Boosting算法详解:构建强分类器的迭代方法
版权申诉
125 浏览量
更新于2024-06-27
收藏 2MB PPTX 举报
"Boosting是一种集成学习方法,用于构建组合分类器。该方法通过一系列迭代步骤,逐步调整训练样本的权重,使得弱学习器能够聚焦于之前错误分类的样本,从而构建出一个强学习机。在Boosting的过程中,每个弱学习器都会对原始训练集中的样本赋予不同的权重,并根据其性能调整权重,最终通过加权组合多个弱分类器来生成强分类器。"
Boosting算法的核心思想是将多个弱分类器(表现稍逊的学习器)组合成一个强分类器。弱学习机通常是指那些具有轻微预测能力的模型,例如决策树或线性模型。Boosting算法的基本流程可以概括如下:
1. **初始化**:从原始训练数据集开始,所有样本的权重均等分配。
2. **迭代**:对于T轮迭代,每一轮执行以下操作:
- **权重调整**:根据上一轮弱分类器的分类结果,调整样本的权重。错误分类的样本权重增加,正确分类的样本权重减少。
- **训练弱分类器**:使用当前加权后的训练集训练一个新的弱学习器,它重点关注那些权重较高的样本。
- **评估与加权**:计算弱分类器的性能,根据其表现赋予一个权重。
3. **组合**:将所有T个弱学习器按照它们的权重进行加权组合,形成最终的强分类器。
在实际应用中,Boosting的典型代表是AdaBoost(Adaptive Boosting),它是一种广泛应用的Boosting方法。AdaBoost通过迭代调整样本权重,使得每个弱分类器在训练时更关注那些前一轮被错误分类的样本。随着迭代次数的增加,弱分类器逐渐关注并修正之前的错误,从而提高整体的分类性能。
Boosting的优势在于它可以有效地处理不平衡数据集,因为在后续的迭代中,错误分类的样本会获得更大的关注。同时,由于每次只关注一部分问题,弱分类器可以专注于特定的模式,而不是试图捕捉整个数据集的复杂性。
然而,Boosting也存在一些潜在的问题,如易受噪声样本影响(权重调整可能导致噪声样本权重过高)、过拟合风险以及计算成本较高(因为需要训练和组合多个模型)。为了缓解这些问题,实践中通常会采用正则化技术、限制弱学习器的复杂度或调整迭代次数等策略。
在Boosting的基础上,还发展出了其他变种,比如Gradient Boosting和XGBoost(Extreme Gradient Boosting),它们在优化方法、损失函数和树的分裂策略等方面做了改进,以提高效率和模型的泛化能力。
