提升Java并发性能:ConcurrentHashMap的内部机制与优化
153 浏览量
更新于2024-08-27
1
收藏 138KB PDF 举报
Java并发编程中的ConcurrentHashMap是一种特殊设计的线程安全哈希表,它在保证数据一致性的同时,极大地提高了并发性能。相比于普通的HashTable,ConcurrentHashMap的关键改进在于其内部的并发控制机制——Segment。
Segment是ConcurrentHashMap的核心组成部分,每个Segment实际上是一个独立的、线程安全的哈希表实现,类似于HashMap的一个子集。Segment内部包含以下重要成员:
1. count:表示当前Segment中存储的元素数量,用于跟踪Segment的容量利用情况。
2. modCount:计数器,每当对table(链表数组)进行可能影响大小的操作(如put或remove)时递增。这个计数器用于冲突解决策略,确保并发环境下的数据一致性。
3. threshold:阈值,当Segment中的元素数量达到这个阈值时,可能会触发扩容操作。
4. table:一个volatile的哈希表数组,存储键值对,每个元素都通过两次哈希定位到相应的Segment和链表位置。
ConcurrentHashMap定位元素的过程涉及两次哈希运算:首先根据键的哈希值计算出Segment的位置,然后在该Segment的链表中查找目标键值对。这种设计的优势在于,写操作时只需要对目标Segment加锁,而不会对其他Segment造成阻塞,从而最大化了并发性。在理想情况下,ConcurrentHashMap能支持与Segment数量相同的并行写入操作,只要这些操作均匀分布在所有Segment上。
Segment的存在使得ConcurrentHashMap在处理大量并发访问时,即使在高负载下也能保持相对较高的吞吐量,因为写操作的锁定范围更小。然而,这同时也意味着查找时间可能会比标准HashMap稍长,因为需要进行额外的Segment定位。尽管如此,这种优化使得ConcurrentHashMap成为处理大规模并发场景的理想选择,尤其是在需要频繁读写操作且保证数据一致性的应用场景中。在实际使用中,开发人员应该根据项目需求和性能指标来权衡是否使用ConcurrentHashMap,以及如何合理设置Segment的大小和负载因子等参数。
Java并发编程之并发编程之ConcurrentHashMap
ConcurrentHashMap
ConcurrentHashMap是一个线程安全的Hash Table,它的主要功能是提供了一组和HashTable功能相同但是线程安全的方
法。ConcurrentHashMap可以做到读取数据不加锁,并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地
尽量地小,不用对整个ConcurrentHashMap加锁。
ConcurrentHashMap的内部结构
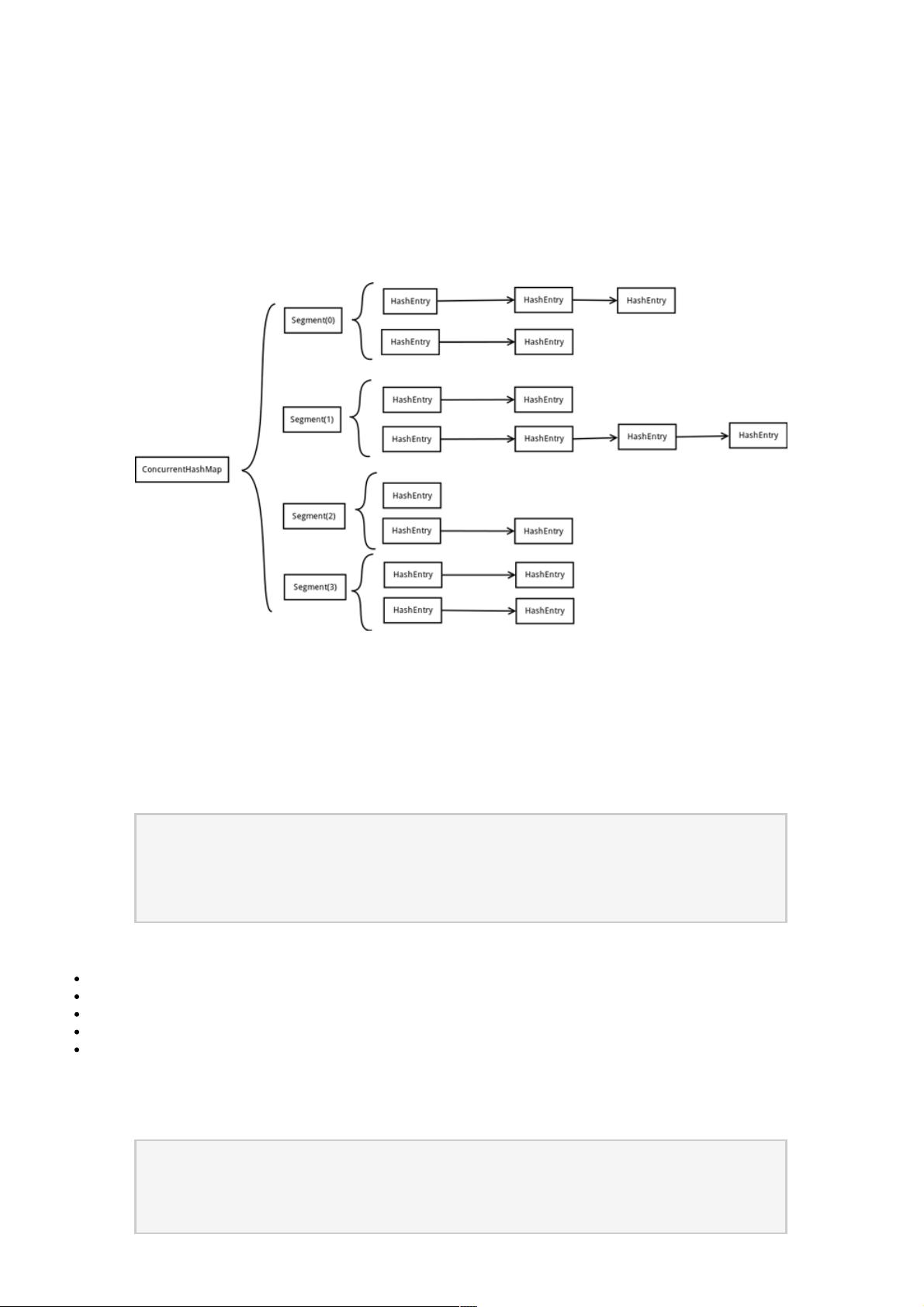
ConcurrentHashMap为了提高本身的并发能力,在内部采用了一个叫做Segment的结构,一个Segment其实就是一个类Hash
Table的结构,Segment内部维护了一个链表数组,我们用下面这一幅图来看下ConcurrentHashMap的内部结构:
