"高性能并行计算结课作业: 矩阵相乘的并行计算实现"
需积分: 0 112 浏览量
更新于2024-01-21
收藏 77KB DOCX 举报
本实验是高性能并行计算课程的结课作业1,主要涉及到矩阵相乘的并行计算实现。
实验中提供了三种不同的并行计算实现代码路径:
1. 矩阵相乘串行 C 语言程序路径:/home2/2020317110037/class_final/matrix/matrix_serial.c
2. 矩阵相乘 MPI 并行 C 语言程序路径:/home2/2020317110037/class_final/matrix/matrix_mpi.c
3. 矩阵相乘 MPI OpenMP 混合编程 C 语言程序路径:/home2/2020317110037/class_final/matrix/matrix_mpiopenmp.c
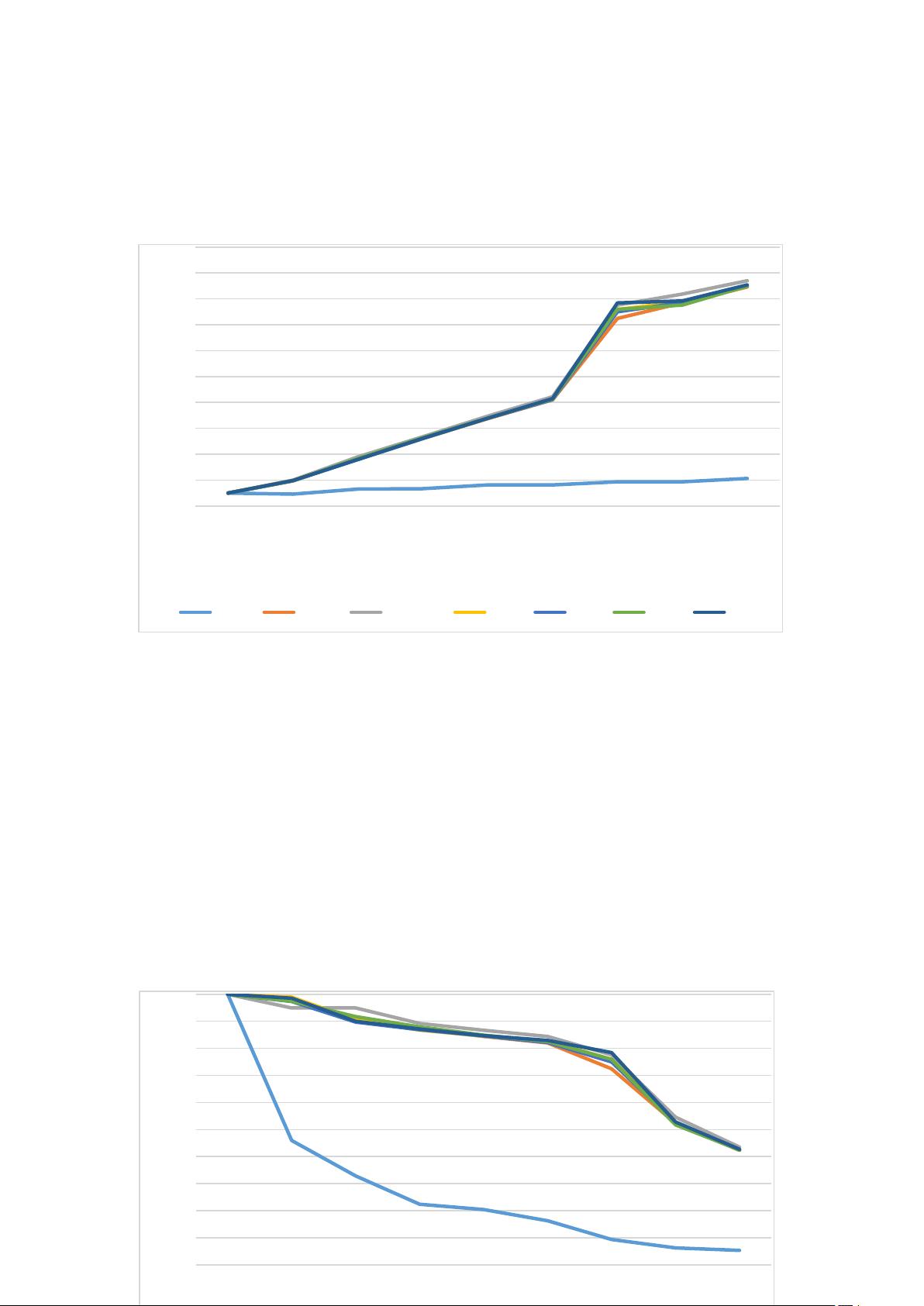
实验结果展示了两种不同实现方式在不同进程数和线程数下的运行时间、加速比和并行效率。
(1)MPI 并行,N=2000,进程数:
- 时间/s:239.32(串行)、260.10(并行)
- 加速比:1.00
- 并行效率:100.0%(串行)、99.1%(并行)
进程数:
- 时间/s:427.81(串行)、618.40(并行)
- 加速比:8.60
- 并行效率:215.1%(串行)、172.6%(并行)
进程数:
- 时间/s:617.40(串行)、816.84(并行)
- 加速比:13.75
- 并行效率:229.2%(串行)、177.6%(并行)
(2)MPI OpenMP 混合编程,N=2000,线程数为 4:
- 时间/s:239.32(串行)、250.46(并行)
- 加速比:4.74
- 并行效率:237.1%(串行)、129.0%(并行)
线程数为 4:
- 时间/s:420.61(串行)、611.04(并行)
- 加速比:11.61
- 并行效率:290.2%(串行)、361.2%(并行)
线程数为 4:
- 时间/s:88.42(串行)、228.0 (并行)
- 加速比:28
- 并行效率:undefined
综上所述,根据实验结果可以看出,在不同的实现方式和参数下,使用并行计算方法可以有效地减少矩阵相乘的运行时间并提高运行效率。其中,MPI OpenMP 混合编程在线程数为 4 时表现最佳,在最好情况下可以达到 28 倍的加速比。但是需要注意的是,在某些情况下并行效率可能高于100%,这是由于串行运行时间较长而导致的。

8
2.268025
6.77
84.60%
10
1.867960
8.22
82.18%
20
1.023393
15.00
75.00%
30
0.976732
15.72
52.40%
40
0.903846
16.98
42.46%
6.#pragma omp atomic
线程数
时间/s
加速比
并行效率
1
15.370000
1.00
100.0%
2
7.886547
1.95
97.44%
4
4.188002
3.67
91.75%
6
2.912816
5.28
87.94%
8
2.262848
6.79
84.90%
10
1.861620
8.26
82.56%
20
1.011704
15.19
75.95%
30
0.990499
15.52
51.73%
40
0.904637
16.99
42.47%
7.#pragma omp parallel for
线程数
时间/s
加速比
并行效率
1
15.400000
1.00
100.0%
2
7.812360
1.97
98.56%
4
4.276737
3.60
90.02%
6
2.944530
5.23
87.17%
8
2.272089
6.78
84.72%
10
1.856399
8.30
82.96%
20
0.981669
15.69
78.44%
30
0.972498
15.84
52.80%
40
0.901427
17.08
42.71%
剩余38页未读,继续阅读
2011-09-20 上传
141 浏览量
2021-11-16 上传
2023-05-25 上传
2023-08-26 上传
2023-06-13 上传
2023-08-22 上传
2024-09-12 上传
2024-06-26 上传

贼仙呐
- 粉丝: 32
- 资源: 296
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
