Java全栈知识点:数据结构与算法解析
需积分: 0 190 浏览量
更新于2024-08-03
收藏 674KB PDF 举报
"Java 全栈知识点问题汇总,涵盖了数据结构和算法的相关内容"
在Java全栈开发中,数据结构和算法是至关重要的基础知识。数组是最基础的数据结构,它提供了通过下标快速访问元素的能力,但受限于固定长度和对增删改操作的不便。为了解决这些问题,人们发展出了多种数据结构。
二分查找是一种高效的搜索算法,适用于有序数组,能显著减少查找时间。然而,对于无序数组,通常需要遍历整个数组,效率较低。链表虽然在插入和删除上有优势,但在查找上性能不佳,因为它需要线性遍历。
哈希表结合了数组和链表的优点,通过散列函数实现快速查找,但其性能依赖于哈希函数的质量和冲突处理机制。当数据规模增大时,哈希表可能会遇到空间效率和查找效率的问题。
二叉查找树(BST)是另一种常见的数据结构,它保证了左子树的所有节点小于根节点,右子树的所有节点大于根节点。然而,如果树不平衡(例如,退化成链表),查找效率会降低。AVL树是为了解决这个问题而引入的,它是一种自平衡的二叉查找树,强制保持所有节点的左右子树高度差不超过1,从而确保查找效率。尽管AVL树的查找速度快,但频繁的旋转操作可能导致插入和删除操作变得昂贵。
红黑树作为AVL树的变体,允许更大的不平衡,牺牲了一些查找速度以换取更好的插入和删除性能。红黑树的每个节点都带有颜色属性,遵循特定的规则以保持树的平衡,从而减少旋转次数。这使得红黑树成为通用性更强的数据结构,尤其适用于需要频繁执行搜索、插入和删除操作的场景。
多路查找树(如B树)是为了解决大规模数据存储中的索引查询问题。B树的特点是每个节点可以有多个子节点,降低了树的深度,减少了磁盘I/O,提高了查询效率。相比于二叉查找树,B树更适合于存储在外部存储介质上的数据,因为它们能减少磁盘读写的次数,提高性能。
总结来说,Java全栈开发中的数据结构选择需要根据具体的应用场景来决定。不同的数据结构有各自的优缺点,如数组的快速访问,链表的动态扩展,哈希表的快速查找,以及各种平衡二叉树在查找、插入和删除操作上的权衡。理解这些数据结构及其内在原理,对于优化代码性能和解决实际问题至关重要。在实际编程中,开发者需要根据数据的特性以及预期的操作频率来灵活选择合适的数据结构,以实现最优的解决方案。
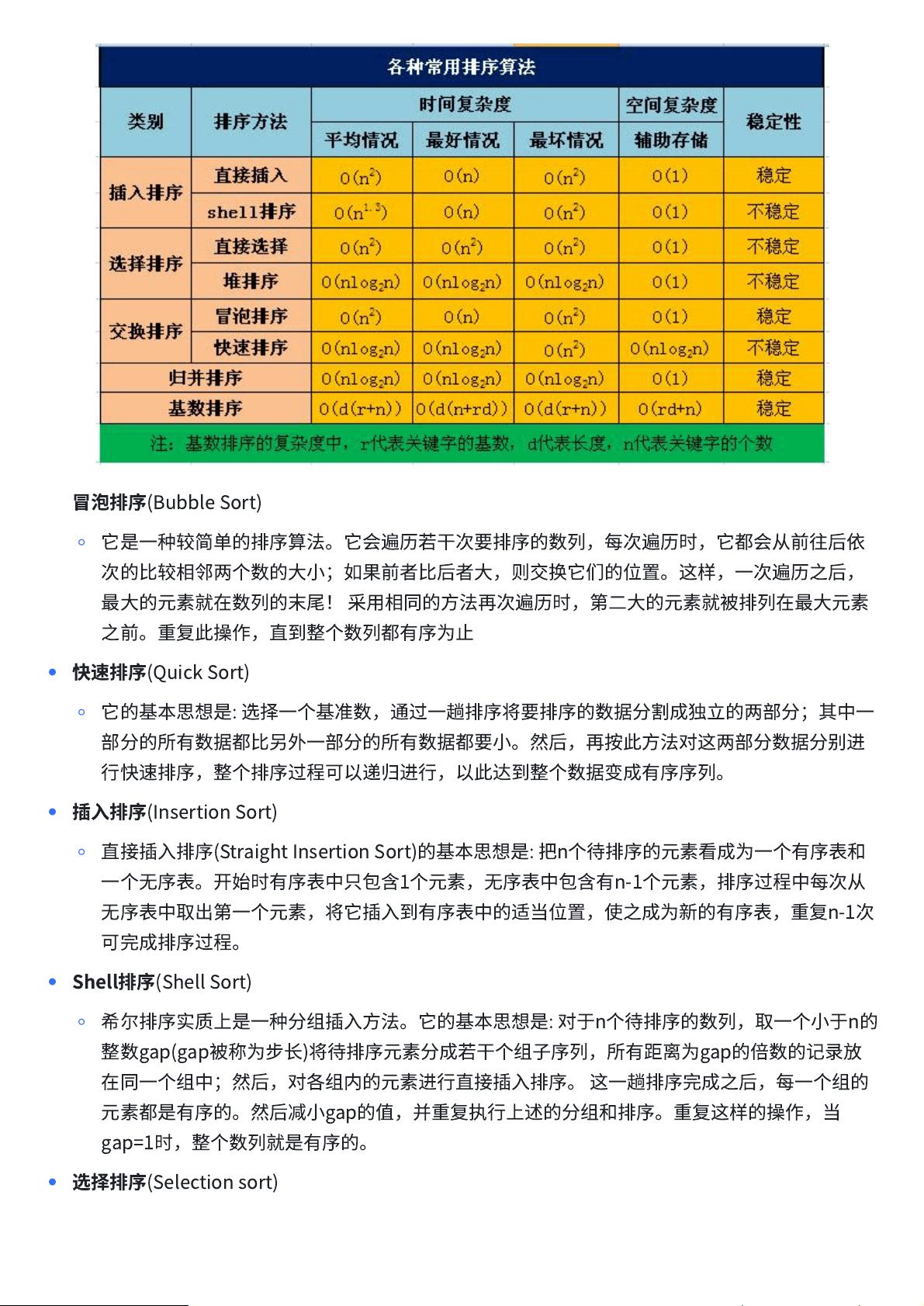
•
冒
泡
排
序
(BubbleSort)
◦
它
是
⼀
种
较
简
单
的
排
序
算
法
。
它
会
遍
历
若
⼲
次
要
排
序
的
数
列
,
每
次
遍
历
时
,
它
都
会
从
前
往
后
依
次
的
⽐
较
相
邻
两个
数
的
⼤
⼩
;
如
果
前
者
⽐
后
者
⼤
,
则
交
换
它
们
的
位
置
。
这
样
,
⼀
次
遍
历
之
后
,
最
⼤
的
元
素
就
在
数
列
的
末
尾
!
