贝叶斯分类器实现手写数字识别系统
需积分: 5 146 浏览量
更新于2024-08-04
1
收藏 1.08MB DOC 举报
"基于贝叶斯分类器的手写数字识别系统代码大全"
基于贝叶斯分类器的手写数字识别系统是一种利用概率统计理论来识别手写数字的技术。这种系统主要用于处理各种文档中的手写字符,如银行支票、报表等,以自动化处理过程,提高效率。本文档详细介绍了这样一个系统的实现过程,包括其核心组成部分、工作流程、数据集描述以及特征提取方法。
首先,系统的主要研究内容是建立一个能够学习和识别手写数字图像的模型。它需要对给定的手写数字图片及其对应的标签进行分析,通过训练模型,使得新输入的图片可以被准确地识别为1到9之间的数字。这个过程涉及到图像处理、特征提取和分类器的设计。
在系统流程方面,文档中可能包含了系统从接收图像、预处理、特征提取、分类到最后输出识别结果的详细步骤。虽然具体代码没有给出,但通常会涉及图像二值化、边缘检测、细化处理等图像预处理技术,以及贝叶斯分类器的训练和应用。贝叶斯分类器因其概率解释和易于理解而常用于这类任务,它可以根据已知的先验概率和似然概率来计算后验概率,从而决定样本最可能的类别。
实验条件部分提到了硬件环境,如Intel i5-8265U CPU和Intel超高清显卡620,以及软件环境,如Windows操作系统和Matlab2016b。这些是运行和测试该识别系统的基本配置。
数据集是训练和测试模型的关键。文档中提到的数据集包含1890张手写数字图像,每种数字有210张,这允许模型学习到各种书写风格和形态的数字。图像可能通过模拟手写并保存的方式获取,确保了数据的多样性。
特征提取是识别过程的核心。这里采用了基于图像结构的特征,包括垂直交点、水平交点和对角交点的数量,以及笔划的端点。这些特征反映了数字的几何形状,有助于区分不同的数字。具体操作包括在图像的不同位置绘制辅助线,计算与笔划的交点,以及通过邻域统计来寻找端点。这个过程旨在提取稳定且能反映数字本质特征的信息。
