分类基础与技术:决策树、贝叶斯、规则与模型评估
版权申诉
PPT格式 | 1.98MB |
更新于2024-06-21
| 70 浏览量 | 举报
"数据挖掘chapter6classbasic"
在数据挖掘领域,分类是一种重要的有监督学习方法,主要用于预测离散或名义的类标签。本章节详细介绍了分类的基本概念、不同类型的分类算法以及模型评估与选择的策略。
首先,分类是基于已有的带有标签的训练数据来构建一个模型,该模型能够对新的、未见过的数据进行预测。例如,信用卡审批、医疗诊断、欺诈检测和网页分类等都是分类应用的实例。分类的目标是通过训练数据的特征和对应的类别信息,构建一个模型,以便对新数据进行预测。
有监督学习与无监督学习是两种主要的学习方式。有监督学习是分类的基础,其特点是训练数据带有标签,可以帮助算法学习并理解各个类别的特征。相反,无监督学习如聚类,则是在没有标签的情况下,通过寻找数据内在的结构和相似性来组织数据。
决策树归纳是常用的分类方法之一,它通过构建一棵树状结构来表示类别决策过程。贝叶斯分类则基于贝叶斯定理,利用先验概率和条件概率来进行预测。而基于规则的分类,如ID3、C4.5或CART等算法,会生成一系列易于理解和解释的if-then规则。
模型的评价与选择是确保分类性能的关键步骤。这通常包括计算准确率、精确率、召回率、F1分数等指标,并可能涉及交叉验证来评估模型在不同数据子集上的性能。为了提高分类准确率,有时会采用集成方法,如随机森林或梯度提升机,这些方法结合多个弱分类器构建强分类器,从而降低过拟合风险并提高泛化能力。
特征的选择和提取对于分类的效果至关重要。特征形成阶段包括从原始测量数据中提取有意义的特征,这可能涉及到特征工程,例如图像处理中的像素灰度值或医学检测中的生理指标。理想的特征应能显著区分不同类别,具有平移、旋转或尺度不变性等特性。特征选择要考虑问题的特定领域,以提高模型的分类能力和泛化能力。
最后,模型构建和使用是一个两步过程。使用训练集创建模型后,通过测试集评估模型的准确性,防止过拟合。测试集的标签与模型预测的标签对比,计算准确率以衡量模型性能。这种评估和优化过程是确保模型在实际应用中有效性的关键步骤。
15
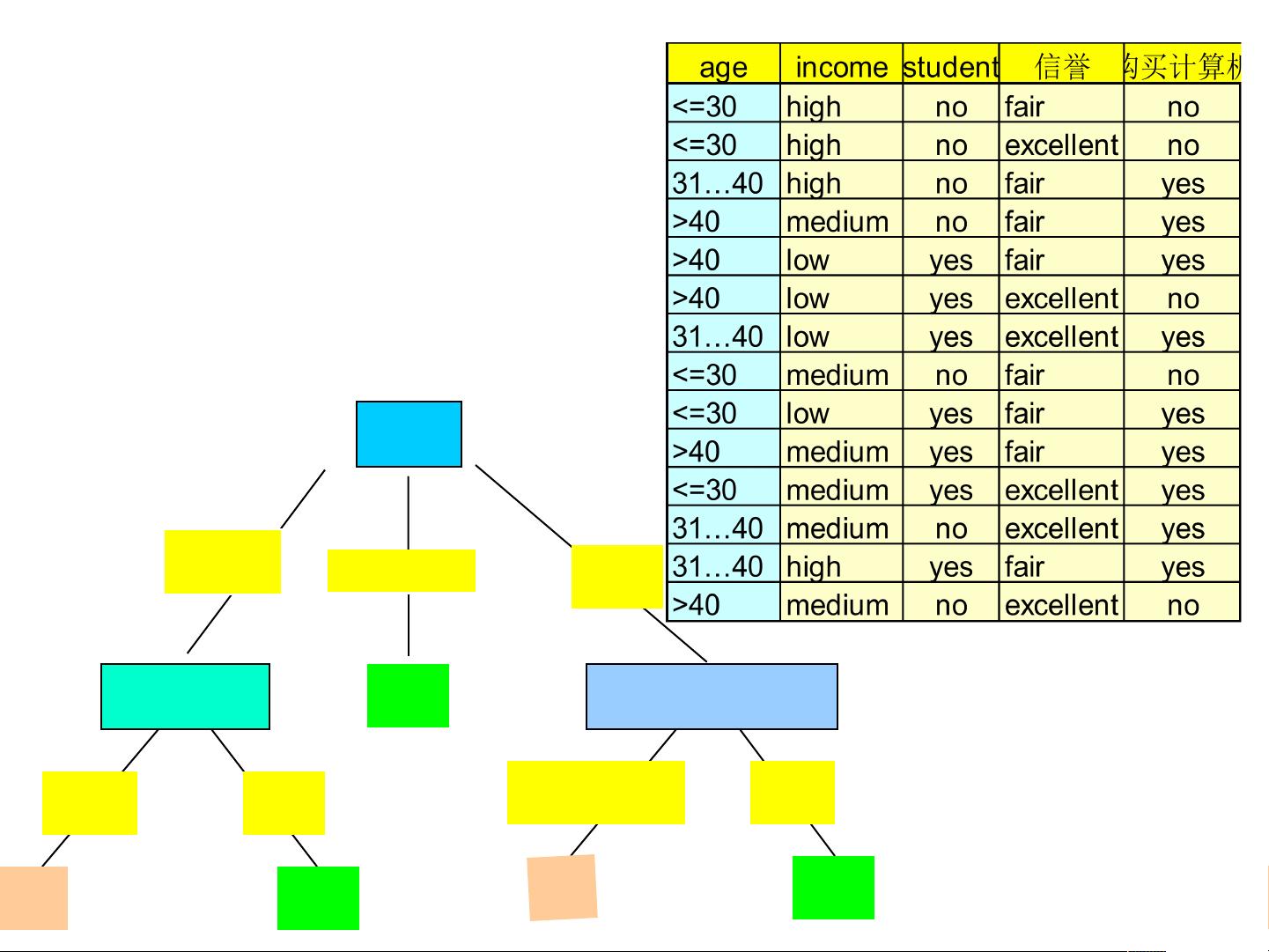
决策树归纳: 例子
age?
overcast
student? credit rating?
<=30
>40
no yes
yes
yes
31..40
no
fairexcellent
yesno
训练集: 购买计算机
结果:




剩余90页未读,继续阅读
相关推荐






文档优选
- 粉丝: 99
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全面详实的大学生电工实习报告汇总
- 利用极光推送实现App间的消息传递
- 基于JavaScript的节点天气网站开发教程
- 三星贴片机1+1SMT制程方案详细介绍
- PCA与SVM结合的机器学习分类方法
- 钱能版C++课后习题完整答案解析
- 拼音检索ListView:实现快速拼音排序功能
- 手机mp3音量提升神器:mp3Trim使用指南
- 《自动控制原理第二版》习题答案解析
- 广西移动数据库脚本文件详解
- 谭浩强C语言与C++教材PDF版下载
- 汽车电器及电子技术实验操作手册下载
- 2008通信定额概预算教程:快速入门指南
- 流行的表情打分评论特效:实现QQ风格互动
- 使用Winform实现GDI+图像处理与鼠标交互
- Python环境配置教程:安装Tkinter和TTk