采
⽤
相
同
的
⽅
法
再
次
遍
历
时
,
第
⼆
⼤
的
元
素
就
被
排
列
在
最
⼤
元
素
之
前
。
重
复
此
操
作
,
直
到
整
个
数
列
都
有
序
为
⽌
•
快
速
排
序
(QuickSort)
◦
它
的
基
本
思
想
是
:
选
择
⼀个
基
准
数
,
通过
⼀
趟
排
序
将
要
排
序
的
数
据
分割
成
独
⽴
的
两
部
分
;
其
中⼀
部
分
的
所
有
数
据
都
⽐
另
外
⼀
部
分
的
所
有
数
据
都
要
⼩
。
然
后
,
再
按
此
⽅
法
对
这
两
部
分
数
据
分别
进
⾏
快
速
排
序
,
整
个
排
序
过
程
可
以
递
归
进
⾏
,
以
此
达
到
整
个
数
据
变
成
有
序序
列
。
•
插
⼊
排
序
(InsertionSort)
◦
直
接
插
⼊
排
序
(StraightInsertionSort)
的
基
本
思
想
是
:
把
n
个
待
排
序
的
元
素
看
成
为⼀个
有
序
表
和
⼀个
⽆
序
表
。
开
始
时
有
序
表
中
只
包
含
1
个
元
素
,
⽆
序
表
中
包
含
有
n-1
个
元
素
,
排
序
过
程
中
每
次
从
⽆
序
表
中
取
出
第
⼀个
元
素
,
将
它
插
⼊
到
有
序
表
中
的
适
当
位
置
,
使
之
成
为
新
的
有
序
表
,
重
复
n-1
次
可
完
成
排
序
过
程
。
•
Shell
排
序
(ShellSort)
◦
希
尔
排
序
实
质
上
是
⼀
种
分
组
插
⼊
⽅
法
。
它
的
基
本
思
想
是
:
对
于
n
个
待
排
序
的
数
列
,
取
⼀个
⼩
于
n
的
整数
gap(gap
被
称
为
步
⻓
)
将
待
排
序
元
素
分
成
若
⼲
个
组
⼦
序
列
,
所
有
距
离
为
gap
的
倍
数
的
记
录
放
在
同
⼀个
组
中
;
然
后
,
对
各
组
内
的
元
素
进
⾏
直
接
插
⼊
排
序
。
这
⼀
趟
排
序
完
成
之
后
,
每
⼀个
组
的
元
素
都
是
有
序
的
。
然
后
减
⼩
gap
的
值
,
并
重
复
执
⾏
上
述
的
分
组
和
排
序
。
重
复
这
样
的
操
作
,
当
gap=1
时
,
整
个
数
列
就
是
有
序
的
。
•
选
择排
序
(Selectionsort)
剩余10页未读,继续阅读
2023-09-16 上传
2023-07-30 上传
2023-05-24 上传
2023-06-11 上传
2023-09-23 上传
2024-03-09 上传
2023-10-06 上传

weishaoonly
- 粉丝: 135
- 资源: 1381
 我的内容管理
展开
我的内容管理
展开







最新资源
- ExtJS 2.0 入门教程与开发指南
- 基于TMS320F2812的能量回馈调速系统设计
- SIP协议详解:RFC3261与即时消息RFC3428
- DM642与CMOS图像传感器接口设计与实现
- Windows Embedded CE6.0安装与开发环境搭建指南
- Eclipse插件开发入门与实践指南
- IEEE 802.16-2004标准详解:固定无线宽带WiMax技术
- AIX平台上的数据库性能优化实战
- ESXi 4.1全面配置教程:从网络到安全与实用工具详解
- VMware ESXi Installable与vCenter Server 4.1 安装步骤详解
- TI MSP430超低功耗单片机选型与应用指南
- DOS环境下的DEBUG调试工具详细指南
- VMware vCenter Converter 4.2 安装与管理实战指南
- HP QTP与QC结合构建业务组件自动化测试框架
- JsEclipse安装配置全攻略
- Daubechies小波构造及MATLAB实现
