信用卡欺诈检测:Kaggle实战与不平衡数据处理
152 浏览量
更新于2024-08-29
9
收藏 772KB PDF 举报
在Kaggle的经典案例中,我们探讨了信用卡诈骗检测的问题,通过Python编程实现了一个完整的分析流程。首先,导入必要的库如pandas、matplotlib和numpy,并读取名为"creditcard.csv"的数据集。数据集包含多个特征(V1-V28),其中"Amount"表示交易金额,"Class"标签区分正常交易(0)和欺诈交易(1)。目标是建立一个二分类模型来识别异常交易。
在探索数据阶段,我们注意到样本数据存在严重的类别不平衡,即正常交易(负样本)的数量远大于欺诈交易(正样本)。这种不平衡可能导致模型容易偏向于多数类,从而影响模型性能。为解决这个问题,可以采用两种策略:
1. **下采样**(Undersampling):减少正样本的数量,使两类样本数量接近,以平衡数据。这样可以避免模型过度拟合多数类,提高对少数类的识别能力。
2. **过采样**(Oversampling):增加负样本的数量,使得两类样本量相等。常见的过采样方法有SMOTE(Synthetic Minority Over-sampling Technique),通过生成新的合成样本来扩充少数类。
数据预处理中,特别关注了"Amount"列的数值范围问题。由于与其他特征相比,其值的差异较大,可能会影响模型训练的准确性。因此,对"Amount"进行归一化或标准化处理,比如使用sklearn库中的StandardScaler或MinMaxScaler,确保各特征在相似的尺度上进行分析。
此外,文章可能还会涉及数据可视化(如绘制Class数量的直方图),以及逻辑回归模型的选择和训练过程,包括特征选择、模型参数调优和评估指标(如准确率、精确率、召回率、F1分数等)。最后,为了提升模型的泛化能力,可能还会讨论交叉验证和模型集成(如随机森林、AdaBoost等)的应用。
在整个流程中,学习者将深入了解数据预处理、不平衡数据处理、特征工程和模型评估的关键环节,从而更好地应对信用卡诈骗检测这类实际问题。
Kaggle经典案例经典案例—信用卡诈骗检测的完整流程信用卡诈骗检测的完整流程(学习笔记学习笔记)
本文此案例的完整流程和涉及知识
首先先看数据首先先看数据
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
data = pd.read_csv("creditcard.csv")
data.head()
data.shape
好的,它长这个样子。大致解释一下V1-V28都是一系列的指标(具体是什么不用知道),Amount是交易金额,Class=0表示是正常操作,而=1表示异常操作。
明确目标:检测是否异常,也就是说是一个二分类问题,接着想到用逻辑回归建模。明确目标:检测是否异常,也就是说是一个二分类问题,接着想到用逻辑回归建模。
1.观察数据特征观察数据特征
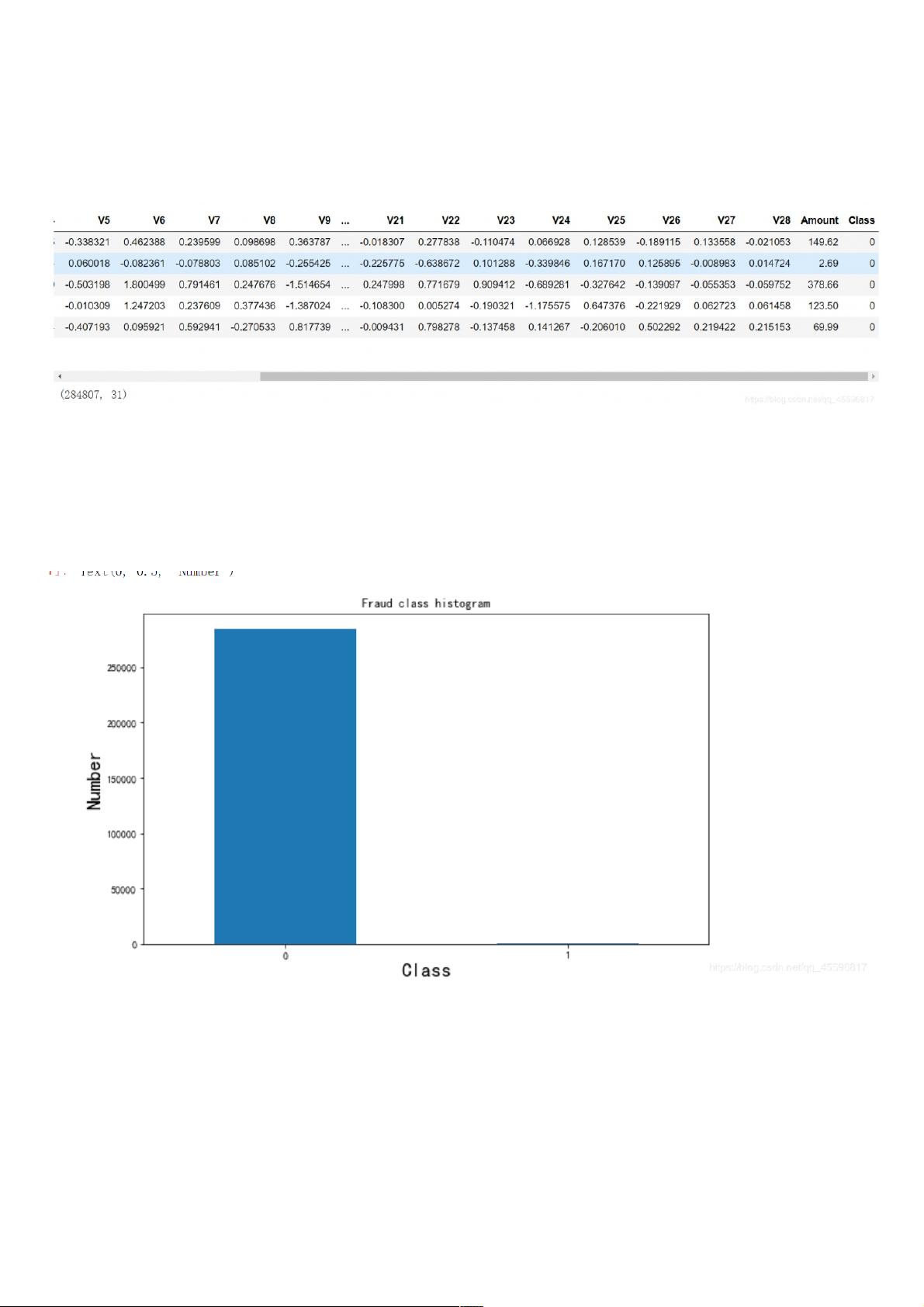
Class=0的我们不妨称之为负样本,的我们不妨称之为负样本,Class=1的称正样本的称正样本,看一下正负样本的数量。
count_classes = pd.value_counts(data['Class'],sort = True).sort_index()
plt.figure(figsize=(10,6))
count_classes.plot(kind='bar')
