2018年CVPR双目立体视觉深度学习进展:MC-CNN、LRCR与CBMV
需积分: 25 198 浏览量
更新于2024-07-17
1
收藏 1.96MB PPTX 举报
双目立体视觉是一种计算机视觉技术,它利用两幅或多幅来自不同视角的图像来创建深度感知,通常用于三维重建、机器人导航、虚拟现实等领域。在CVPR2018年的论文中,研究者们针对这一主题进行了深入探讨,提出了几种关键的神经网络模型来改进立体匹配的精度和效率。
首先,MC-CNN (Multi-Column Convolutional Neural Network) 是由Jure Zbontar和Yann LeCun在2015年的Deep Learning会议上提出的,这是首次将卷积神经网络(CNN)应用于立体匹配。MC-CNN的基本思想是将图像块作为输入,通过训练多列网络来比较它们的相似性。它的架构分为两类:fast architecture 和 accurate architecture。fast architecture 在训练时确保正样本和负样本数量均衡,只有当正样本的相似度高于负样本时,损失函数才生效,这有助于提高网络对匹配准确性的敏感性。此外,MC-CNN采用了交叉成本聚合策略(CBCA),如CBCA扩散和支持域U(p),以及亚像素增强技术来提升细节处理能力。
LRCR (Left-Right Comparative Recurrent Model) 是2018年提出的一个进一步发展,它采用了一种左-右比较的递归模型,结合了常数高速路网络和卷积循环神经网络(ConvLSTM)。LRCR的重点在于通过左右图像间的比较,对遮挡区域的误匹配进行更细致的处理,例如使用背景视差值填充遮挡部分,并利用周围正确视差值的中位数进行插值校正。这种模型在构建Cost Volume时考虑了时间序列信息,从而提高了视差估计的鲁棒性和准确性。
另一项创新是CBMV (Coalesced Bidirectional Matching Volume),同样在2018年提出,这是一种并行匹配体积方法,用于估计视差。CBMV通过合并双向匹配,创建了一个联合的匹配体积,从而提高了视差估计的效率和一致性。这种方法减少了计算复杂性,有助于实时应用。
这些模型展示了双目立体视觉领域中深度学习技术的不断进步,通过优化网络架构、引入递归机制和创新的匹配策略,提高了视差估计的精度,为立体视觉任务提供了强大的工具。这些研究成果不仅推动了学术界的研究,也为实际应用提供了有价值的参考。
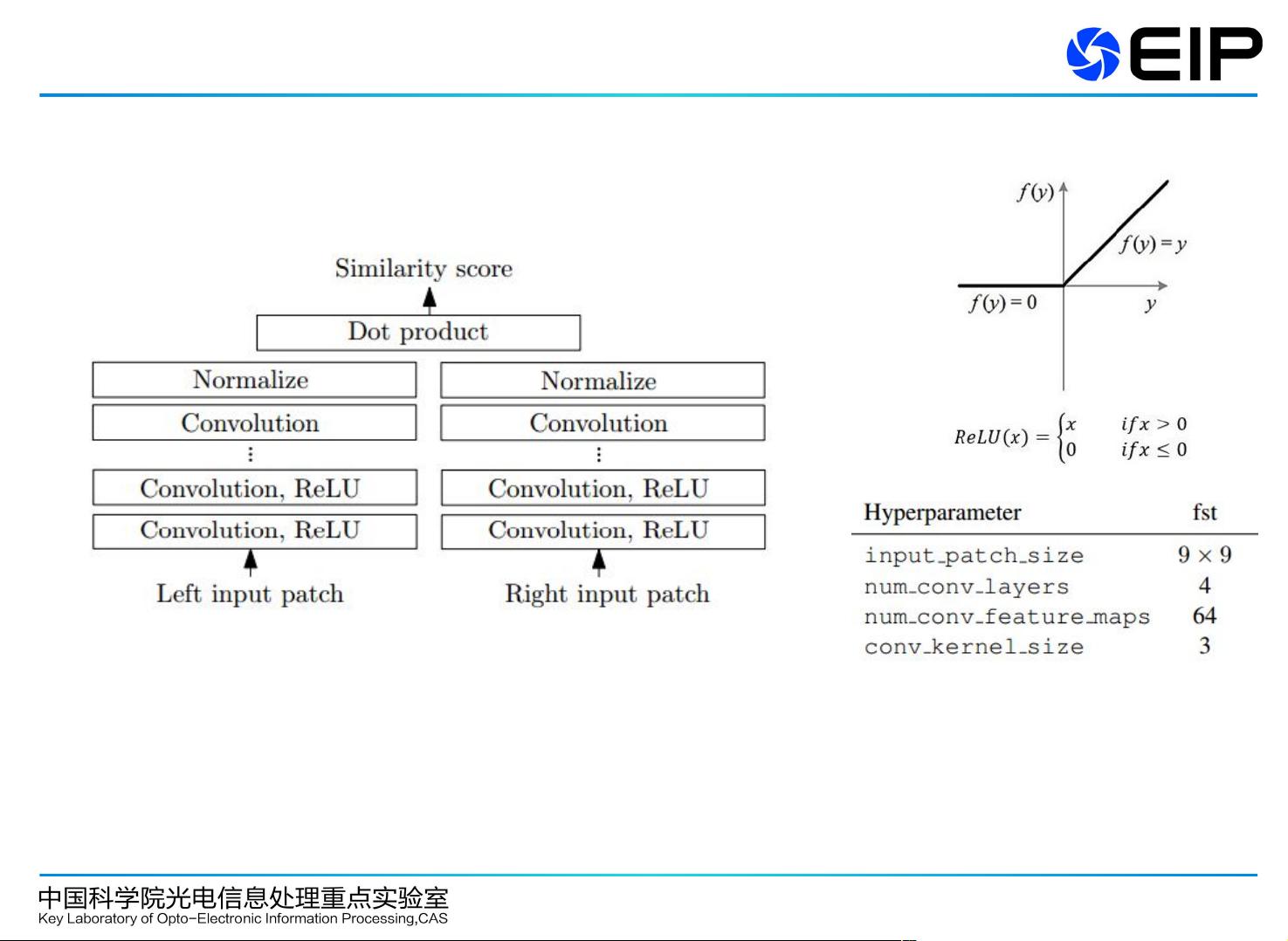
MC-CNN
fast architecture
只有当正样本的相似度超过负样本的相似度
m 时, 损失函数才是 0 , m=0.2.
, 0, Hinge s s max m s s
剩余23页未读,继续阅读
488 浏览量
1034 浏览量
755 浏览量
613 浏览量
788 浏览量
2024-10-30 上传
507 浏览量

ADSF31465
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







