悬崖行走问题:Sarsa与Q学习算法对比分析
需积分: 0 170 浏览量
更新于2024-08-05
收藏 376KB PDF 举报
"这篇摘要主要介绍了一个关于比较Sarsa和Q学习算法的编程实验,实验中还涉及到了n-Sarsa算法的性能分析。实验环境基于悬崖行走问题,该问题的状态转移和奖励机制在`cliff_environment.py`文件中定义。实验代码分为两个文件:`Q-learningVSSarsa.py`和`nSarsaVSSarsaLambda.py`,实现了四种不同的强化学习算法。实验结果表明,基础Sarsa和Q学习在收敛速度上相近,但Sarsa在稳定性及最终收益上优于Q学习。"
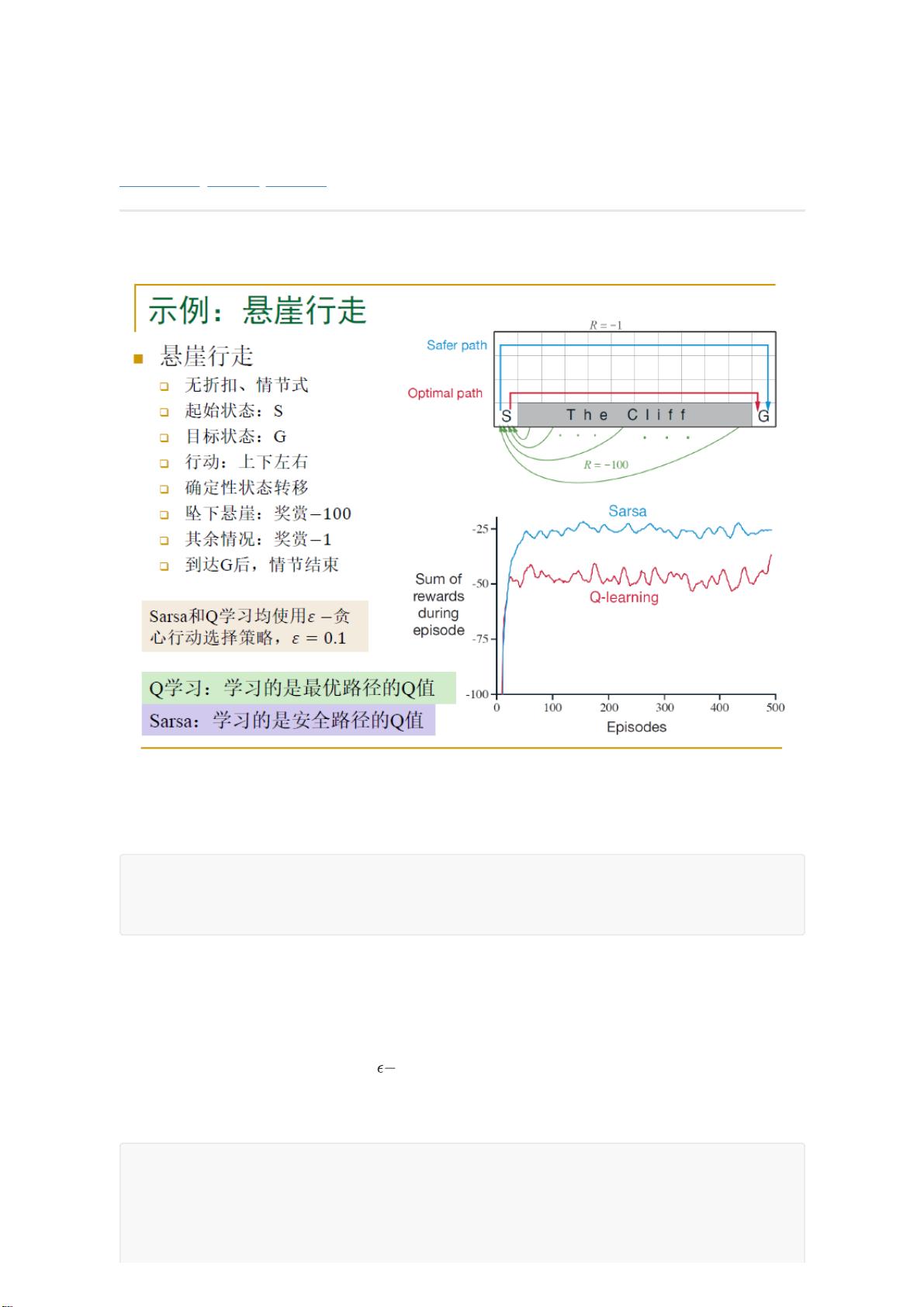
在这个编程题中,我们首先遇到了两种经典的强化学习算法:Sarsa(State-Action-Reward-State-Action)和Q学习。Sarsa是一种在线的、基于策略的强化学习算法,它在每个时间步更新Q值,使用实际经历的下一个状态和动作。而Q学习则是离线的,它使用的是策略迭代,总是选择当前状态下最大Q值的动作,不考虑实际采取的动作。
实验中,学习率(α)和ε-贪婪策略被设置为0.1。ε-贪婪策略在选择动作时平衡了探索和利用,ε概率选择随机动作,1-ε概率选择当前最优动作。无折扣因子(γ)被设置为1,这意味着考虑长期奖励,没有折现。实验运行了500个episode,使用队列记录每10次连续回报的平均值。
对于n-Sarsa的实验,n值分别设为1,3,5,研究了不同探索程度对算法性能的影响。n-Sarsa是Sarsa的一种变体,它在更新Q值时考虑了n步后的奖励,增加了对未来奖励的考虑,从而可能影响算法的收敛速度和稳定性。
实验结果显示,尽管Sarsa和Q学习的收敛速度相似,但Sarsa在稳定性上表现出色,其收益曲线更加平滑,可能是因为Sarsa使用实际经历的状态进行更新,而Q学习则依赖于预测的最大Q值,这可能导致在某些情况下过度优化。作者认为,这可能是由于ε-贪婪策略引入的不确定性导致的,Sarsa的评估更接近实际情况。
实验结果与PPT上的图像有所不同,可能与未指定的学习率和其他参数选择有关。这提示我们在进行强化学习实验时,参数的选择会显著影响算法的性能,需要根据具体问题和环境进行调整。
智能系统作业
人工智能学院 丁豪
181220010@smail.nju.edu.cn
问题描述
问题为悬崖行走问题,奖赏和状态转移情况如上图所示。为了便于统一管理此环境,将环境相关部分
全部放在cliff_environment.py中,主要是以下函数,他接受当前状态和行动作为参数,返回对应奖赏
以及下一状态,其中返回特殊状态[-1,-1]表示情节结束,将在后续判断中使用。
算法描述
分两个文件:Q-learning VS Sarsa.py 和 nSarsa VS SarsaLambda.py,分别用python实现了这四个
算法。其中公共的部分有参数初始化和 贪心,因此把它定义在cliff_environment.py中,增加代码复
用程度。在回报评价方面,参照QQ群中老师的要求改为图上每一个点代表第i次到第i+9次无折扣回报之
和的平均值,这里使用了队列来实现。
# cliff_environment.py
def RS_next(state,a):
return reward,next_State
## cliff_environment.py
# 返回全0的Q
def initialize_Q()
下载后可阅读完整内容,剩余3页未读,立即下载
2022-08-03 上传
2022-08-08 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传

我要WhatYouNeed
- 粉丝: 47
- 资源: 287
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
