CUDA执行模型解析:优化计算机视觉程序性能
79 浏览量
更新于2024-08-29
收藏 357KB PDF 举报
"CUDA执行模型是优化计算机视觉应用性能的关键,理解这一模型能帮助开发者更好地并行化线程,提高程序效率。本文基于《Professional CUDA C Programming》一书的第三章进行总结,深入探讨CUDA的执行机制。"
在CUDA编程中,理解执行模型至关重要,因为这直接影响到程序在GPU上的运行效率。CUDA执行模型描述了GPU如何调度和执行线程,以最大化并行计算能力。GPU架构通常由多个Streaming Multiprocessors (SM) 组成,每个SM又包含多个CUDA核心、共享内存、L1缓存、寄存器以及特定功能单元等。
一个CUDA程序通过Kernel函数启动,Kernel可以看作是一个网格(Grid),由多个线程块(Thread Block)构成,每个线程块又包含多个线程。在硬件层面,一个完整的线程块会被分配给一个SM,而线程则由SM内的CUDA核心执行。这种分层并行结构使得GPU能够同时处理大量数据。
SM(Streaming Multiprocessor)是GPU的核心执行单元,它负责调度和执行线程块内的线程。SM内部包含了CUDA核心,用于执行基本的算术运算;共享内存和L1缓存则提供了快速访问的数据存储;寄存器是高速存储区域,用于保存线程的局部变量;Load/Save Units用于数据加载和存储;Special Function Units处理特定的数学运算;而Warp Scheduler则负责线程的调度,确保在有限的硬件资源下,线程得以高效执行。
在优化CUDA程序时,寻找最佳的线程块和线程数量组合至关重要。这个过程通常称为“occupancy”优化,指的是在SM上同时活动的线程比例。高occupancy可以充分利用GPU资源,提高并行度,从而提升性能。然而,过高的occupancy可能会导致资源竞争,反而降低效率。因此,开发者需要根据具体任务和GPU架构,找到最佳的线程配置。
CUDA编程的一个关键挑战在于理解和利用这些并行层次,以实现最佳性能。这包括合理地划分数据和工作负载,有效地使用共享内存,以及避免阻塞线程的同步问题。通过深入理解CUDA执行模型,开发者可以编写出更高效、更具可扩展性的计算机视觉算法,充分发挥GPU的并行计算优势。
计算机视觉大型攻略计算机视觉大型攻略 —— CUDA(2)执行模型执行模型
Professional CUDA C Programming[1]是一本不错的入门书籍,虽说命名为”Professional”,但实际上非常适合入门阅读。他几乎涵盖了所有理论部分
