




改进的基于密度层次聚类算法:解决CFSFD-P局限
版权申诉
38 浏览量
更新于2024-07-01
收藏 12.9MB PDF 举报
计算机研究 -基于密度的层次聚类算法研究.pdf
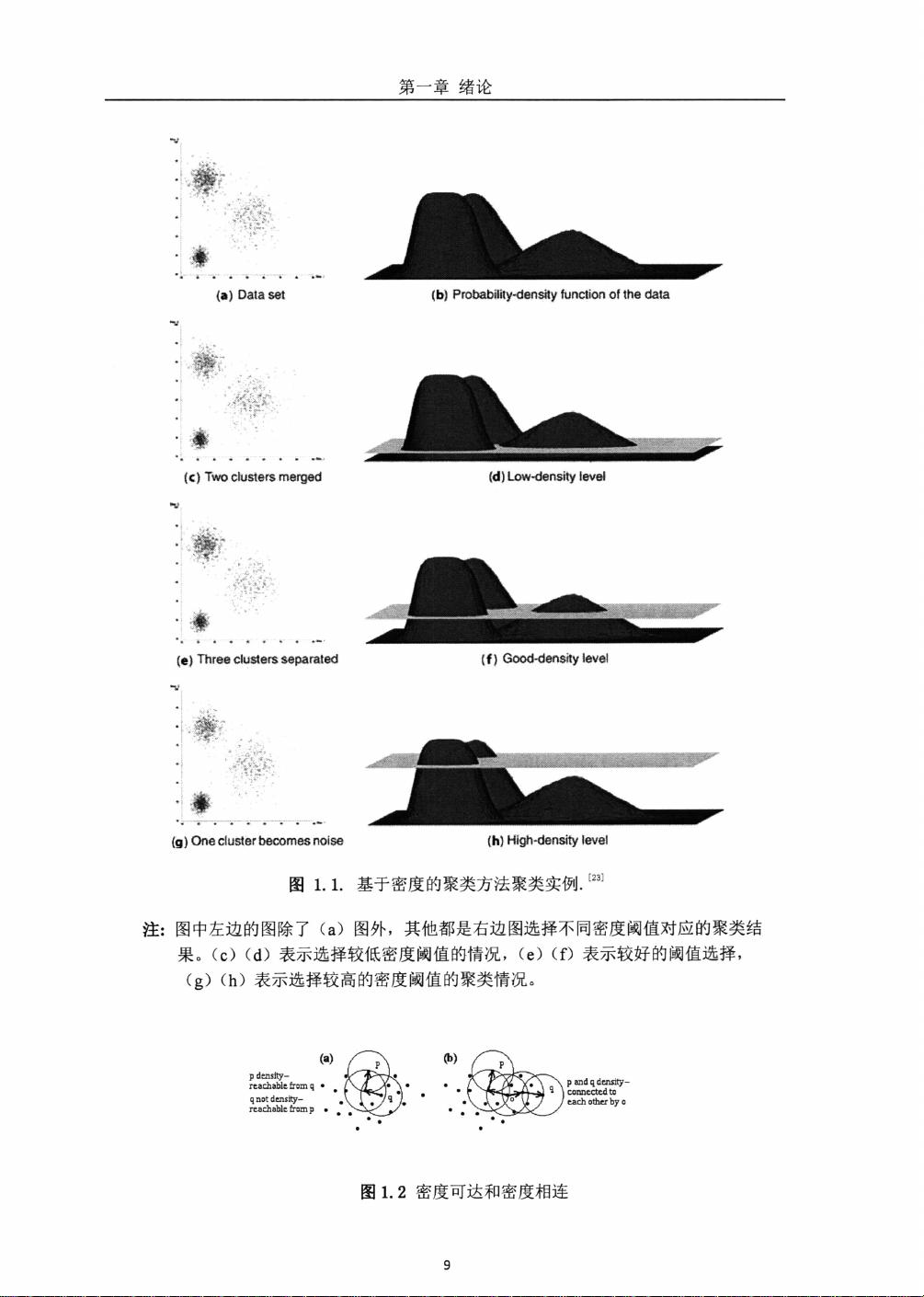
该论文深入探讨了在计算机科学研究中基于密度的聚类方法,特别是聚焦于一种名为CFSFD(P)的新型密度聚类算法。CFSFD(P)以其在处理复杂形状聚类和适应未知类别数量的优势而受到关注,它通过快速搜索和找到密度峰值来实现聚类。与传统的迭代聚类算法相比,CFSFD(P)具有较低的运行时间成本,且对用户指定参数的需求相对较少。
然而,尽管CFSFD(P)在许多情况下表现出色,但在实际应用中存在局限性。例如,当类中心较稀疏时,可能会被算法决策过程忽视。此外,CFSFD(P)的成功依赖于数据集中每个类只有一个密度极值点,如果超过一个,可能导致类的分裂问题。这限制了算法在某些数据集上的通用性。
为了克服这些问题,作者提出了一个新的基于密度的层次聚类算法,该算法是在CFSFD(P)的基础上构建的。首先,算法采用积极策略在CFSFD(P)的类中心基础上获取初始聚类,然后引入一个改进的类间距离计算模型,以衡量不同类别间的相似度。通过这个模型,算法能够逐步融合子类,形成最终的聚类结果,即使在没有单一密度极值点的情况下也能有效地工作。
层次聚类算法的引入使得算法更具灵活性,不再局限于单一的密度极值点,能够适应更多种类的数据分布。作者通过实验验证了新算法在无独特密度极值点的数据集上的有效性,并且在实际测试中,结果显示该算法的聚类性能接近原始数据源使用的算法,甚至有时表现更优。此外,相比于CFSFD(P),新的算法参数选择更为直观和简单,提高了用户的易用性。
论文的关键点包括密度聚类、层次聚类、相似性度量、密度极值、k近邻图以及高密度距离等概念,这些都构成了研究的核心内容,对于理解复杂数据集的聚类问题提供了新的视角和解决方案。通过深入研究这些技术,研究人员和实践者可以在处理具有挑战性的数据集时,提高聚类的准确性和鲁棒性。

万方数据

剩余67页未读,继续阅读
1924 浏览量
112 浏览量
127 浏览量
2022-06-26 上传
104 浏览量
2021-07-21 上传
410 浏览量
2021-07-14 上传
2022-06-27 上传

programyp
- 粉丝: 91
 我的内容管理
展开
我的内容管理
展开








最新资源
- RHCE必备知识与技能学习指南
- Eclipse SDK 3.5中文语言包的安装指南
- ESP32控制RF433Hz插座开关的HarmonyHub教程
- AndroidPN:高效率的XMPP服务器解决方案
- 全面解析财务预算管理流程及其在物流采购中的应用
- 深入解析Tomcat与Log4j日志配置要点
- CButtonST按钮类使用教程与技巧
- STM32移植FreeRTOS软件仿真教程
- KDE PIM: 跨平台开源个人信息管理应用
- Ribbon界面与Opencv算法整合的小工具教程
- VB记事本:自定义字体与状态栏时间显示
- 深入了解物流项目投标标书的制作与参考价值
- C语言实现隐马尔可夫模型源码解析
- 深入C#与.NET 3.5:掌握核心编程技术与API
- 物流成本预算核心流程详解及管理应用
- 掌握MD5散列算法:代码效率提升的强大工具






















