PRML:概率与线性模型在机器学习中的关键应用
需积分: 0 200 浏览量
更新于2024-07-01
1
收藏 11.56MB PDF 举报
《PRML模式识别和机器学习》(Chinese Edition) 是马春鹏所著的一本关于模式识别和机器学习的经典教材,它在中文环境下深入介绍了该领域的核心概念和技术。本书的绪论部分以多项式曲线拟合为例,引导读者进入机器学习的世界,通过实例展示了如何运用统计方法对数据进行分析。
首先,章节1的"概率论"是基础,涵盖了概率密度、期望和协方差的概念。概率密度用来描述随机变量的取值可能性,期望则衡量一个随机变量的平均值,而协方差反映了两个随机变量之间的关联程度。接下来,作者引入了贝叶斯概率,它是基于贝叶斯定理的概率处理方式,强调在有限数据下更新先验知识的能力。书中还讨论了高斯分布,这是一种重要的连续随机变量模型,常用于建模数据的中心趋势和分散程度。
在"重新考察曲线拟合问题"部分,作者结合贝叶斯理论探讨了在不确定性存在的情况下,如何通过贝叶斯曲线拟合来优化模型。模型选择是一个关键话题,作者解释了如何在众多模型中选择最合适的,以及如何避免维度灾难,即随着特征数量增加导致模型复杂度急剧增加的问题。
决策论是机器学习中的重要组成部分,包括最小化错误分类率、期望损失等决策准则,以及如何在不同决策策略之间权衡。对于回归问题,损失函数的选择和优化也是讨论的重点。信息论的应用,如相对熵和互信息,提供了评估模型信息效率的方法。
此外,本书详细介绍了各种概率分布,如二元变量的Beta分布,多项式变量的狄利克雷分布,以及高斯分布及其衍生形式,如条件高斯分布、边缘高斯分布和混合高斯模型。这些分布是许多机器学习算法的基础。指数族分布的理论,包括最大似然估计、共轭先验等概念,也得到了详尽讲解。
非参数化方法,如核密度估计和近邻方法,是不依赖特定概率分布的模型,为数据建模提供了灵活性。回归的线性模型部分深入剖析了线性基函数模型、最小二乘法和正则化,以及贝叶斯线性回归中的参数分布和预测分布计算。
本书不仅提供理论知识,还配以丰富的练习题,帮助读者巩固所学,并在实践中提升技能。通过这些章节,读者能够掌握模式识别和机器学习的核心原理,并应用于实际问题解决中。
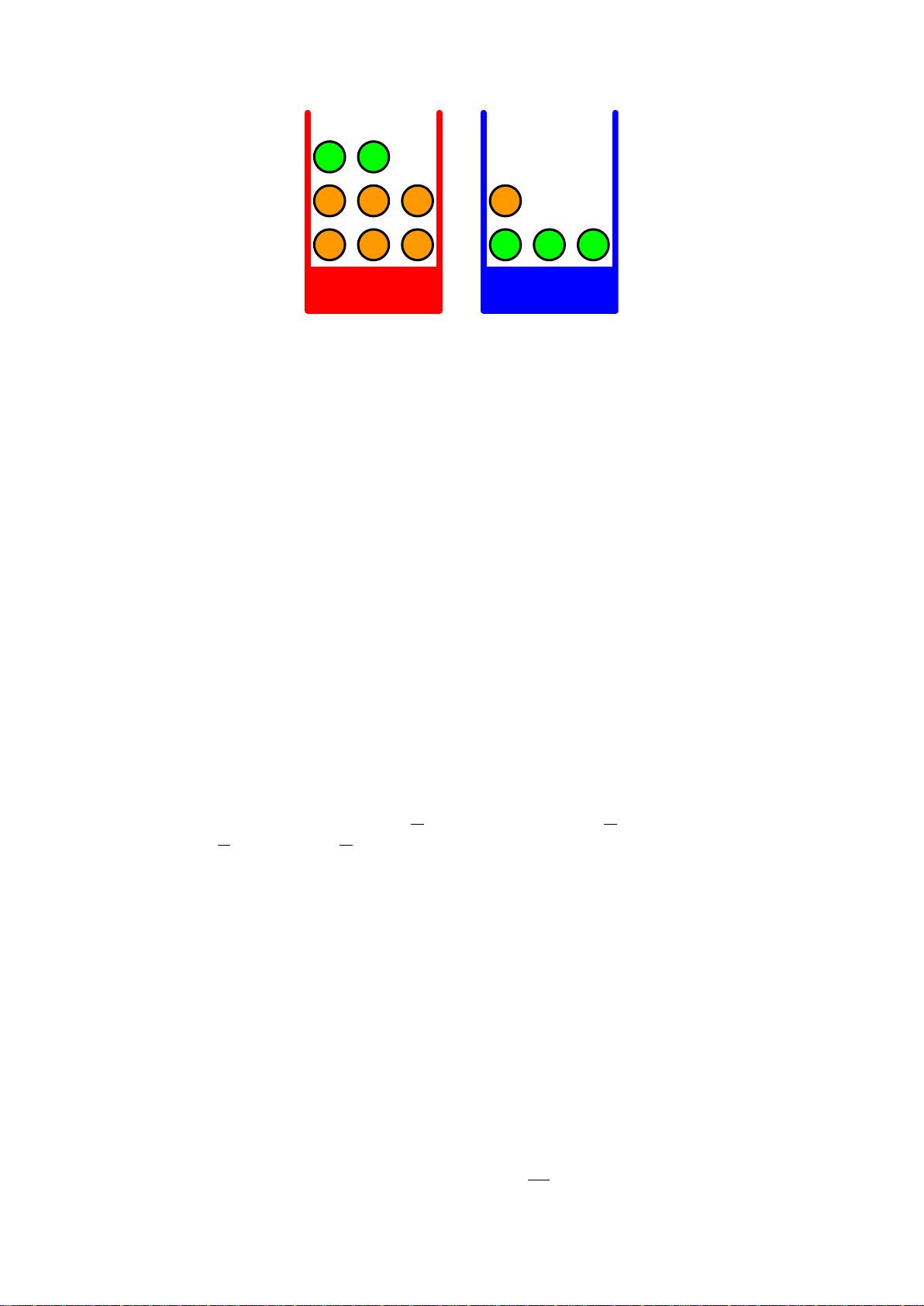
图 1.9: 我们使⽤⼀个简单的例⼦来说明概率论的基本思想。有两个不同颜⾊的盒⼦,每个盒⼦中都有⽔
果,苹果⽤绿⾊表⽰,橘⼦⽤橙⾊表⽰。
⽬前我们关于多项式拟合的讨论⼤量地依赖于直觉。我们现在寻找⼀个更加形式化的⽅法解
决模式识别中的问题。我们要使⽤概率论的⽅法。概率论不仅提供了本书后续⼏乎所有章节的
基础,它也能让我们更深刻地理解本章中我们通过多项式拟合的问题引出的重要概念,能让我
们把这些概念扩展到更复杂的情况。
1.2 概率论
在模式识别领域的⼀个关键概念是不确定性的概念。它可以由测量的误差引起,也可以由数
据集的有限⼤⼩引起。概率论提供了⼀个合理的框架,⽤来对不确定性进⾏量化和计算。概率
论还构成了模式识别的⼀个中⼼基础。当与决策论(1.5节讨论)结合,概率论让我们能够根据
所有能得到的信息做出最优的预测,即使信息可能是不完全的或者是含糊的。
