"尚硅谷大数据技术之Hadoop(HDFS):产生背景、定义及优缺点"
需积分: 0 74 浏览量
更新于2024-01-23
收藏 15.25MB DOCX 举报
尚硅谷大数据技术之Hadoop(HDFS)是基于分布式文件管理系统的一个文件系统。它的产生背景是随着数据量逐渐增大,单个操作系统无法存储全部数据,需要将数据分配到多个操作系统管理的磁盘中。然而,这种分散的管理方式给文件的管理和维护带来了困难,因此迫切需要一种能够管理多台机器上文件的系统,这就是分布式文件管理系统,而HDFS则是其其中一种实现。
HDFS的定义是Hadoop Distributed File System的简称,它是一个分布式文件系统。它使用目录树来对文件进行定位,并通过多台服务器联合起来实现其功能。在HDFS中,集群中的不同服务器扮演着不同的角色。HDFS的适用场景是一次写入、多次读取的场景,并且不支持文件的修改。它非常适合用于数据分析,但不适合用于网盘应用。
HDFS具有一些优点和缺点。首先,它具有较高的可扩展性,可以根据需求向集群中添加更多的服务器,从而增加存储容量。其次,HDFS具有较高的容错性,即使集群中某些服务器发生故障,仍可以保证数据的可靠性和可访问性。此外,HDFS还支持数据的并行处理,能够提高处理效率。另外,HDFS还具有较好的数据局部性,它将数据存储在不同的服务器上,可以根据计算任务的位置和需求将计算任务分配到最接近数据的服务器上,减少了数据传输的开销。
然而,HDFS也存在一些缺点。首先,因为HDFS适合一次写入、多次读取的场景,不支持文件的修改,因此无法满足一些需要实时编辑和更新数据的应用需求。其次,由于HDFS并不适合存储小文件,小文件存储会浪费存储空间和降低系统性能。此外,HDFS在一些情况下可能会导致数据不一致的问题,需要通过一些额外的机制来保证数据的一致性。
综上所述,HDFS是一种基于分布式文件管理系统的文件系统,适用于一次写入、多次读取的大数据处理场景。它具有较高的可扩展性、容错性和处理效率,但不适合实时编辑和更新数据以及存储小文件。尽管存在一些缺点,但HDFS仍然是大数据处理中不可或缺的重要组成部分。

尚硅谷大数据技术之 Hadoop(HFDS 文件系统)
—————————————————————————————
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>
注意:如果 Eclipse/Idea 打印不出日志,在控制台上只显示
1.log4j:WARN No appenders could be found for logger (org.apach
e.hadoop.util.Shell).
2.log4j:WARN Please initialize the log4j system properly.
3.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#
noconfig for more info.
需要在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”,
在文件中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c]
- %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c]
- %m%n
6.创建包名:com.atguigu.hdfs
7.创建 HdfsClient 类
public class HdfsClient{
@Test
public void testMkdirs() throws IOException,
InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
// 配置在集群上运行
// configuration.set("fs.defaultFS",
"hdfs://hadoop102:9000");
// FileSystem fs = FileSystem.get(configuration);
FileSystem fs = FileSystem.get(new
URI("hdfs://hadoop102:9000"), configuration, "atguigu");
// 2 创建目录
fs.mkdirs(new Path("/1108/daxian/banzhang"));
// 3 关闭资源
fs.close();
}
}
8.执行程序
运行时需要配置用户名称,如图 3-7 所示
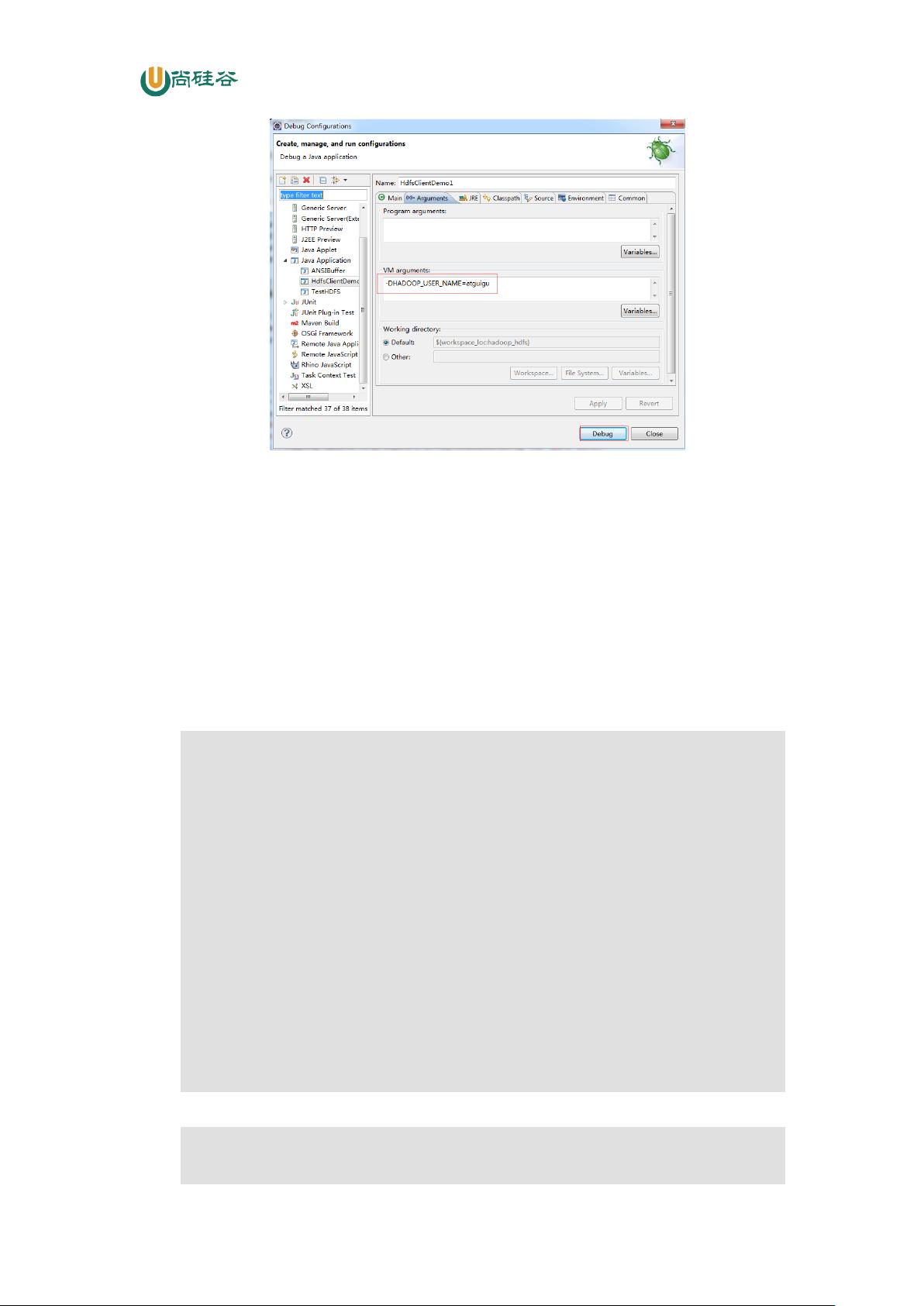
剩余46页未读,继续阅读
2022-08-03 上传
2022-08-04 上传
2023-07-05 上传
2023-07-11 上传
2023-07-11 上传
2023-07-29 上传
2023-06-08 上传
2024-09-03 上传

晕过前方
- 粉丝: 729
- 资源: 328
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
