ElasticSearch详解:全文检索框架与Solr对比
需积分: 9 95 浏览量
更新于2024-07-15
收藏 1.63MB PDF 举报
"ES笔记 20201012"
Elasticsearch(简称ES)是一种基于Java开发的全文检索框架,它构建于强大的Lucene库之上,具有源码开放、搜索实时和分布式架构的特点。ES对外提供的接口遵循RESTful风格,这使得与之交互变得简单且直观。在大数据检索领域,ES相比Solr更受欢迎,尤其在实时数据查询方面,ES表现出色。
Elasticsearch与Solr虽然都基于Lucene,但它们在某些关键特性上存在差异。Solr在处理离线数据查询时速度较快,而ES则在处理实时数据时更胜一筹。此外,Solr的集群管理需要依赖Zookeeper,而ES则内置了管理组件,简化了集群的部署和管理过程。
在海量数据检索的应用场景中,传统的数据库如MySQL(MyISAM和InnoDB引擎)往往无法满足需求。MySQL在面对大量数据时,其检索效率低下,不支持全文检索,而且无法实现实时性。而Elasticsearch正好填补了这一空白,它能高效地处理大规模数据的检索任务,支持全文搜索,并且可以快速响应新生成的数据,实现近乎实时的搜索体验。同时,ES还提供了搜索结果的高亮显示功能,增强了用户体验。
在安装Elasticsearch的过程中,可能会遇到一些问题,比如虚拟机环境下的内存不足。在这种情况下,需要调整JVM的内存配置,以避免因内存不足导致的错误。例如,在使用Docker部署ES和Kibana时,可以在Docker-compose.yml文件中配置相应的端口映射和环境变量,并确保ES服务能够正常启动和连接到指定的Elasticsearch实例。
在版本6.5.4的配置示例中,可以看到将Elasticsearch和Kibana的Docker镜像拉取并设置为自动重启,容器名分别为elasticsearch和kibana,分别暴露9200和5601端口。同时,通过环境变量设置Kibana连接的Elasticsearch URL,并声明Kibana依赖于Elasticsearch服务。然而,实际运行时可能会遇到如"max_virtual_memory_areas_vm.max_map_count"这样的错误,这需要在主机系统层面进行调整,以允许ES使用更多的虚拟内存区域。
Elasticsearch是一个强大的搜索引擎,尤其适用于大数据环境下的实时搜索和分析。其分布式特性和易于使用的REST API使其在众多全文检索解决方案中脱颖而出,而与Solr的对比则突显了其在实时性和易管理性上的优势。了解和掌握Elasticsearch的原理和使用方法,对于提升数据检索和分析能力至关重要。

byte:占1个字节
double:占8个字节
float:4个字节
half_float :2个字节
scaled_float :根据一个long和scaled来表达一个浮点类型 long 123 scaled:100->1.23