和编程技巧,更重要的是每一章都有完整的实例程序。只不过对于入门来讲,这本书有点太厚了,行文有些啰嗦。准备写几篇文章提取一下关键章节
的关键部分。
上一篇写了如何写一个简单的CUDA程序。为了进一步优化程序性能,我们经常会调整Block数量和Thread数量,不断的寻找最优的组合。这一篇探讨
的是最优组合背后的故事,为什么有些组合可以达到更好的性能。理解CUDA的执行模型,有助于进一步并行化线程,提高程序性能。
这一篇算是对[1]中第三章CUDA Execution Model的总结。
参考文献:
[1] PROFESSIONAL CUDA C Programming. John Cheng, Max Grossman, Ty McKercher. [2] CUDA C PROGRAMMING GUIDE
执行模型(Execution Model)通常指的是某种计算架构中如何执行指令。理解执行模型有助于进一步优化CUDA程序。该模型与GPU硬件架构息息相
关。
GPU架构架构
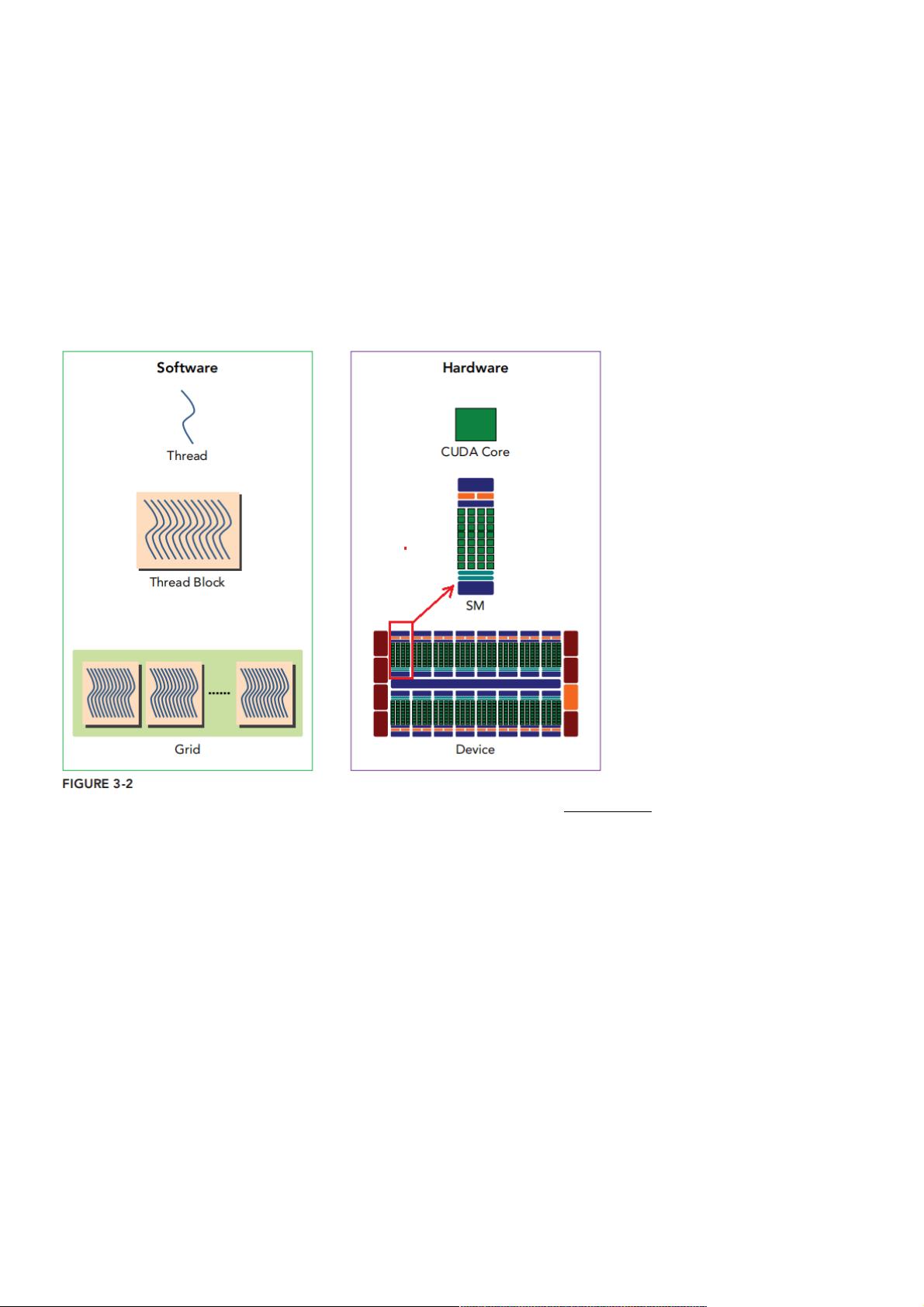
上图引自[1]第三章。左边是软件视角中的程序,右边是硬件视角中的程序。从软件角度来说,上图从下往上看,一个Kernel函数(即一个Grid)有许多
Thread Block组成,一个Thread Block又有许多线程组成。从硬件的角度来说,Kernel函数在GPU上执行,GPU由一组由一组SM(streaming
multiprocessor,多核流处理区,多核流处理区)组成组成,一个完整的Block分配给一个SM,Block中的thread,由SM中的CUDA core执行。SM可以看成一个独立的作战
单元,通常来讲高效的GPU拥有更多数量的SM,同时每个SM的架构均相同。
Streaming Multiprocessor
一个SM的基本组成部分
CUDA core
共享内存(Shared Memory)和L1 Cache
寄存器
Load/Save Units
Special Function Units
Warp Scheduler
下图是Fermi架构上的SM的图示,虽然与当下主流架构Pascal,Volta相比有不少区别,但是基本组成部分大体一致。
下载后可阅读完整内容,剩余4页未读,立即下载
2023-06-01 上传
2022-06-20 上传
2024-07-16 上传
106 浏览量
2021-12-04 上传
2021-06-11 上传
2021-12-01 上传
2011-12-19 上传
2010-09-30 上传

weixin_38698174
- 粉丝: 3
- 资源: 980
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