Boosting是一种强大的机器学习技术,通过迭代和权重调整,将多个弱学习器转化为一个性能优秀的强分类器。在实际应用中,Boosting已经成为解决分类问题和回归问题的重要工具,尤其在大数据和复杂模式识别领域展现了卓越的性能。
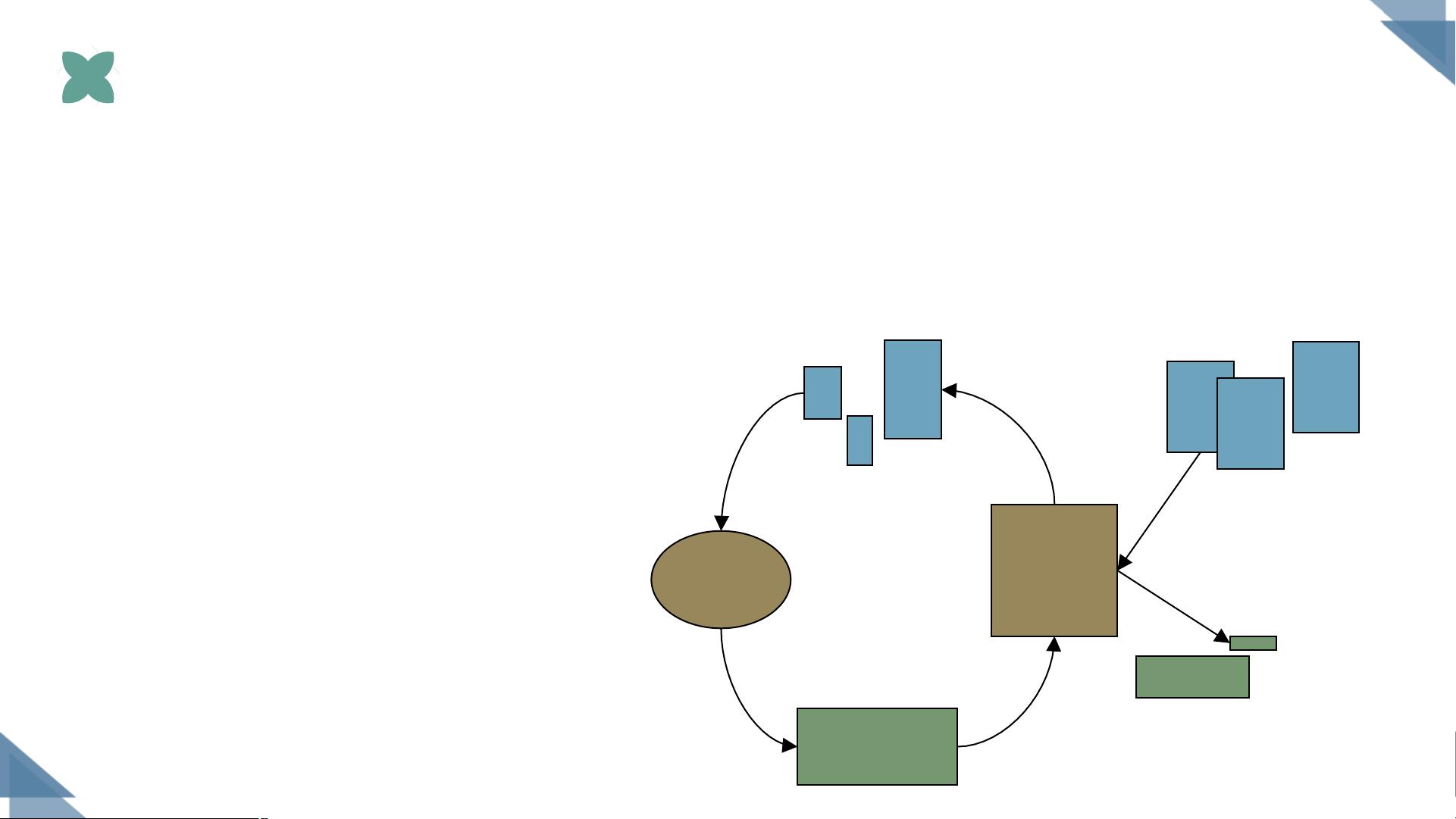
Boosting
是根据学习器的表现对训练样本分布进行调整,基于调整后的样本分布来训练下一个学习器,直至达到停
止条件,最总将T个学习器进行加权结合。
Boosting流程(loop2)
强学习机
弱学习机
原始训练集
加权后的训练集
加权后的假设
Y>3?1:-1
弱假设
剩余17页未读,继续阅读
2023-01-14 上传
2021-05-12 上传
2021-10-05 上传
2023-10-12 上传
2021-10-08 上传
2021-10-05 上传

知识世界
- 粉丝: 375
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- anmou cma chapter7
- goto-intial-commits-crx插件
- 46-1电子秒表E6.zip
- html5黑色大气的个人博客全屏滚动个人主页源码HTML+JS+CSS
- 易语言-易语言编写的微信多开软件
- hono-demo-1:OpenShift上的Eclipse Hono,Eclipse Che,EnMasse的完整堆栈示例
- React-ant-Webkit:该项目是和仓库Vue-Element-Webkit对应的一套后台系统,只是用的框架不一样 界面是一样的
- jenkins-seed:玩转Job DSL插件
- 即时前端
- 易语言变体型数据结构简单分析
- notes:用于学习android的简单笔记应用程序(带有材料设计)
- Github Improved-crx插件
- 蓝桥杯单片机模版程序(完整工程文件)
- Ti.LocationTrackerService:为Axway Titanium实现了Geotracking的前台服务
- FERMAT SystemC Parser-开源
- mohd-faizy.github.io:我的投资组合
