联合无监督学习:深度、相机运动、光流与动态分割的协同竞争
需积分: 12 55 浏览量
更新于2024-07-17
收藏 2.74MB PDF 举报
"这篇文章是2018年CVPR会议上发表的一篇研究论文,名为‘[2018 CVPR] Competitive Collaboration’,探讨了如何使用生成对抗网络(Generative Adversarial Networks, GANs)来解决无监督学习中的几个关键问题,包括单目深度估计、相机运动估计、光流计算以及静态场景与动态目标的分割。论文指出这四个任务之间存在相互联系,可以相互促进以提高整体性能。"
在计算机视觉领域,单目深度估计是一项挑战性任务,它涉及从单个图像中推断出场景中每个像素的距离信息,而无需立体相机或深度传感器。通常,这种问题需要解决的问题是缺乏直接的深度信息,因此研究人员通常依赖于先验知识和几何约束来推理深度。
相机运动估计是另一个关键任务,它涉及到识别相机在连续帧之间的运动,这对于视频稳定、三维重建等应用至关重要。通过理解相机的运动,可以更准确地计算光流,即图像中像素在时间上的移动。
光流估计则关注于捕捉连续帧之间像素的运动,它是理解和解析动态视频的关键。它有助于跟踪物体、预测运动和进行运动分析。
该论文的创新之处在于提出了“竞争协作”框架(Competitive Collaboration),这是一种能够同时处理上述四个任务的神经网络架构。该框架允许不同的网络组件之间既存在竞争,又存在合作,以利用彼此的优势。通过引入这种机制,模型能更好地捕获和利用几何约束,例如静态背景和移动对象的区分,这在自然场景中是非常重要的。
无监督学习在这项工作中扮演了重要角色,因为它允许模型在没有直接标签的情况下学习。通过对未标注数据的分析,模型能够自我迭代并逐步优化其对深度、运动和光流的估计,同时也实现对场景的分割。
总结起来,这篇论文为理解和解决计算机视觉中的核心问题提供了一种新的视角,即通过联合无监督学习,利用深度学习模型的内在联系来增强各种任务的性能。这种方法不仅提高了每个单独任务的准确性,还促进了不同任务间的协同工作,从而推动了低级视觉问题的无监督学习研究。
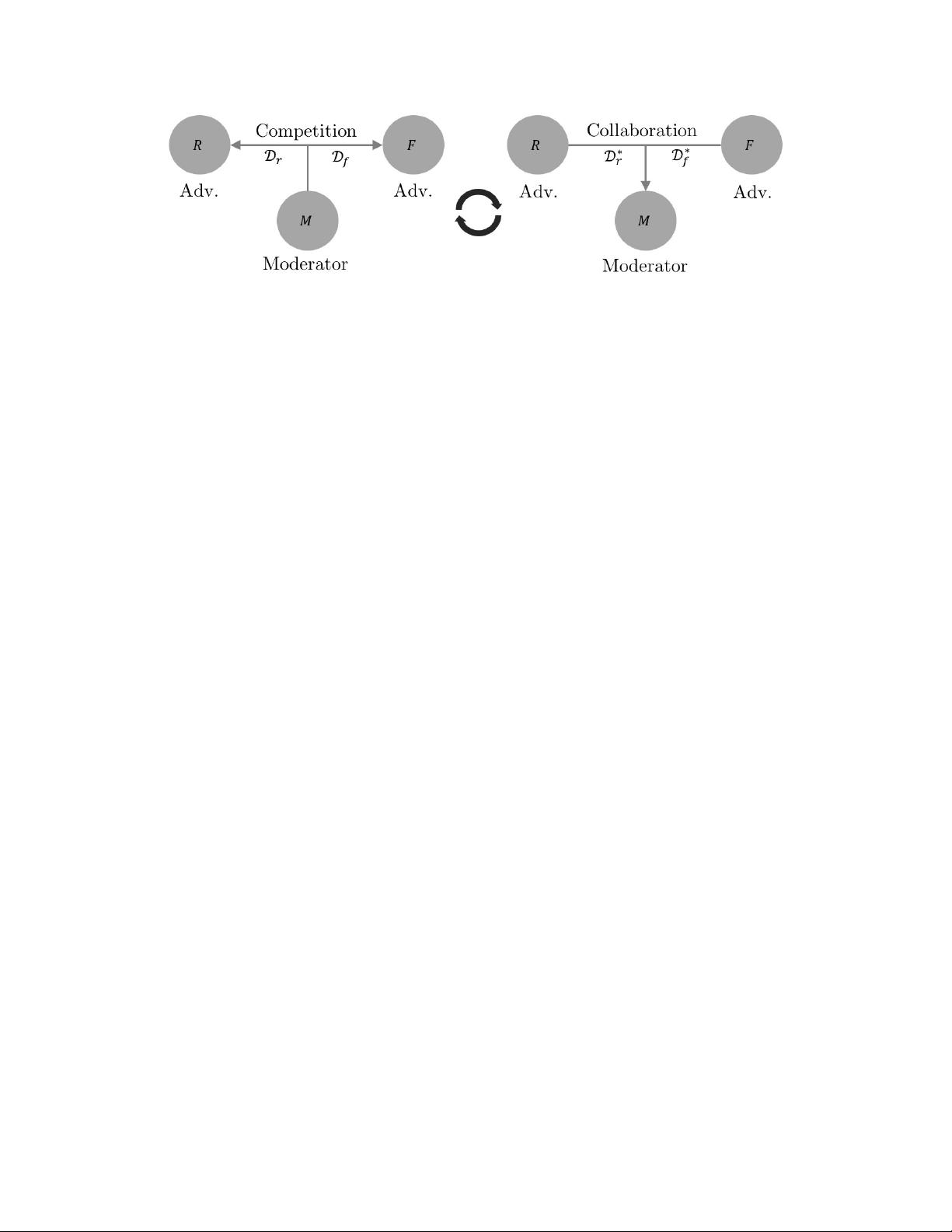
Figure 2: Training cycle of Competitive Collaboration: The moderator
M
drives competition between
two adversaries
{R, F }
(first phase, left). Later, the adversaries collaborate to train the moderator to
ensure fair competition in the next iteration (second phase, right).
