《数据科学》课程作业:股票数据分析与可视化
需积分: 0 77 浏览量
更新于2024-08-05
收藏 535KB PDF 举报
"《数据科学》课程作业,吴义豪,北京科技大学计通学院通信1804班,上证A股股票数据分析"
本资源详细介绍了进行一项数据科学作业的过程,涉及了数据处理、分析和可视化等多个环节。作业基于上海机场的股票数据,数据源为CSV文件,包含了2003年4月至2016年6月的股票基本信息。在处理数据时,主要遵循以下步骤:
1. **数据读取与预处理**:首先使用`pandas`库的`read_csv`函数读取CSV文件,并按照指定列名保留代码、简称、日期、开盘价、收盘价和成交金额。接着,通过`dropna`方法删除包含空值的行,确保数据的完整性。
2. **日期转换**:将数据集中日期列转换为`datetime`类型,以便进行时间序列分析。这一步骤通过`pd.to_datetime`实现,将日期列设置为DataFrame的索引。
3. **数据汇总**:按照代码、简称和月份对数据进行分组,并计算每月的平均开盘价、平均收盘价以及总成交金额。这一步使用了`resample`函数进行时间频率的重采样,再结合`mean`和`sum`方法求得所需统计量。
4. **数据保存**:将处理后的数据保存到新的CSV文件中,以便后续分析或参考。
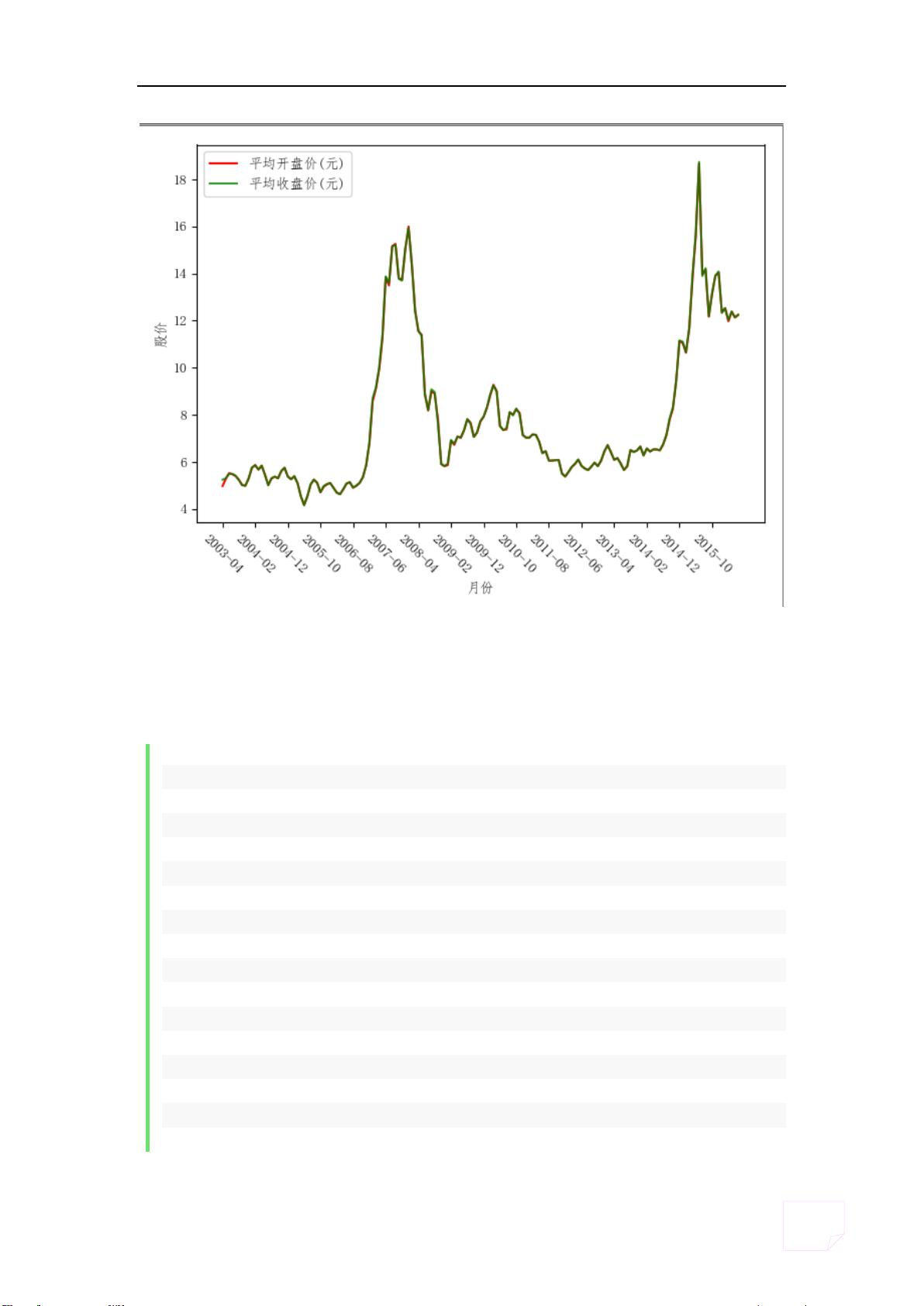
5. **数据可视化**:根据月份绘制平均开盘价和平均收盘价的曲线图,横坐标为月份,纵坐标为股价。这通常会使用`matplotlib`或`seaborn`等库来实现,以直观展示股价随时间的变化趋势。
6. **正态分布检验**:对所有月份的总成交金额进行正态性检验,通常可以使用Shapiro-Wilk检验或Kolmogorov-Smirnov检验等方法,以确定这些数值是否符合正态分布。正态分布检验的原理是对比观测数据与正态分布的拟合程度,如果检验统计量的p值小于显著性水平,通常认为数据不服从正态分布。
此作业涵盖了数据科学中的基础操作,包括数据清洗、时间序列分析、统计计算和数据可视化,这些都是数据分析师必备的技能。通过这个作业,学生能够熟悉和掌握`pandas`库的基本操作,以及如何应用统计学方法来理解金融数据的特性。
《数据科学》课程作业
3
同一张图上绘制两条曲线
由于数值差距不大,发现两曲线已经近似重合,为了使效果更加明显,可
以采用双 Y 轴绘制曲线图,将左 Y 轴设置为[3,22],右 Y 轴设置为[2,21]:
1. fig = plt.figure()
2. ax1 = fig.add_subplot(111)
3. lns1 = ax1.plot(new_stock.index,new_stock['平均开盘价(元)'])
4. ax1.set_ylabel('Y values for 平均开盘价(元)')
5. ax1.set_title("平均开盘价和平均收盘价随月份的变化")
6. ax1.set_ylim([3,22])
7. ax2 = ax1.twinx() # this is the important function
8. lns2 = ax2.plot(new_stock.index,new_stock['平均收盘价(元)'], 'r')
9. ax2.set_ylim([2,21])
10. ax2.set_ylabel('Y values for 平均收盘价(元)')
11. ax2.set_xlabel('月份 ')
12. plt.xticks(new_stock.index[::18],new_stock['日期'][::18])
13. lns = lns1 +lns2
14. labs = [l.get_label() for l in lns]
15. ax1.legend(lns,labs,loc=0)
16. plt.xticks(rotation=-45)
17. plt.show()
剩余10页未读,继续阅读
1442 浏览量
756 浏览量
842 浏览量
1643 浏览量
625 浏览量
4068 浏览量

洋葱庄
- 粉丝: 21
- 资源: 311
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
