斯坦福大学机器学习公开课笔记1:线性回归
需积分: 9 101 浏览量
更新于2024-07-21
1
收藏 932KB DOC 举报
"斯坦福大学公开课机器学习讲义note1翻译"
这篇机器学习讲义主要涵盖了监督式学习的基本概念,以斯坦福大学CS229课程的形式呈现。监督式学习是一种人工智能方法,其中算法通过已标记的数据(即训练集)来学习模型,以便对未知数据进行预测。讲义以波特兰房屋价格预测为例,解释了监督学习的核心思想。
在监督学习中,我们有一组数据集,其中包括输入变量(特征)和输出变量(目标变量)。在房屋价格的例子中,输入变量是房子的面积(记为x)和卧室数量(记为x2),输出变量是价格(记为y)。数据集由多个训练样本组成,每个样本都有对应的输入输出对((x, y))。
为了建立预测模型,我们需要一个函数或假设h,它能将输入x映射到输出y。在这个例子中,我们考虑的是回归问题,因为价格是连续的数值。如果目标变量是离散的,那么问题就变成了分类问题。
讲义特别提到了线性回归作为初始模型,这是最简单的预测函数形式。线性回归假设输出y可以近似地表示为输入x的线性组合,即h(x) = θ0 + θ1*x1 + θ2*x2,其中θ0、θ1和θ2是待学习的参数。这里的θ0称为偏置项,θ1和θ2是与特征x1和x2对应的权重。
线性回归模型的构建是通过优化算法来确定最佳的θ参数,以最小化预测值与真实值之间的误差。这个过程通常使用梯度下降或正规方程等方法来求解。一旦找到最优的θ,我们就可以使用这个模型对新的房屋数据进行价格预测。
此外,讲义还暗示了特征选择的重要性,指出在实际问题中,我们可以根据领域知识添加更多的特征,如壁炉、浴室数量等,以提高模型的预测能力。随着特征数量的增加,模型复杂度也会提高,这可能带来过拟合的风险,因此需要通过正则化等技术来平衡模型的复杂性和泛化性能。
总结来说,这篇讲义介绍了监督学习的基础,包括回归问题、线性回归模型以及参数学习的过程,这些都是机器学习入门的重要概念。通过理解这些基本原理,学习者能够为进一步探索更复杂的机器学习算法打下坚实基础。
可以很容易的证明上述的更新规则算法的运算量仅仅是 (对 J 的初始化定义)。
因此这是一个简单的梯度下降算法对于原始成本函数 J。这个方法注重每一个训练样本在训
练过程中的每一步,所以也被叫做“批量梯度下降”。注意,梯度下降算法容易受到局部最
小值的影响,这个优化问题我们对于线性回归算法只有一个目标就是找到最合适的,因此
梯度下降算法总是收敛于全局最小值。(将设学习率 α 不是很大)实际上,J 是一个凸函数。
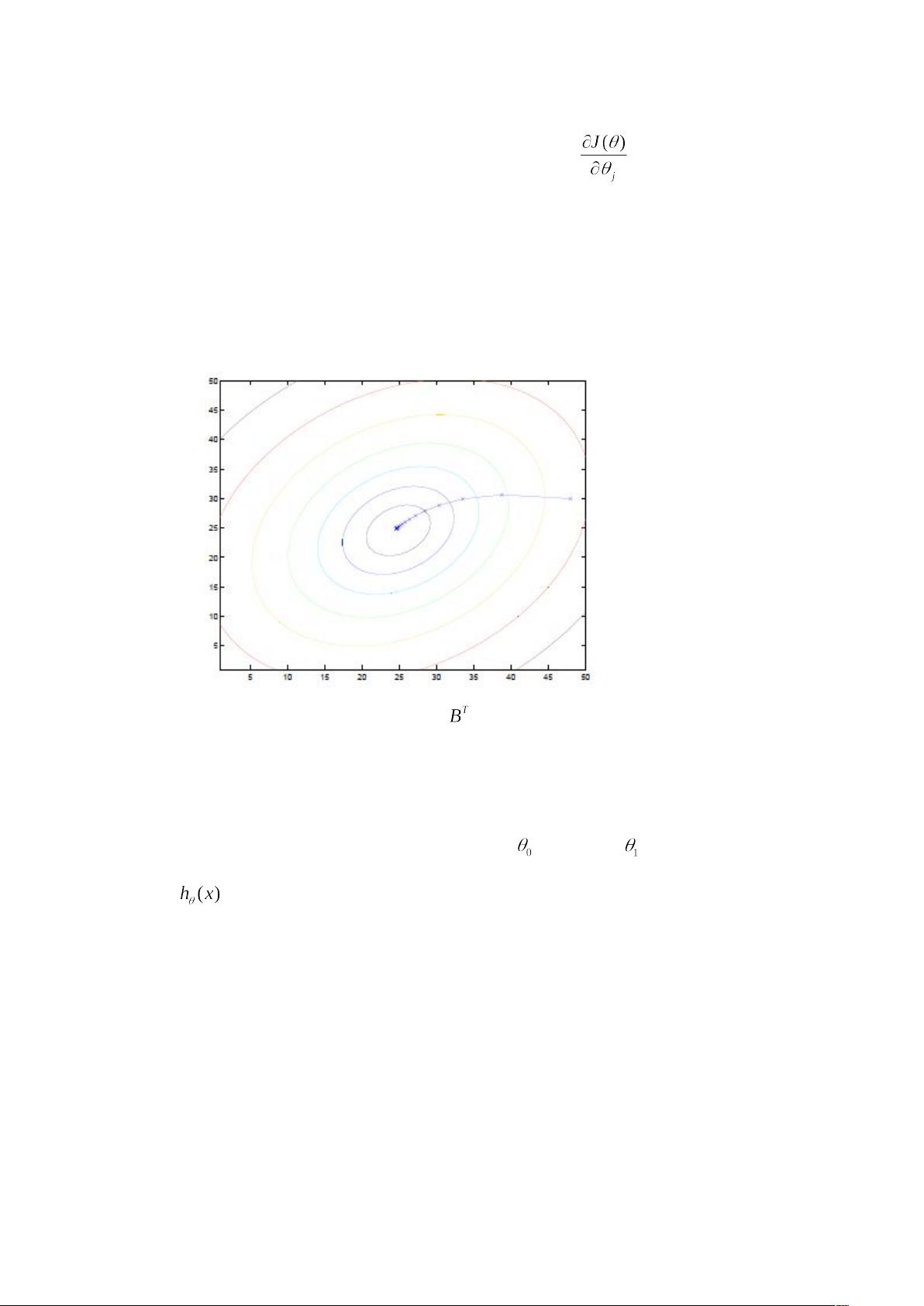
这里我们有一个梯度下降算法的例子,是使这个二次函数取得最小值。
这些椭圆表示了这个二次函数的等高线。这个紫色的线条表示的是取得最小值的轨迹,
初始化(48,30)。这个 X 标识出来在图中在梯度下降算法计算出的每个 θ 值,并且用
实线连接起来。
当我们运行批量梯度算法去计算 θ 在我们以前的数据集去估计房子的价格
使用房子的价格和房子面积的函数,我们得到 =71.27, =0.1345.如果我
们把 当作 x(面积)的函数,使用训练样本中的数据,我们能得到下面这
张图:
剩余24页未读,继续阅读
137 浏览量
2015-05-04 上传
2015-05-04 上传
2013-09-03 上传
2015-05-24 上传
2013-05-16 上传
2017-11-24 上传

小小菜鸟一只
- 粉丝: 608
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