In our implementation,
R = (D, C)
denotes the depth and camera motion networks that reason about
the static regions in the scene. The adversary
F
is the optical flow network that reasons about the
moving regions. For training the adversaries, the motion segmentation or mask network
M
selects
networks
(D, C)
on pixels that are static and selects
F
on pixels that belong to moving regions. The
competition ensures that
(D, C)
reasons only about the static parts and prevents any moving pixels
from corrupting its training. Similarly, it prevents any static pixels to appear in the training loss of
F
,
thereby improving its performance in the moving regions. In the second phase of the training cycle,
the adversaries
(D, C)
and
F
now collaborate to reason about static scene and moving regions by
forming a consensus which is used as a loss for training the moderator,
M
. In the rest of the section,
we formulate the joint unsupervised estimation of depth, camera motion, optical flow and motion
segmentation under this framework.
Notation.
We use
{D
θ
, C
φ
, F
ψ
, M
χ
}
, to denote the networks that estimate depth, camera motion,
optical flow and motion segmentation respectively. The subscripts
{θ, φ, ψ, χ}
are the network
parameters. We will omit the subscripts at several places for brevity. Consider an image sequence
I
−
, I, I
+
with target frame
I
, and neighboring reference frames
I
−
, I
+
. In general, we can have
many neighboring frames. In our implementation, we use 5 frame sequences for
C
φ
and
M
χ
. For
simplicity, we use 3 frames to describe our approach. We estimate depth of the target frame as
d = D
θ
(I). (1)
We estimate the camera-motion,
e
of each of the reference frames
I
−
, I
+
w.r.t the target frame
I
as
e
−
, e
+
= C
φ
(I
−
, I, I
+
). (2)
Similarly, we estimate the regions that segment the target image into static scene and moving regions.
The optical flow of the static scene is a result of only the camera motion. This generally refers to
the structure of the scene. The moving regions have independent motion w.r.t to the scene. The
segmentation masks corresponding to each pair of target and reference image are given by
m
+
, m
−
= M
χ
(I
−
, I, I
+
), (3)
where
m
+
, m
−
∈ [0, 1]
are the probability of regions being static. Finally, the network
F
ψ
estimates
the optical flow for the moving regions in the scene.
F
ψ
works with
2
images at a time, and its
weights are shared while estimating u
−
, u
+
, the backward and forward optical flow respectively.
u
−
= F
ψ
(I, I
−
), u
+
= F
ψ
(I, I
+
). (4)
Loss.
We learn the parameters of the networks
{D
θ
, C
φ
, F
ψ
, M
χ
}
by jointly minimizing the energy
E = λ
R
E
R
+ λ
F
E
F
+ λ
M
E
M
+ λ
C
E
C
+ λ
S
E
S
, (5)
where
{λ
R
, λ
F
, λ
M
, λ
C
, λ
S
}
are the weights on the respective energy term. The terms
E
R
, E
F
are
the objectives that are minimized by the two adversaries reconstructing static and moving regions
respectively. The competition for data is driven by
E
M
. A larger weight
λ
M
drives more pixels
towards static scene reconstructor. The term
E
C
drives the collaboration and
E
S
is a smoothness
regularizer. Ergo, E
R
minimizes the photometric loss on the static scene pixels given by
E
R
=
X
Ω
ρ
I, w
c
(I
+
, e
+
, d)
· m
+
+ ρ
I, w
c
(I
−
, e
−
, d)
· m
−
(6)
4
剩余15页未读,继续阅读
148 浏览量
点击了解资源详情
点击了解资源详情
495 浏览量
1972 浏览量
293 浏览量
798 浏览量
326 浏览量

NeilKuang
- 粉丝: 20
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- torch_cluster-1.5.6-cp36-cp36m-linux_x86_64whl.zip
- D-无人机:拉无人机。 使用计算机视觉在喷漆墙上画画以实现精确导航
- myloader
- Metro_Jiu-Jitsu-crx插件
- 导航条,鼠标悬停滑动下拉二级导航菜单
- 中国企业文化理念:提炼与实施的流程及方法(第一天课程大纲)
- 使用videojs/aliplayer 实现rtmp流的直播播放
- irt_parameter_estimation:基于项目响应理论(IRT)的物流项目特征曲线(ICC)的参数估计例程
- visualvm_21.rar
- torch_sparse-0.6.4-cp38-cp38-linux_x86_64whl.zip
- redratel:数字代理
- JumpStart!-开源
- api-2
- Adoptrs-crx插件
- redis windows x64安装包msi格式的
- XX轧钢企业文化诊断报告