从上面的结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到
Segment,第二次Hash定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap
要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最
理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所
有的Segment上),所以,通过这一种结构,ConcurrentHashMap的并发能力可以大大的提高。
Segment
我们再来具体了解一下Segment的数据结构:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile int count;
transient int modCount;
transient int threshold;
transient volatile HashEntry<K,V>[] table;
final float loadFactor;
}
详细解释一下Segment里面的成员变量的意义:
count:Segment中元素的数量
modCount:对table的大小造成影响的操作的数量(比如put或者remove操作)
threshold:阈值,Segment里面元素的数量超过这个值依旧就会对Segment进行扩容
table:链表数组,数组中的每一个元素代表了一个链表的头部
loadFactor:负载因子,用于确定threshold
HashEntry
Segment中的元素是以HashEntry的形式存放在链表数组中的,看一下HashEntry的结构:
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
下载后可阅读完整内容,剩余4页未读,立即下载
1068 浏览量
291 浏览量
303 浏览量
224 浏览量
点击了解资源详情
345 浏览量
104 浏览量
点击了解资源详情
点击了解资源详情

weixin_38500117
- 粉丝: 5
- 资源: 998
 我的内容管理
展开
我的内容管理
展开







最新资源
- React性的
- Distributed-Blog-System:分布式博客系统实现
- CloseMe-crx插件
- 欧式建筑立面图纸
- 北理工自控(控制理论基础)实验报告
- yolov7升级版切图识别
- 作业-1 --- IT202:这是我的第一个网站
- hit-and-run:竞争性编程的便捷工具
- Pytorch-Vanilla-GAN:适用于MNIST,FashionMNIST和USPS数据集的Vanilla-GAN的Pytorch实现
- SNKit:iOS开发常用功能封装(Swift 5.0)
- 创意条形图-手机应用下载排行榜excel模板下载
- 项目36
- 通过混沌序列置乱水印.7z
- reactive-system-design
- getwdsdata.m:从 EPANET 输入文件中获取配水系统数据-matlab开发
- 100多套html模块+包含企业模板和后台模板(适合初级学习)
