Python异步IO示例:提升并发性能的关键
118 浏览量
更新于2024-08-31
收藏 980KB PDF 举报
本文将深入探讨如何在Python中实现异步I/O(I/O多路复用)以提升并发性能。首先,我们了解到在编写同步代码时,由于单线程限制和线程切换对CPU资源的占用,无法有效地处理大量并发连接。为了解决这个问题,异步编程成为了一个关键策略,它通过非阻塞API和事件循环机制,允许程序在等待I/O操作完成时继续执行其他任务,从而提高并发能力。
例如,在磁盘I/O操作中,如果使用多线程并采用阻塞模式,会导致频繁的线程上下文切换,这会降低整体效率。通过异步编程,我们将I/O请求的切换工作交给用户态代码,利用如Linux的epoll或Windows的iocp等IO多路复用技术,避免了不必要的内核干预,节省了系统资源。
接下来,作者通过一个简单的Python Flask应用实例来展示异步编程。在`/bar`和`/foo`路由上,使用`time.sleep`模拟耗时操作,然后通过异步框架Flask处理这些请求。同步方式下,我们使用`requests`库发起HTTP请求,每次请求都会阻塞直到响应返回,而异步版本则会在发送请求后立即返回,后续的处理在事件循环中完成。
实现异步调用的关键在于理解事件循环的工作原理。在Flask应用中,当一个请求到达时,Flask会创建一个新线程处理HTTP请求,而不是等待整个请求完成。这使得应用可以同时处理多个请求,而非一一等待。在`requests.get`的异步版本中,实际上使用的是底层的异步网络库,如`asyncio`或`aiohttp`,它们提供了事件驱动的API,使得请求可以在等待网络I/O时保持活动。
然而,异步编程并非易事,特别在处理复杂的条件分支和系统调用时,它可能增加代码的复杂性和错误可能性。开发者需要遵循内聚性原则,确保函数之间的协作清晰,同时妥善管理异步回调和同步数据交互,以避免常见的陷阱,如回调地狱。
总结来说,Python中的异步I/O是通过事件驱动模型和IO多路复用技术来提高并发性能的重要手段。理解和掌握这一技术对于构建高效、可扩展的Web服务和其他高并发应用程序至关重要。在实践中,开发者需要熟练运用异步库,如Flask的异步支持,以及如`asyncio`这样的底层库,同时注意保持代码结构清晰,以实现真正意义上的高并发。
Python实现异步实现异步IO的示例的示例
前言前言
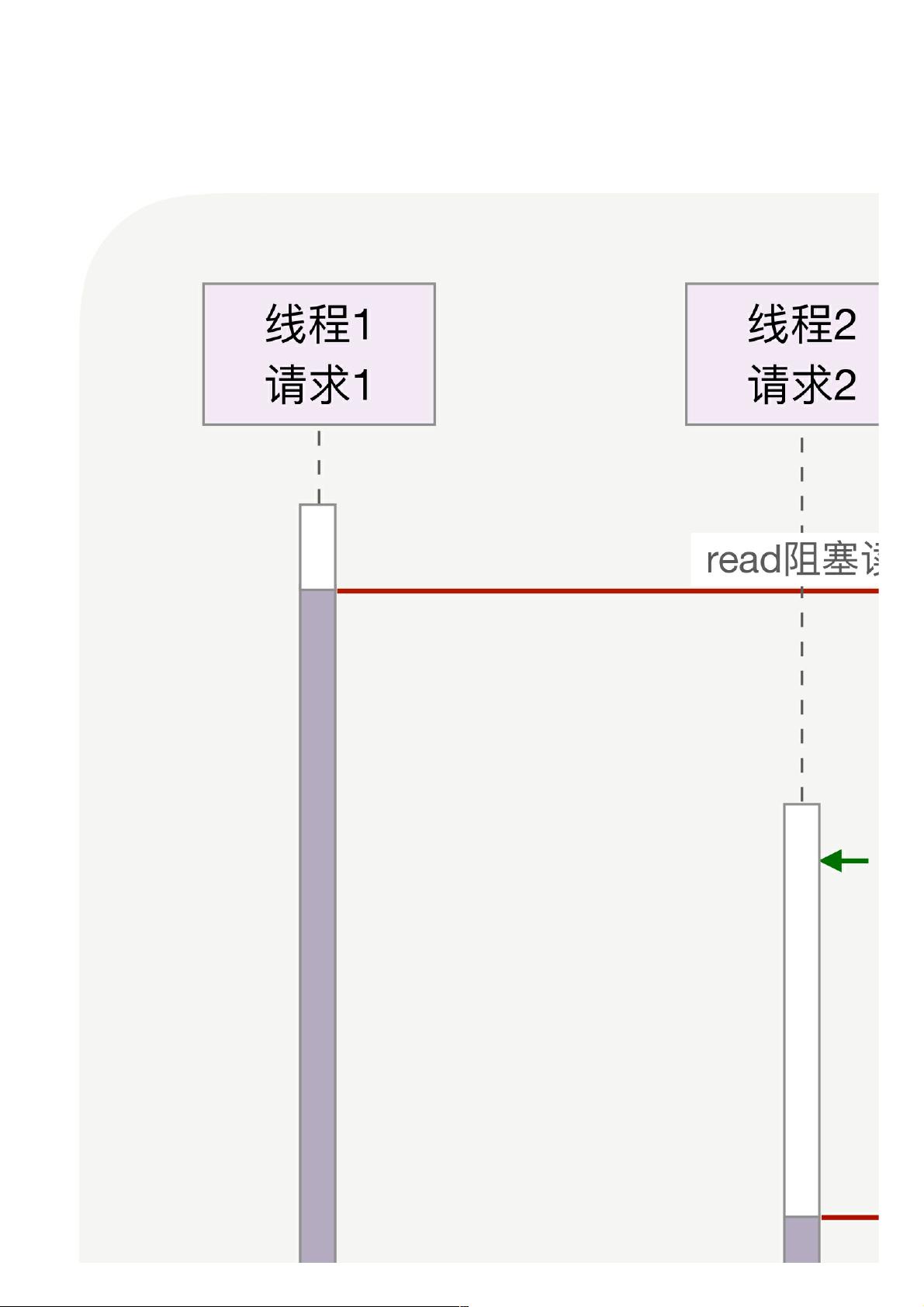
用阻塞 API 写同步代码最简单,但一个线程同一时间只能处理一个请求,有限的线程数导致无法实现万级别的并发连接,过多的线程切换也抢走了 CPU 的时间,从而降低了每秒能够处理的请求数
量。为了达到高并发,你可能会选择一个异步框架,用非阻塞 API 把业务逻辑打乱到多个回调函数,通过多路复用与事件循环的方式实现高并发。
磁盘 IO 为例,描述了多线程中使用阻塞方法读磁盘,2 个线程间的切换方式。那么,怎么才能实现高并发呢?
下载后可阅读完整内容,剩余3页未读,立即下载
2019-01-23 上传
2019-08-10 上传
2020-09-21 上传
2020-09-21 上传
2019-08-10 上传
2020-12-26 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38557515
- 粉丝: 6
- 资源: 917
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
