Python实现Apriori算法详解
110 浏览量
更新于2024-08-31
收藏 202KB PDF 举报
"这篇文章主要介绍了Python中Apriori算法的实现和原理,包括Apriori算法的基本概念、步骤以及如何在Python中实现该算法。"
Apriori算法是一种经典的关联规则学习算法,常用于市场篮子分析,以发现商品之间的关联性。在Python中实现Apriori算法,我们可以遵循以下步骤:
1. **Apriori算法简介**
Apriori算法的核心思想是基于频繁项集的性质,即如果一个项集是频繁的,那么它的所有子集也必须是频繁的。算法通过自底向上的方式,从单个项开始,逐渐增加项的数量,直到无法找到更频繁的项集为止。在每一步中,都会生成候选集(Candidate Set),并检查这些候选集在数据集中的支持度,以确定频繁项集。
2. **Apriori算法步骤**
- **初始化**: 确定最小支持度阈值,这将决定哪些项集被视为频繁的。一般情况下,这个阈值是根据业务需求设定的。
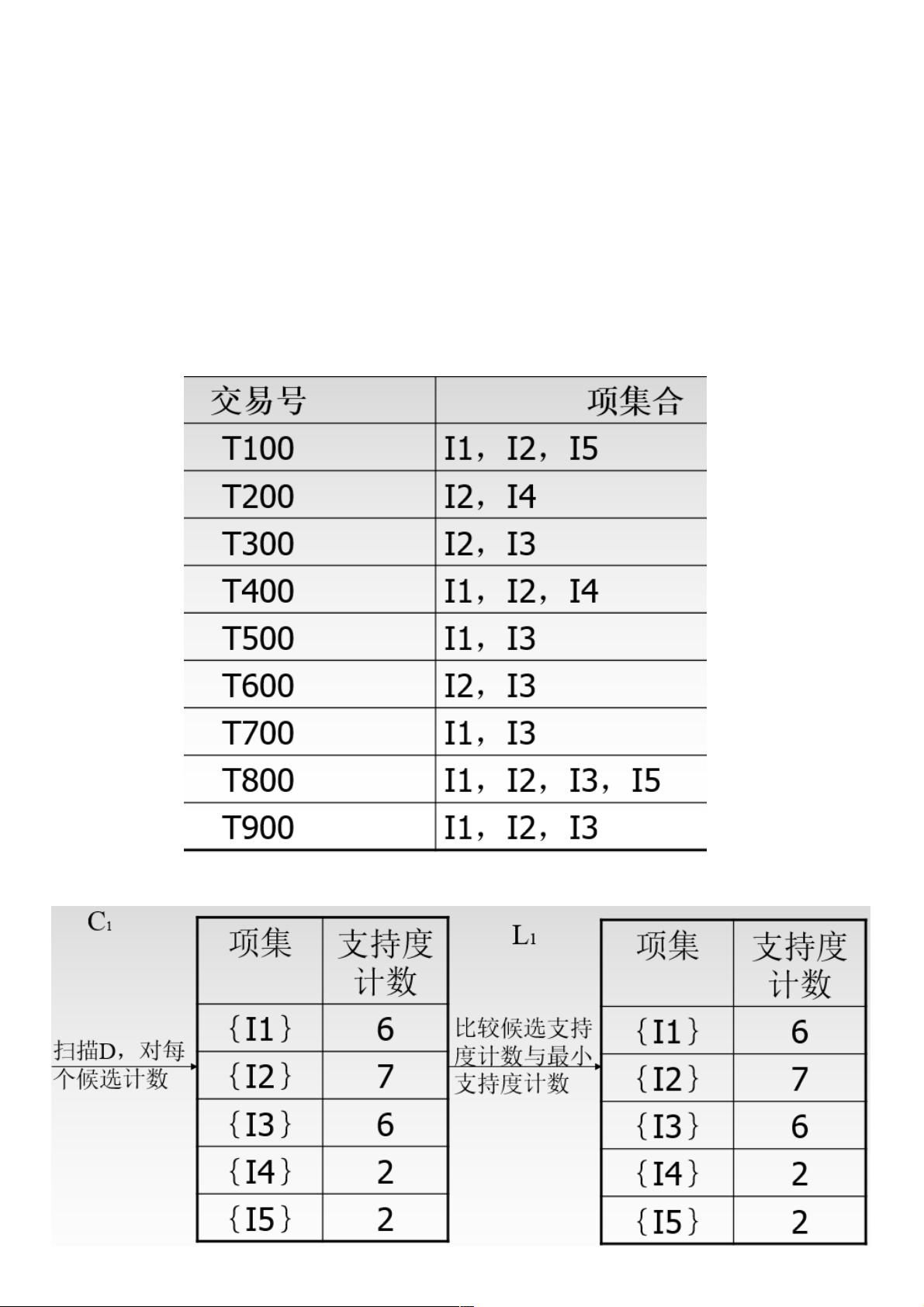
- **生成L1**: 扫描交易数据,找出所有单个项的支持度,将支持度大于阈值的项放入L1(频繁1-项集)。
- **生成C2**: 从L1中生成所有可能的2-项集作为C2(候选2-项集)。
- **计算支持度**: 对C2中的每个项集,再次扫描数据计算其支持度,如果支持度大于阈值,则加入到L2中。
- **迭代过程**: 重复上述步骤,生成更高阶的频繁项集(L3, L4等),直到无法找到新的频繁项集。
3. **Python实现**
在Python中,可以使用`pandas`库处理数据,`itertools`库生成所有可能的项集组合,以及自定义函数计算支持度和关联规则。以下是一个简单的Apriori算法Python实现框架:
```python
import pandas as pd
from itertools import combinations
def generate_frequent_itemsets(transactions, min_support):
# 初始化L1
L = [set(item) for item in transactions]
frequent_itemsets = {frozenset(L[0]): transactions[L[0] in transactions]}
# 迭代生成更高阶的频繁项集
k = 2
while len(frequent_itemsets) > 0:
new_candidates = create_candidates(L, k)
L, frequent_itemsets = update_frequent_itemsets(new_candidates, transactions, min_support)