plt.title("Fraud class histogram")
plt.xlabel("Class",size=20)
plt.xticks(rotation=0)
plt.ylabel("Number",size=20)
可以看出样本数据严重不均衡,样本类别不均衡将导致样本量少的分类所包含的特征过少,并很难从中提取规律。同时你的学习结果会过度拟合这种不均的结果,通俗来说就是将你
的学习结果用到一组分布均匀的数据上,拟合度会很差。
那么怎么解决这个问题呢?有两种办法那么怎么解决这个问题呢?有两种办法
采样方式选择采样方式选择
((1)下采样)下采样
对这个问题来说,下采样采取的方法就是取正样本中的一部分,使得正样本和负样本数量大致相同。就是让样本变得一样少就是让样本变得一样少
((2)过采样)过采样
相对的,过采样的做法即再生成更多的负样本数据,使得负样本和正样本一样多。就是让样本变得一样多就是让样本变得一样多
2.归一化处理归一化处理
继续观察数据,我们可以发现Amount这一列数据的浮动差异和V1-V28数据的浮动相比差距很大。在做模型之前要保证特征之间的分布差异是差不多的,否则会对我们的模型产生误在做模型之前要保证特征之间的分布差异是差不多的,否则会对我们的模型产生误
导,所以先对导,所以先对Amount做归一化或者标准化做归一化或者标准化做法如下,使用sklearn很方便
#在这里顺便删去了Time列,因为Time列对这个问题没什么帮助
from sklearn.preprocessing import StandardScaler
data['normAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1, 1))
data = data.drop(['Time','Amount'],axis=1)
data.head()
下载后可阅读完整内容,剩余5页未读,立即下载
2020-07-02 上传
2020-04-07 上传
2019-02-12 上传
2023-09-22 上传
2024-05-13 上传
2023-06-09 上传
2023-05-17 上传
2024-05-11 上传
2023-06-12 上传

weixin_38621427
- 粉丝: 10
- 资源: 941
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fizmez Web Server-开源
- jdk-8u271-linux-x64.zip
- c代码-这是一个输出0-50z之间所有能被3整除的的程序。
- movie-inc:影片制作数据库中的挑战奖的制作,预告片制作和制作,以及在影片库中编写的API
- matlab归零码功率谱源码-Genesis-1.3-Version4:随时间变化的3D代码可模拟自由电子激光器的放大过程
- acnh-critter-calendar:生成可以在岛上捕获的生物的列表
- video-layout2.zip
- Filter IE History-开源
- BooksStoreExcercise
- mysql代码-单表查询,多表查询
- 模拟电路-答案.zip-综合文档
- SD_HTMLRegPage
- mysql5.7安装软件及教程含主从配置.zip
- Fast Login Script-开源
- ShaggyShooters
- rock_paper_scissors:石头剪刀布游戏
