深度强化学习基础与应用
下载需积分: 50 | PDF格式 | 2.47MB |
更新于2024-07-16
| 63 浏览量 | 举报
"这篇文档是《An Introduction to Deep Reinforcement Learning》的一部分,由Vincent François-Lavet等人撰写,详细介绍了深度强化学习的基本概念、机器学习与深度学习的区别以及强化学习的框架。"
深度强化学习(Deep Reinforcement Learning,DRL)是人工智能领域的一个重要分支,它结合了深度学习的强大表征能力与强化学习的决策制定过程。在DRL中,智能体通过与环境的交互来学习最优策略,以最大化长期奖励。
1. 深度学习(Deep Learning)是机器学习的一个子领域,专注于构建多层神经网络以自动从数据中学习特征。这些层次结构允许模型捕获复杂的模式,使它们在图像识别、自然语言处理和许多其他任务中表现出色。
2. 监督学习(Supervised Learning)是深度学习中最常见的类型,涉及利用带有标签的训练数据来学习预测模型。偏差和过拟合是监督学习中的关键概念:偏差是指模型对数据的总体趋势理解不足,而过拟合则指模型过度适应训练数据,导致在新数据上的表现不佳。
3. 无监督学习(Unsupervised Learning)则没有标签信息,目标是发现数据内的结构或聚类。深度学习在无监督学习中也有应用,例如自编码器和生成对抗网络。
4. 强化学习(Reinforcement Learning)是一种试错学习,智能体在环境中执行动作并根据其结果收到奖励或惩罚。强化学习的正式框架包括环境、状态、动作、奖励和策略等元素。
5. 在强化学习中,学习策略的不同组件包括值函数(Value Function)和策略函数(Policy Function)。值函数估计在给定状态下未来奖励的期望值,而策略函数决定在给定状态下应采取的动作。
6. 从数据中学习策略有多种设置,如模型自由(Model-Free)和模型基础(Model-Based)学习,以及在线学习和离线学习。
7. 基于值的方法(Value-Based Methods)是DRL的一种策略,如Q-learning,它通过更新Q函数来近似最优策略,其中Q函数给出了在状态-动作对上预期的累积奖励。
8. Q-learning的关键思想是使用贝尔曼方程来迭代更新Q值,以达到最优策略。在深度Q网络(Deep Q-Network, DQN)中,Q函数由神经网络来表示,解决了传统Q-learning中状态空间过大导致的问题。
这份文档深入浅出地介绍了DRL的基础,涵盖了从基本概念到具体算法的多个方面,对于想要了解或研究这个领域的读者非常有价值。
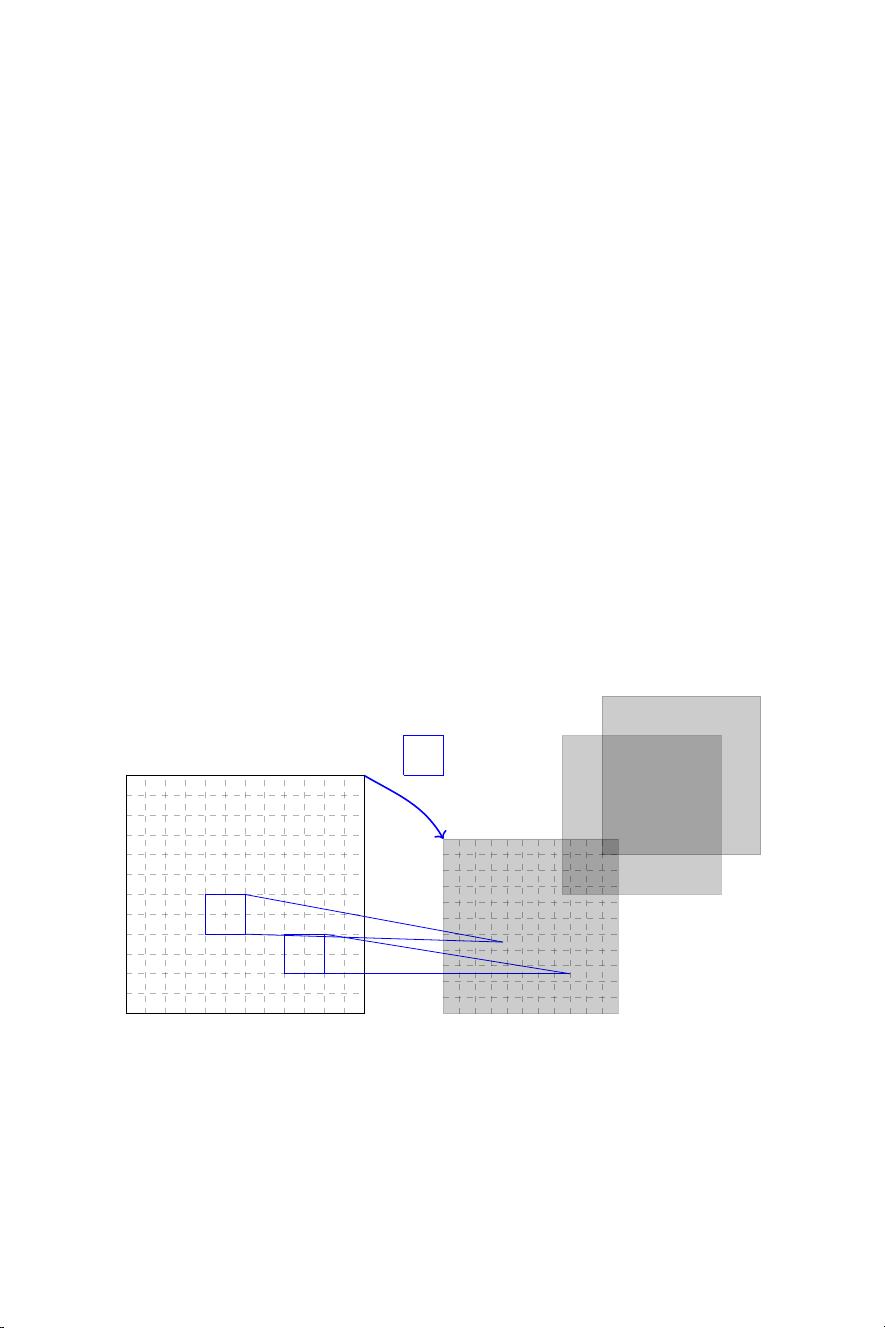
12 Machine learning and deep learning
in the last few years is to have an ever-growing number of layers, with
more than 100 in some supervised learning tasks (Szegedy et al., 2017).
We merely describe here two types of layers that are of particular interest
in deep RL (and in many other tasks).
Convolutional layers (LeCun, Bengio, et al., 1995) are particularly
well suited for images and sequential data (see Fig 2.3), mainly due
to their translation invariance property. The layer’s parameters consist
of a set of learnable filters (or kernels), which have a small receptive
field and which apply a convolution operation to the input, passing