时间类型
date
布尔类型
booleanl类型,true/false
二进制类型
binary:但是存储是需要将二进制转换成Base64编码格式的字符串
范围类型greater than/less than equals
integer_range:赋值的时候,,不需要给定具体的值,给一个integer范围就可以了:
gte/lte/gt/lt
float_range:
long_range:
double_range:
date_range:
ip_range:
经纬度类型:
geo-point:存储经纬度
ip类型:
ip:可以存Ipv4或者Ipv6
4.5 创建索引并指定字段类型
PUT /book
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings": {
"novel":{
"properties":{
"name":{
"type":"text",
"analyzer":"ik_max_word",
"index":true,
"store":false
},
"author":{
"type":"keyword"
},
"price":{
"type":"long"
},
"count":{
"type":"long",
"index":false
},
"pubdate":{
"type":"date",
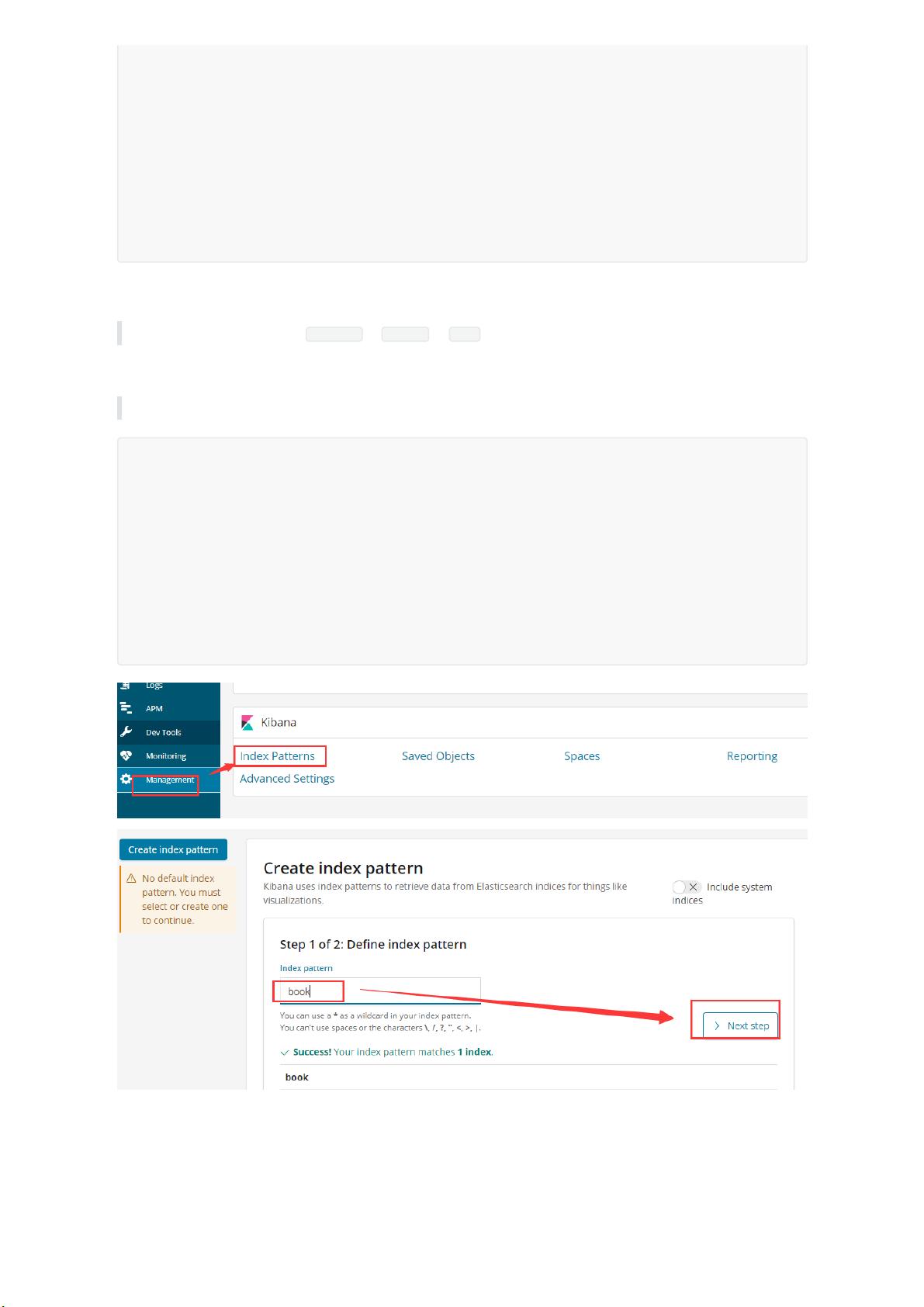
剩余41页未读,继续阅读
2019-11-01 上传
2022-01-11 上传
115 浏览量
116 浏览量
102 浏览量
261 浏览量
226 浏览量


我的狗子叫可乐
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- bint.h,实用的大整数运算!!!
- plyprotobuf:用于PLY的协议缓冲区词法分析器
- git-stats.zip
- html-css:HTML5和CSS3课程将教您如何使用最新版本的超文本标记语言(HTML)和级联样式表(CSS)创建网站
- 可视化项目
- farm-site:芝加哥Corner Farm的新网站
- 行业分类-设备装置-钢筋捆扎机捆扎圈数的控制方法及钢筋捆扎机.zip
- neon-py:适用于Python的NEON解析器
- 蓝桥杯 EDA 设计 模拟题全过程3.18.zip
- netbeans-colors-solarized, Solarized暗色方案,为NetBeans实现.zip
- 缩略图水印组件3.0Demo.zip
- RaphaelLaurent_3_11012021
- react-app7823074500126428
- laravel-qa:使用Laravel构建的问答应用程序
- spacy-graphql:使用GraphQL查询spaCy的语言注释
- 机械全部计算公式excel自动计算)
