HDFS入门教程:分布式文件系统原理与实践
"xq大数据学习技术文档是一个涵盖了2019年大数据技术学习要点的文档,特别适合初学者入门。文档中详细介绍了HDFS、Hive、HBase、Spark和Flink等关键技术,旨在帮助读者理解大数据处理的核心概念和工作流程。"
文档详细解析HDFS(Hadoop Distributed File System)的各个方面,这是Apache Hadoop项目的一部分,主要用于分布式存储。HDFS设计的核心理念是提供高容错性和高吞吐量的数据访问。以下是关于HDFS的关键知识点:
1. **HDFS概述**
- HDFS是一个分布式文件系统,允许在多台服务器上存储和处理大规模数据。
- 它通过一个全局的目录树结构提供文件定位服务,使得用户能够通过路径名访问文件。
2. **重要特性**
- **文件分块存储**:HDFS将大文件分成多个块进行存储,块的默认大小在hadoop2.x版本中为128MB,在旧版本中为64MB。
- **元数据管理**:文件的目录结构和分块信息由Namenode管理,它维护整个文件系统的目录树和文件Block信息。
- **副本机制**:每个Block可以在多个DataNode上保存多个副本,DataNode是实际存储数据的工作节点。
- **不支持文件修改**:HDFS设计为一次写入、多次读取的模式,不适用于需要频繁修改文件的应用场景。
3. **运作流程**
- **文件上传**:客户端首先与Namenode通信,确认文件不存在且父目录存在,然后获取Block应传输到的DataNode列表。
- **建立Pipeline**:客户端与DataNode A建立连接,A再依次与B、C建立连接,形成一个数据传输链路。
- **数据传输**:客户端将数据以Packet为单位发送给A,A转发给B,B再转发给C,同时保持应答队列以确认传输。
HDFS的这种设计保证了在大规模数据处理时的可靠性和效率,是大数据处理的基础。然而,由于其不支持文件修改的特性,HDFS并不适用于需要实时更新和小文件操作的应用。
对于其他标签提及的Hive、HBase、Spark和Flink,它们分别是大数据处理的不同组件或工具:
