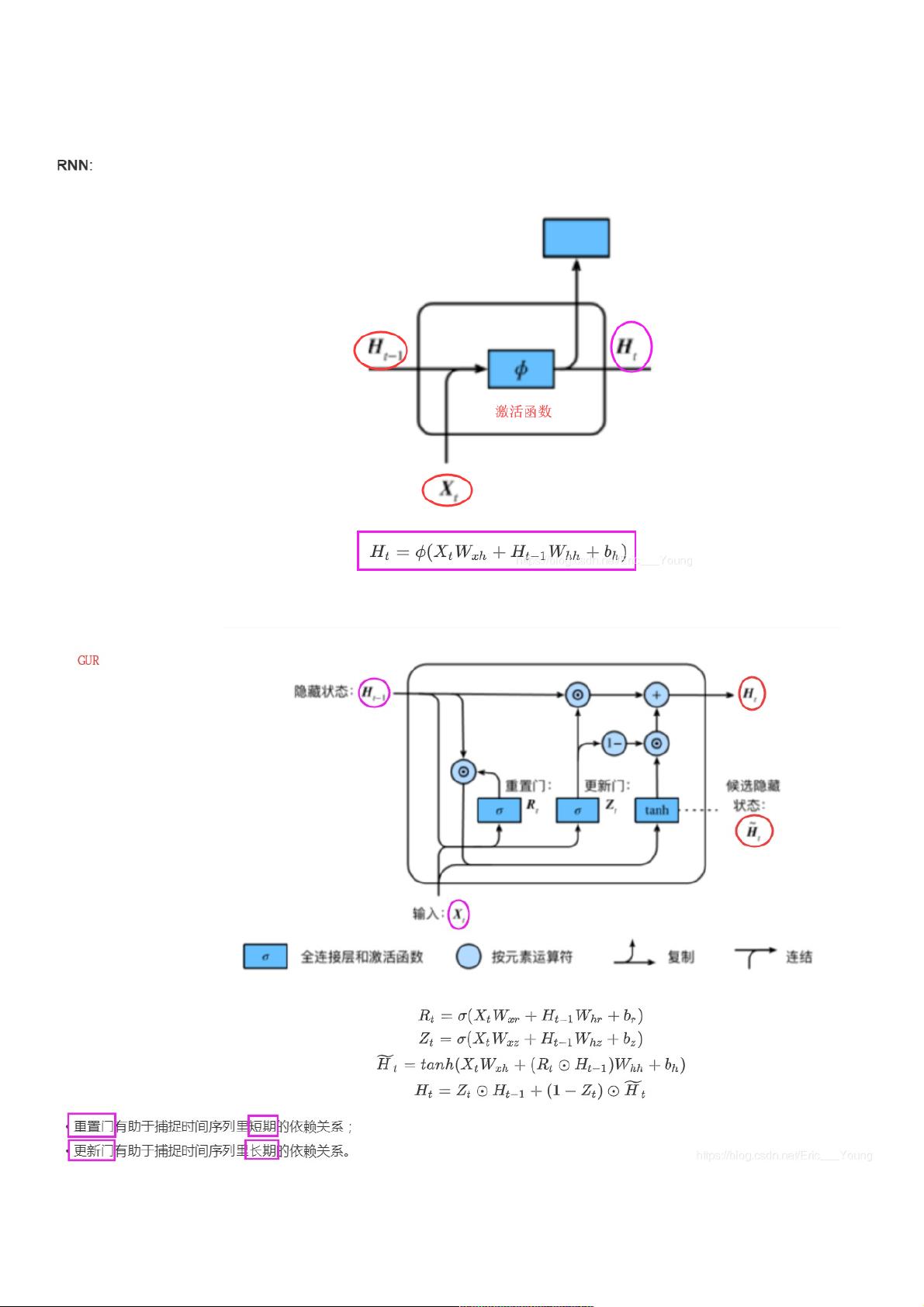
为了解决这个问题,GRU(Gated Recurrent Unit)应运而生。GRU结合了重置门(reset gate)和更新门(update gate)的概念,以更好地捕获不同时间步长内的依赖关系。重置门允许模型忽略过去的一些信息,专注于当前时间步的信息,从而有助于捕捉短期依赖;而更新门则控制过去状态对当前状态的影响程度,有助于捕获长期依赖。
在GRU模型的从零实现部分,首先需要导入必要的库,如NumPy、PyTorch以及自定义的数据加载模块。在导入库之后,数据集被加载到设备上(通常是GPU,如果可用的话)。这里的数据集可能是诸如歌词之类的文本数据,用于训练模型理解和生成类似的序列。
初始化参数是构建模型的重要步骤。在这个例子中,参数包括输入、隐藏层和输出层的词汇大小,以及隐藏单元的数量。通过随机初始化权重矩阵和偏置向量,可以确保模型在训练开始时具有一定的随机性,有利于收敛。这里使用的是正态分布来初始化权重,且所有参数都被设置为可训练,以在训练过程中更新。
GRU的参数包括更新门和重置门的权重矩阵以及偏置项。这些参数将被用来计算每个时间步的门控值,以决定如何融合当前输入和之前的状态信息。在训练过程中,通过优化器(如Adam或SGD)调整这些参数,以最小化损失函数,从而提高模型的性能。
总结起来,本资源提供了关于GRU模型的深入讲解,从理论概念到实际实现,旨在帮助学习者深入理解如何利用门控机制改进RNN,以更有效地处理序列数据中的长期依赖问题。通过实际编程练习,学习者可以更好地掌握GRU的工作原理,并将其应用于自己的深度学习项目。
《动手学习深度学习》之三:《动手学习深度学习》之三:3.RNN循环神经网络(进阶)循环神经网络(进阶)-4种模型(打卡种模型(打卡2.6))
RNN循环神经网络(进阶)循环神经网络(进阶)
1.GRU(门控)模型(门控)模型
1.1.概念
1.1.1.RNN存在的问题:梯度较容易出现衰减或爆炸(BPTT)
1.1.2.GRU控循环神经络:捕捉时间序列中时间步距离较的依赖关系
重置有助于捕捉时间序列短期的依赖关系;
更新有助于捕捉时间序列期的依赖关系。
1.2.GRU模型从零实现
1.2.1.载入数据集
import numpy as np
import torch
from torch import nn, optim
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-06 上传
2023-06-14 上传
2024-03-24 上传
2021-06-03 上传
2021-01-06 上传
2021-07-08 上传

weixin_38522214
- 粉丝: 2
- 资源: 880
 我的内容管理
展开
我的内容管理
展开







最新资源
- MaterialDesign
- weather-data-analysis:R.的学校项目。天气数据的探索性数据分析
- function_test
- hex-web-development
- scrapy-poet:Scrapy的页面对象模式
- unigersecrespon,c语言标准库函数源码6,c语言
- 红色大气下午茶网站模板
- 流媒体:一个免费的应用程序,允许使用无限的频道进行流媒体播放
- Project-17-Monkey-Game
- TIP_Project:python中的简单语音通信器
- 分布式搜索引擎-学习笔记-3
- Project-68-to-72
- 2015-01-HUDIWEB-CANDRUN:金正峰、高艺瑟、裴哲欧、善胜铉
- B-Mail:B-MAIL是基于交互式语音响应的应用程序,它为用户提供了使用语音命令发送邮件的功能,而无需键盘或任何其他视觉对象
- prececfnie,删除c盘文件c语言源码,c语言
- cursos-rocketseat-discover:探索世界,了解更多Rocketseat