我们将通过⼀个简单的例⼦介绍概率论的基本概念。假设我们由两个盒⼦,⼀个红⾊的,⼀
个蓝⾊的,红盒⼦中有2个苹果和6个橘⼦,蓝盒⼦中有3个苹果和1个橘⼦(如图1.9所⽰)。现
在假定我们随机选择⼀个盒⼦,从这个盒⼦中我们随机选择⼀个⽔果,观察⼀下选择了哪种⽔
果,然后放回盒⼦中。假设我们重复这个过程很多次。假设我们在40%的时间中选择红盒⼦,
在60%的时间中选择蓝盒⼦,并且我们选择盒⼦中的⽔果时是等可能选择的。
在这个例⼦中,我们要选择的盒⼦的颜⾊是⼀个随机变量,记作B。这个随机变量可以取两
个值中的⼀个,即r(对应红盒⼦)或b(对应蓝盒⼦)。类似地,⽔果的种类也是⼀个随机变
量,记作F 。它可以取a(苹果)或者o(橘⼦)。
开始阶段,我们把⼀个事件的概率定义为事件发⽣的次数与试验总数的⽐值,假设总试验次
数趋于⽆穷。因此选择红盒⼦的概率为
4
10
,选择蓝盒⼦的概率为
6
10
。我们把这些概率分布记
作p(B = r) =
4
10
和p(B = b) =
6
10
。注意,根据定义,概率⼀定位于区间[0, 1]内。并且,如果事
件是相互独⽴的,并且包含所有可能的输出(例如在这个例⼦中,盒⼦⼀定要么是红⾊,要么
是蓝⾊),那么我们看到那些事件的概率的和⼀定等于1。
我们现在可以问这样的问题:选择到苹果的整体概率是多少?或者,假设我们选择了橘⼦,
我们选择的盒⼦是蓝盒⼦的概率是多少?我们可以回答这种问题,事实上也可以回答与模式识
别相关的⽐这些复杂得多的问题。前提是我们掌握了概率论的两个基本规则:加和规则(sum
rule)、乘积规则(product rule)。获得了这些规则之后,我们将重新回到我们的⽔果盒⼦的例
⼦中。
为了推导概率的规则,考虑图1.10所⽰的稍微⼀般⼀些的情形。这个例⼦涉及到两个随
机变量X和Y (例如可以是上⾯例⼦中“盒⼦”和“⽔果”的随机变量)。我们假设X可以取任意
的x
i
,其中i = 1, . . . , M ,并且Y 可以取任意的y
j
,其中j = 1, . . . , L。考虑N 次试验,其中我们
对X和Y 都进⾏取样,把X = x
i
且Y = y
j
的试验的数量记作n
ij
。并且,把X取值x
i
(与Y 的取
值⽆关)的试验的数量记作c
i
,类似地,把Y 取值y
j
的试验的数量记作r
j
。
X取值x
i
且Y 取值y
j
的概率被记作p(X = x
i
, Y = y
j
),被称为X = x
i
和Y = y
j
的联合概率
(joint probability)。它的计算⽅法为落在单元格i, j的点的数量与点的总数的⽐值,即:
p(X = x
i
, Y = y
i
) =
n
ij
N
(1.5)
16


剩余475页未读,继续阅读
2022-08-04 上传
2022-08-03 上传
2021-05-25 上传
2022-08-03 上传
2024-07-10 上传
2022-08-03 上传
2022-12-02 上传

XU美伢
- 粉丝: 661
- 资源: 340
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
