Spark特性与优势解析:内存计算、BDAS生态与运行模式
Spark是大数据处理领域的一款高效、灵活且易于使用的开源框架,主要设计用于加速大规模数据处理。其核心特性包括高可伸缩性、高容错性和内存计算能力,这使得Spark在处理迭代计算和需要快速响应的场景下表现出色。
Spark的生态体系被包含在BDAS(伯利克分析栈)中,与Hadoop生态体系并行存在。Hadoop生态系统拥有众多组件,如MapReduce、HDFS、HBase、Hive、Zookeeper、Pig和Sqoop等,而BDAS则由Spark、Shark(作为Hive的替代品)、BlinkDB以及Spark Streaming(一种实时处理框架,类似于Storm)等构成。这种多样化的组件结构提供了更广泛的数据处理解决方案。
Spark对比MapReduce的优势在于它的内存计算模型。MapReduce通常将中间结果写入HDFS,导致频繁的磁盘I/O,而Spark则将数据保留在内存中,显著提高了迭代计算的效率。此外,Spark的计算模型基于有向无环图(DAG),允许对任务进行优化,避免不必要的排序,减少计算开销。
Spark提供了丰富的编程接口,支持Scala、Python和Java等语言,使得开发者可以根据自己的需求和偏好选择合适的编程工具。同时,Spark提供了多种运行模式,包括Local模式(适用于测试和开发),Standalone模式(独立集群),以及在Yarn和Mesos上的部署,确保了Spark可以在不同的集群管理器上运行。
在运行时,Spark的工作机制是通过Driver程序启动多个Worker节点。Worker从文件系统加载数据,并将数据转化为RDD(弹性分布式数据集)。RDD是Spark的核心数据结构,它是不可变的、分区的记录集合。RDD可以通过集合转换、文件系统输入或父RDD转换来创建。RDD的两种主要计算类型是Transformation和Action。Transformation定义了数据转换,但并不立即执行,只有在触发Action操作时,之前的Transformation才会执行,产生最终结果。
相比于Hadoop中的Map和Reduce接口,Spark提供了更高级别的抽象,如RDD和DataFrame,简化了大数据处理的复杂性。DataFrame进一步抽象了RDD,提供了更加结构化的数据处理能力,使得SQL查询和数据分析更加便捷。
Spark是一个强大的大数据处理框架,它通过内存计算、高效的计算模型和丰富的编程接口,为大数据分析和实时处理提供了高效且易用的解决方案。无论是开发测试、独立集群还是在其他集群管理系统上,Spark都能灵活适应,展现出其在大数据领域的强大实力。
() ,-:延迟执行,一个 通过该操作产生的新的
时不会立即执行,只有等到 操作才会真正执行。
*) :提交 作业,当 时,,- 类型
的操作才会真正执行计算操作,然后产生最终结果输出。
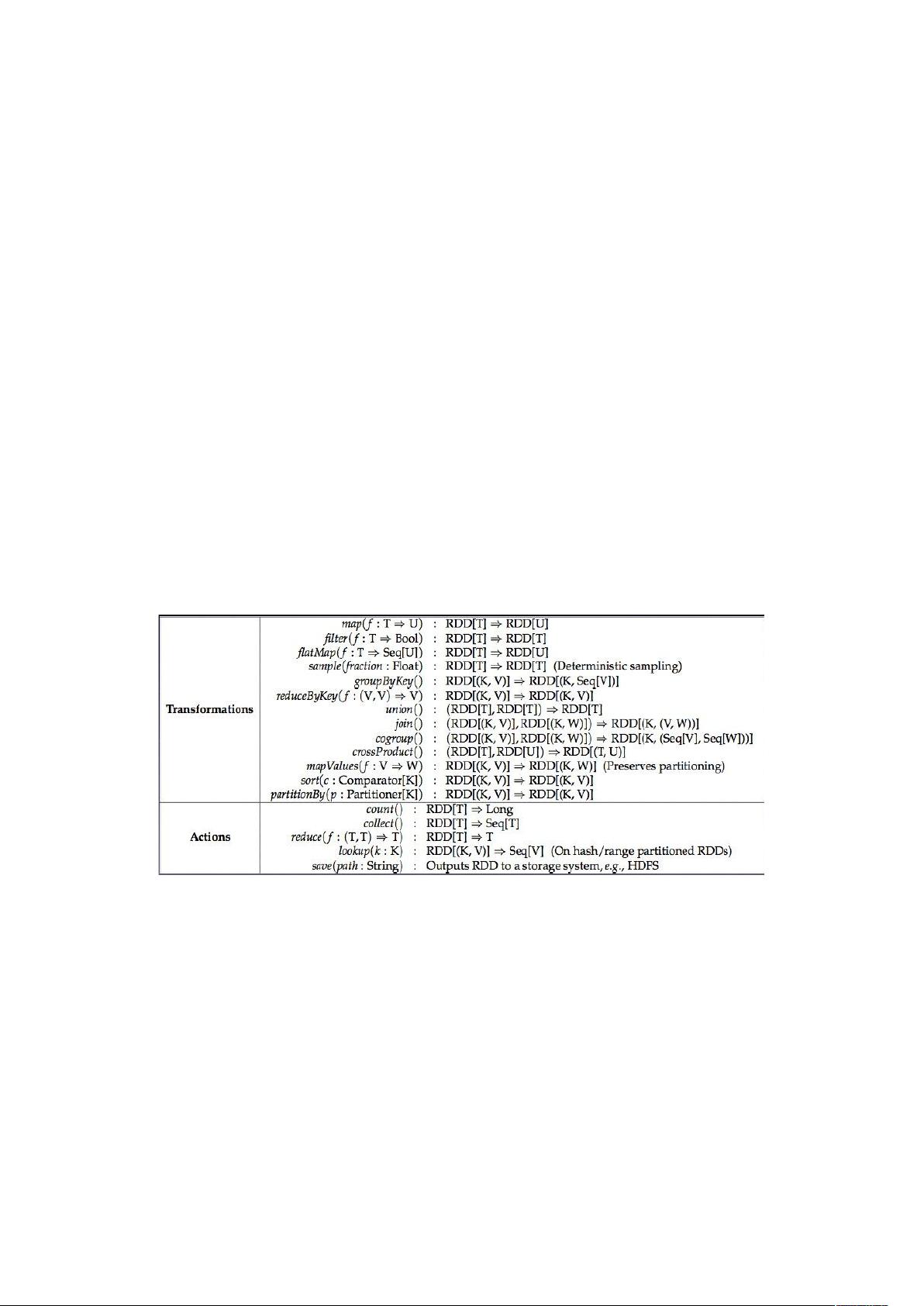
+) 提供处理的数据接口有 和 ,而 提供
的不仅仅有 和 还有更多对数据处理的接口,如图下
所示:
8. 容错 Lineage
1) 容错基本概念
每个 都会记录自己所依赖的父 ,一旦出现某个 的某些
丢失,可以通过并行计算迅速恢复
剩余22页未读,继续阅读
2019-01-05 上传
2020-12-10 上传
2018-06-01 上传
2018-06-01 上传
2019-12-20 上传
2023-07-30 上传
2022-06-29 上传

weixin_42349399
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