k += 1
return frequent_itemsets
def create_candidates(L, k):
# 生成k-项集的候选集
...
def update_frequent_itemsets(candidates, transactions, min_support):
# 计算支持度并更新频繁项集
...
```
实际应用中,还需要考虑优化,如使用位操作来存储项集和计算支持度,以提高性能。
4. **Apriori算法的优缺点**
- 优点:Apriori算法简单明了,易于理解,且适用于离线分析。
- 缺点:当项集数量巨大时,可能会产生大量的候选集,导致效率低下和内存消耗过大。此外,Apriori算法只适用于挖掘频繁项集,不直接提供强关联规则。
Python中的Apriori算法实现涉及到对数据的处理、频繁项集的生成以及支持度的计算。通过理解算法原理,并结合Python编程,可以有效地发现数据中的关联规则。然而,实际应用中可能需要结合其他优化策略,如FP-Growth或Eclat算法,以提高效率。
python中中Apriori算法实现讲解算法实现讲解
给大家详细讲解一下Apriori 算法在python中的实现过程,有需要的朋友收藏一下本片文章吧。
本文主要给大家讲解了Apriori算法的基础知识以及Apriori算法python中的实现过程,以下是所有内容:
1. Apriori算法简介算法简介
Apriori算法是挖掘布尔关联规则频繁项集的算法。Apriori算法利用频繁项集性质的先验知识,通过逐层搜索的迭代方法,即将K-
项集用于探察(k+1)项集,来穷尽数据集中的所有频繁项集。先找到频繁项集1-项集集合L1, 然后用L1找到频繁2-项集集合L2,
接着用L2找L3,知道找不到频繁K-项集,找到每个Lk需要一次数据库扫描。注意:频繁项集的所有非空子集也必须是频繁的。
Apriori性质通过减少搜索空间,来提高频繁项集逐层产生的效率。Apriori算法由连接和剪枝两个步骤组成。
2. Apriori算法步骤算法步骤
根据一个实例来解释:下图是一个交易单,I1至I5可看作5种商品。下面通过频繁项集合来找出关联规则。
假设我们的最小支持度阈值为2,即支持度计数小于2的都要删除。
上表第一行(第一项交易)表示:I1和I2和I5一起被购买。
下载后可阅读完整内容,剩余3页未读,立即下载
2022-06-01 上传
2022-05-11 上传
点击了解资源详情
2023-04-05 上传
点击了解资源详情
点击了解资源详情
2023-05-29 上传
2024-11-11 上传
2021-10-02 上传

weixin_38656064
- 粉丝: 10
- 资源: 932
 我的内容管理
展开
我的内容管理
展开