the result to the next layer. As a result, the network learns filters that
activate when it detects some specific features. In image classification,
the first layers learn how to detect edges, textures and patterns; then
the following layers are able to detect parts of objects and whole objects
(Erhan et al., 2009; Olah et al., 2017). In fact, a convolutional layer is
a particular kind of feedforward layer, with the specificity that many
weights are set to 0 (not learnable) and that other weights are shared.
input image
or input feature map
filter
0 1
1 0
2
0
output feature maps
1
0
0
0
0
0
0
0
0
0
0
1
0
1
0
0
0
0
0
0
0
0
1
0
0
0
1
0
0
0
0
0
0
1
0
0
0
0
0
1
0
0
0
0
1
0
0
0
0
0
0
0
1
0
0
1
0
0
0
0
0
0
0
0
0
1
1
0
0
0
0
0
0
0
0
0
0
1
1
0
0
0
0
0
0
0
0
0
1
0
0
1
0
0
0
0
0
0
0
1
0
0
0
0
1
0
0
0
0
0
1
0
0
0
0
0
0
1
0
0
0
1
0
0
0
0
0
0
0
0
1
0
1
0
0
0
0
0
0
0
0
0
0
1
Figure 2.3:
Illustration of a convolutional layer with one input feature map that is
convolved by different filters to yield the output feature maps. The parameters that
are learned for this type of layer are those of the filters. For illustration purposes,
some results are displayed for one of the output feature maps with a given filter (in
practice, that operation is followed by a non-linear activation function).



剩余139页未读,继续阅读
相关推荐




dywlegend1002
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++简单实现classloader及示例分析
- 快速掌握UICollectionView横向分页滑动封装技巧
- Symfony捆绑包CrawlerDetectBundle介绍:便于用户代理检测Bot和爬虫
- 阿里巴巴Android开发规范与建议深度解析
- MyEclipse 6 Java开发中文教程
- 开源Java数学表达式解析器MESP详解
- 非响应式图片展示模板及其源码与使用指南
- PNGoo:高保真PNG图像压缩新选择
- Android配置覆盖技巧及其源码解析
- Windows 7系统HP5200打印机驱动安装指南
- 电力负荷预测模型研究:Elman神经网络的应用
- VTK开发指南:深入技术、游戏与医学应用
- 免费获取5套Bootstrap后台模板下载资源
- Netgen Layouts: 无需编码构建复杂网页的高效方案
- JavaScript层叠柱状图统计实现与测试
- RocksmithToTab:将Rocksmith 2014歌曲高效导出至Guitar Pro