最后,提取笔划结构端点的算法包括三步:目标定位(扫描图像找到黑色像素点)、邻域统计(检查8邻域像素以判断是否为端点)和遍历图像(重复以上步骤,提取所有端点特征)。这些步骤将帮助系统构建出有效的特征向量,用于后续的贝叶斯分类。
这个基于贝叶斯分类器的手写数字识别系统通过精心设计的特征提取和概率模型,实现了对手写数字的高效识别,具有广泛的应用前景。
基于贝叶斯分类器的手写数字识别系统
1.1 题目的主要研究内容
(1)手写数字识别是指给定一系列的手写数字图片以及对应的数字标签,
构建模型进行学习,目标是对于一张新的手写数字图片能够自动识别出对应的数
字,是字符识别的一个重要分支广泛应用于银行票据、工商报表、财务报表以及
统计报表等各种表格系统,但如何能方便快捷的识别辨识出手写数字的种类成为
重要研究课题。本文主要基于贝叶斯分类器,对手写数字进行了识别分类,最终
确定数字的所属类别,对样本的精准分类达到得出图像识别结果的目的。
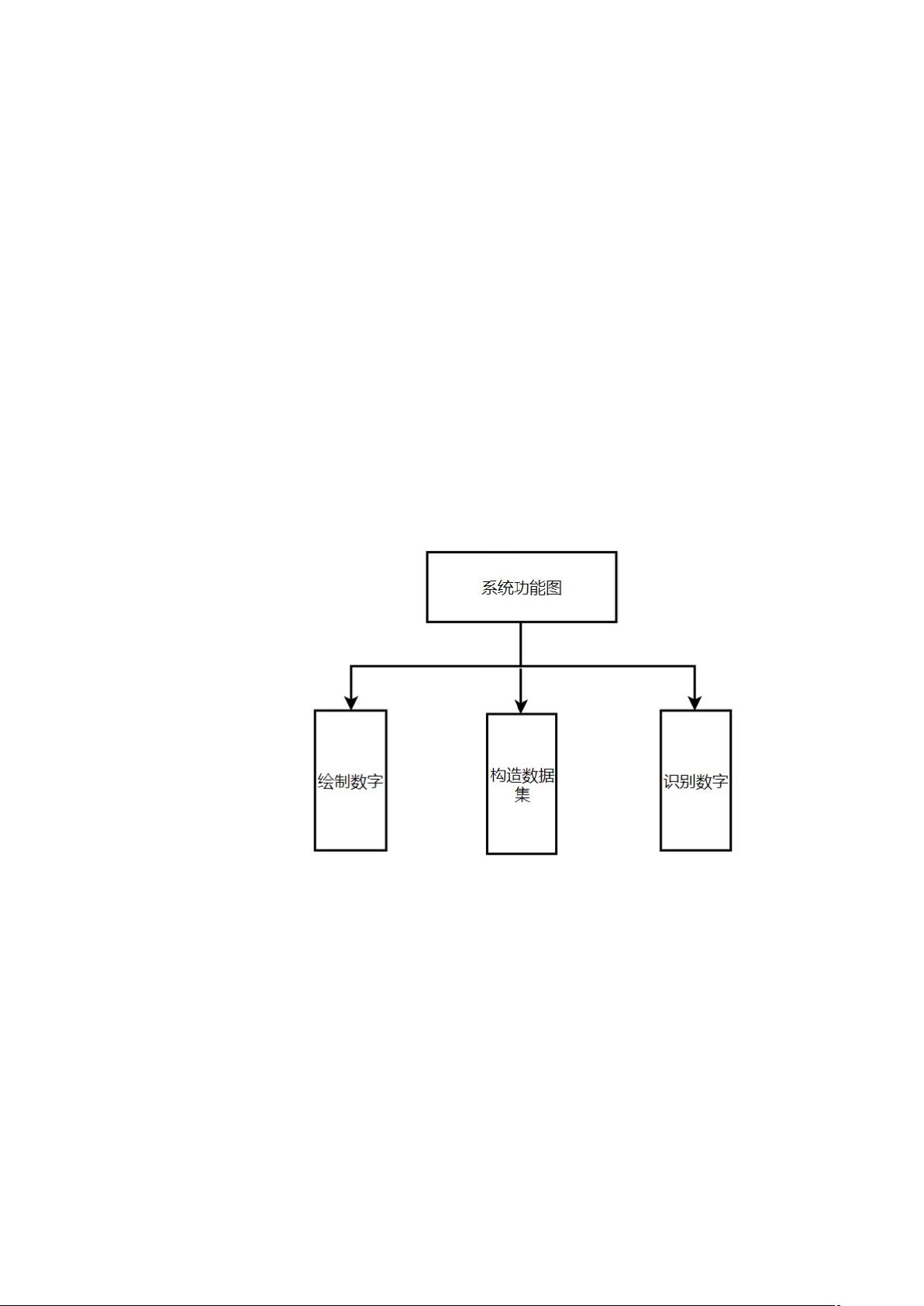
(2)系统流程图
图 1-1 系统流程图
1.2 题目研究的工作基础或实验条件
(1)硬件环境主要为:处理器 Intel i5-8265U CPU,英特尔超高清显卡
620。
(2)软件环境主要为 Windows 操作系统,Matlab2016b。
1.2 数据集描述
下载后可阅读完整内容,剩余5页未读,立即下载
2022-10-19 上传
211 浏览量
2019-01-07 上传
166 浏览量
2022-12-23 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

李逍遥敲代码
- 粉丝: 2995
- 资源: 277
 我的内容管理
展开
我的内容管理
展开







