预训练语言模型:真的理解语言了吗?
版权申诉
53 浏览量
更新于2024-07-05
收藏 32.96MB PDF 举报
"这篇文档探讨了预训练语言模型是否真正理解语言的问题,由黄民烈在清华大学CoAI(对话式人工智能)研究所发表。主要内容包括对意义、理解和知识的定义,预训练模型的理解能力,它们学到和未学到的内容,以及如何通过注入知识和后训练来改进模型。文档引用了Bender和Koller关于自然语言理解基础问题的观点,并提到了维特根斯坦的‘意义即使用’的概念和分布假设。”
预训练语言模型是当前自然语言处理领域的热门研究方向,它们通过在大规模文本数据上进行无监督学习,学习到语言的模式和结构。然而,这些模型是否真正理解语言,即是否能够理解语义,是一个复杂且有争议的问题。
首先,理解和意义在计算语言学中是基本概念。Bender和Koller在2020年ACL大会的最佳主题论文中提出,意义可能源于词汇在文本语料库中的使用方式。这与维特根斯坦在《哲学研究》中的观点相呼应,他认为“意义即使用”,即词汇的意义可以通过其在不同上下文中的出现来推断。
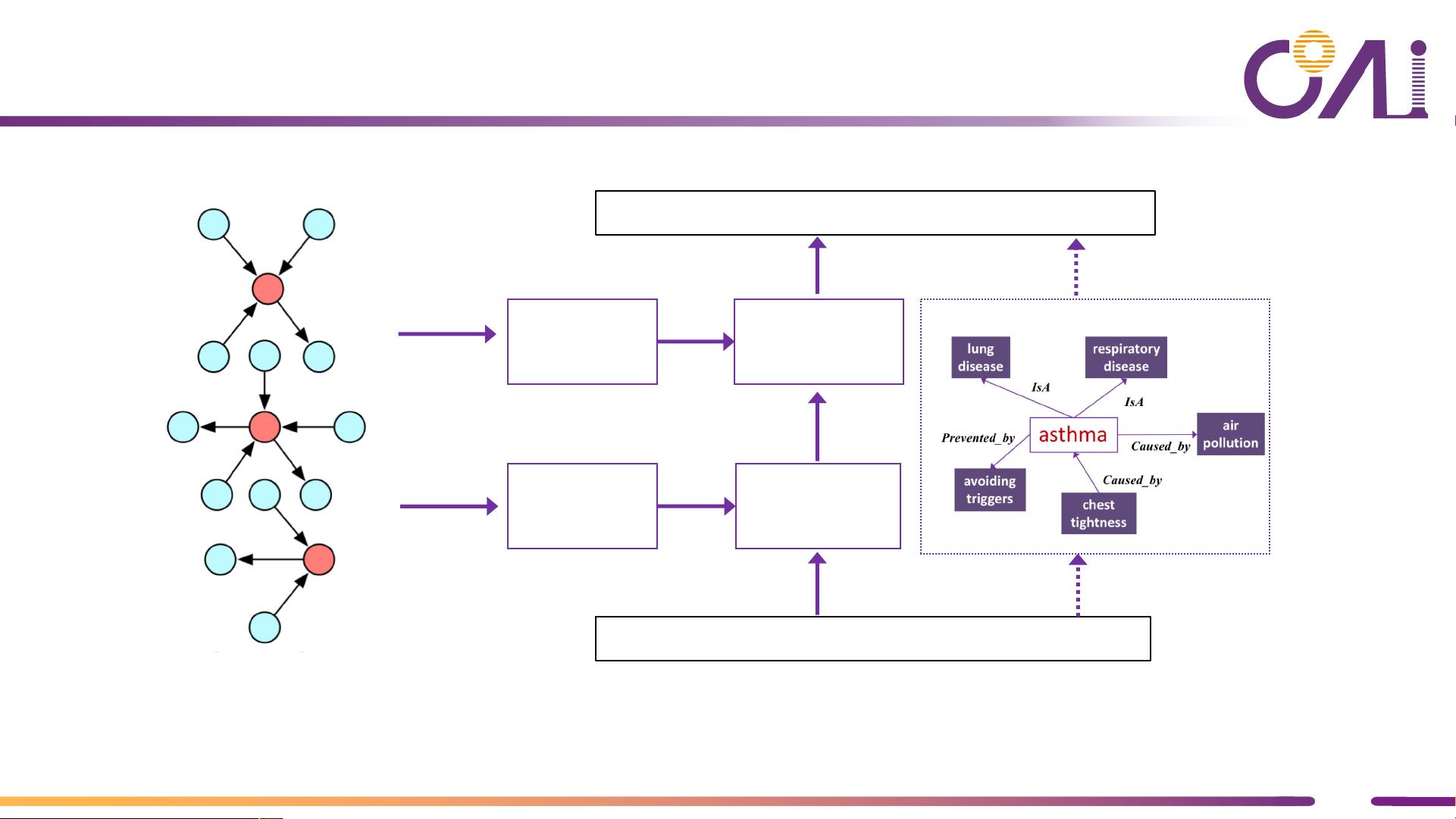
接着,文档提到分布假设,这是Harris在1954年提出的,认为词汇如果出现在相似的上下文中,它们的意义就可能相似。预训练模型正是基于这个假设,通过捕获词汇的上下文信息来学习其潜在表示,例如BERT和GPT系列模型。
然而,尽管预训练模型在许多任务上表现出色,如问答、情感分析和机器翻译,但它们并不真正理解语言的深层含义。模型可能学习到词汇的共现模式,但无法捕捉到语境的细微差异、隐喻、文化和语用规则等复杂语义信息。
为了提升模型的理解力,文档提出了两种方法:知识注入和后训练。知识注入是指将结构化知识,如知识图谱,直接整合到模型中,使模型能够访问和利用这些信息。而后训练则是指在预训练模型的基础上,使用带有标签的数据进行微调,以增强模型在特定任务上的性能。
预训练模型在一定程度上能够捕获和利用语言的表面结构,但要实现真正意义上的理解,还需要结合语义表示、知识表示和推理等更深入的研究。未来的研究应聚焦于如何让模型更好地理解和运用知识,以提高自然语言处理系统的智能水平。

Grounding to real worlds
7
“The photographer asked me to do a Napoleon for the camera.”
Bender and Koller. Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data. ACL 2020.
Best theme paper.
剩余45页未读,继续阅读
2022-03-18 上传
2022-03-18 上传
2022-03-18 上传
2022-03-18 上传
2022-03-18 上传
2022-03-18 上传
2022-03-18 上传
2022-03-18 上传
2022-03-18 上传

普通网友
- 粉丝: 13w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







最新资源
- ayotidur
- Exsty-crx插件
- Language-zone
- SCATTERBAR3:创建一个 3-D 条形图,其中条形放置在用户指定的 XY 位置。-matlab开发
- TensorFlow2实战-系列教程14:Resnet实战
- [新闻文章]小虫新闻管理系统V1.0_xcnewsv1.0.rar
- AzureDiagnosticsPipeline:此存储库具有构建Azure诊断DevOps管道的源,以将诊断设置应用于Azure资源(动态)
- 蛇:基于控制台的蛇游戏
- TurboCStudy,c语言编译的源码,c语言项目
- Biorhythm:你的一周过得怎么样?-matlab开发
- koa-template-project:Koa模板项目
- 简洁棕色线条响应式html5模板5598.zip
- Coin Master Free Spins Loader-crx插件
- 苹果手机
- click-and-meet-calendar-generator:生成可打印的日历,以根据德国的COVID-19规则管理“点击并开会”约会
- -123r