- **Hive** 是一个基于Hadoop的数据仓库工具,用于数据ETL(提取、转换、加载)和查询,提供SQL-like接口来处理存储在HDFS上的数据。
- **HBase** 是一个分布式、列式存储的NoSQL数据库,运行在HDFS之上,适合实时读写操作的大数据存储。
- **Spark** 是一个快速、通用且可扩展的大数据处理框架,支持批处理、交互式查询、实时流处理等多种计算模型。
- **Flink** 是一个开源流处理框架,专注于低延迟和事件驱动的数据处理,同时支持批处理和流处理。
这些工具共同构建了大数据生态系统,帮助企业处理、分析并从中提取价值。学习这些技术,可以为从事大数据领域工作打下坚实基础。
/;.@<;1<B;8>;1<@+9$持久化顺序编号目录节点
客户端与 " 断开连接后,该节点依旧存在,只是 V" 给该节点名称进行
顺序编号,主要用于同步和锁
;/;;.+9$临时目录节点
客户端与 " 断开连接后,该节点被删除
;/;;.+9B;8>;1<@+9$临时顺序编号目录节点
客户端与 " 断开连接后,该节点被删除,只是 V" 给该节点名称进行顺
序编号
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时 ,
zookeeper 会通知客户端
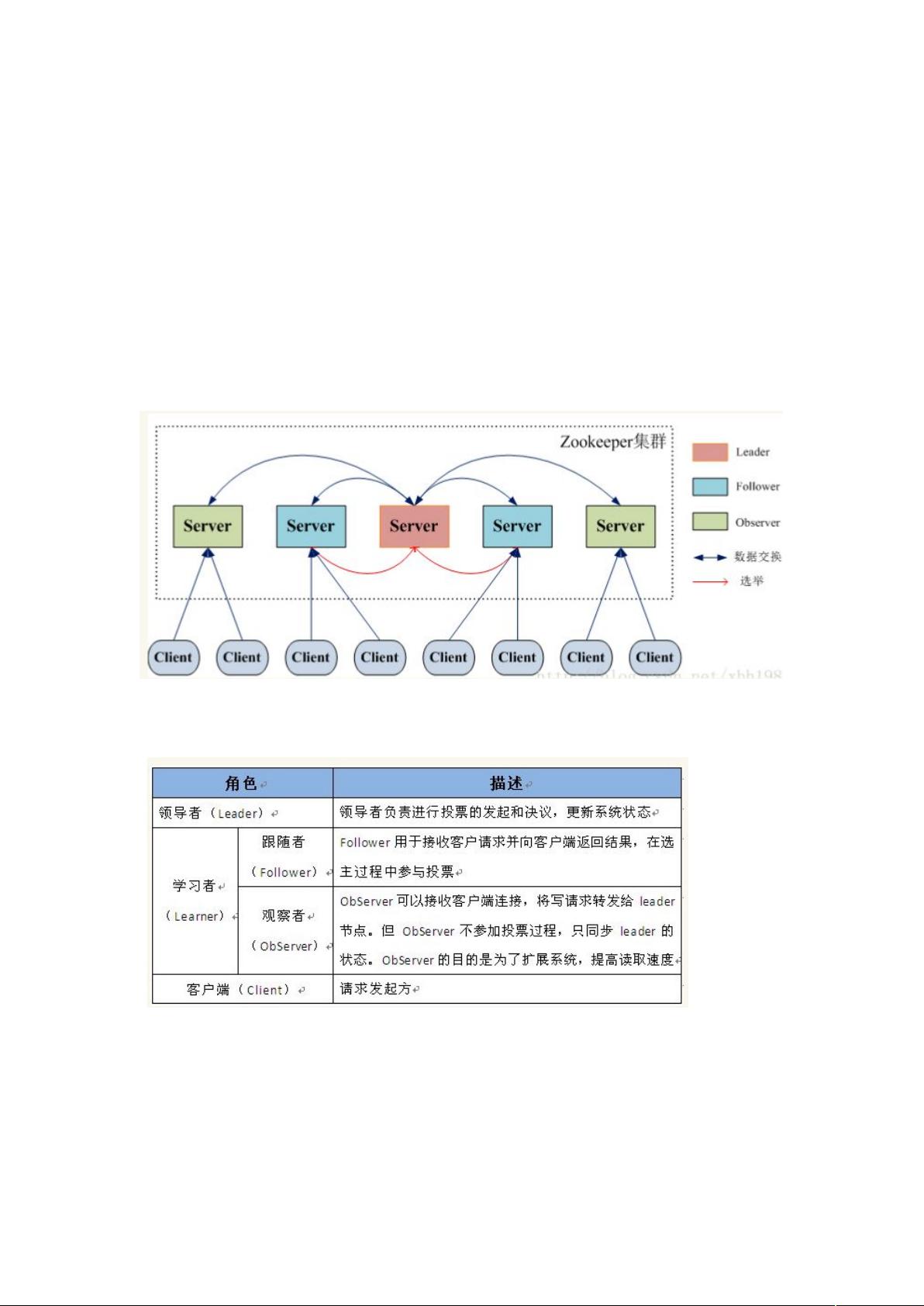
Zookeeper 的角色
W领导者("),负责进行投票的发起和决议,更新系统状态
W学习者(" "),包括跟随者(E")和观察者("4"),E" 用于接
受客户端请求并想客户端返回结果,在选主过程中参与投票
WC"4" 可以接受客户端连接,将写请求转发给 ",但 "4" 不参加投票过程,
只同步 " 的状态,"4" 的目的是为了扩展系统,提高读取速度
W客户端( #),请求发起方


剩余63页未读,继续阅读
2021-10-18 上传
2023-08-10 上传
2023-08-10 上传
2019-06-10 上传
2022-01-26 上传
2022-11-28 上传
2021-09-26 上传
2020-02-24 上传
2023-08-12 上传

xuqian1638
- 粉丝: 3
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
