分布式数据库解决方案:提高性能与高可用性
版权申诉
"该文档详细探讨了大型分布式数据库的设计方案,包括分区表技术、分布式分区视图、库表散列等方法,旨在解决大数据量下数据库性能和管理的问题。此外,文档还提到了数据实时复制解决方案,分析了SQL Server的复制技术的优缺点,并对比了数据库集群的实时性优势。"
在大型分布式数据库解决方案中,首先介绍了分区表技术,这是一种通过将数据分散到不同磁盘以提升并行处理能力的策略,但其局限在于仍受限于单台机器的硬件资源。分布式分区视图则允许数据跨机器分布,用户通过视图进行访问,虽然提供了透明性,但管理复杂度增加且存在一些限制,如无法使用自增列和大数据对象,全局查询效率可能下降。
接着,文档提出了库表散列的概念,即根据用户或其他业务逻辑将数据分散到多个库和表中,以提高性能。然而,这种方法需要大量的研发投入,且缺乏通用性。分布式网格集群成为解决大数据问题的关键,通过数据分区和并行处理,实现了读写速度的显著提升,并降低了硬件成本,增强了系统的可用性和可管理性。
数据实时复制方面,SQL Server的复制技术(如合并复制、事务复制、快照复制)可以缓解查询压力,但存在实时性差、初始化影响大等问题。相比之下,数据库集群通过实时同步数据,提供了更高的数据一致性,并且采用智能同步策略,加快了同步速度,满足了对实时性的高要求。
分布式数据库设计的目标是优化性能、提高可用性和管理效率,而实时数据复制是确保高并发环境下服务连续性的关键。通过合理选择和实施这些策略,企业可以有效地应对大数据带来的挑战,提供稳定、高效的服务。
分布式数据库设计方案
..
1. 大型分布式数据库解决方案
企业数据库的数据量很大时候,即使服务器在没有任何压力的情况下,某些复杂的查询操作都会非常缓慢,
影响最终用户的体验;当数据量很大的时候,对数据库的装载与导出,备份与恢复,结构的调整,索引的
调整等都会让数据库停止服务或者高负荷运转很长时间,影响数据库的可用性和易管理性。
分区表技术
让用户能够把数据分散存放到不同的物理磁盘中,提高这些磁盘的并行处理能力,达到优化查询性能的目
的。但是分区表只能把数据分散到同一机器的不同磁盘中,也就是还是依赖于一个机器的硬件资源,不能
从根本上解决问题。
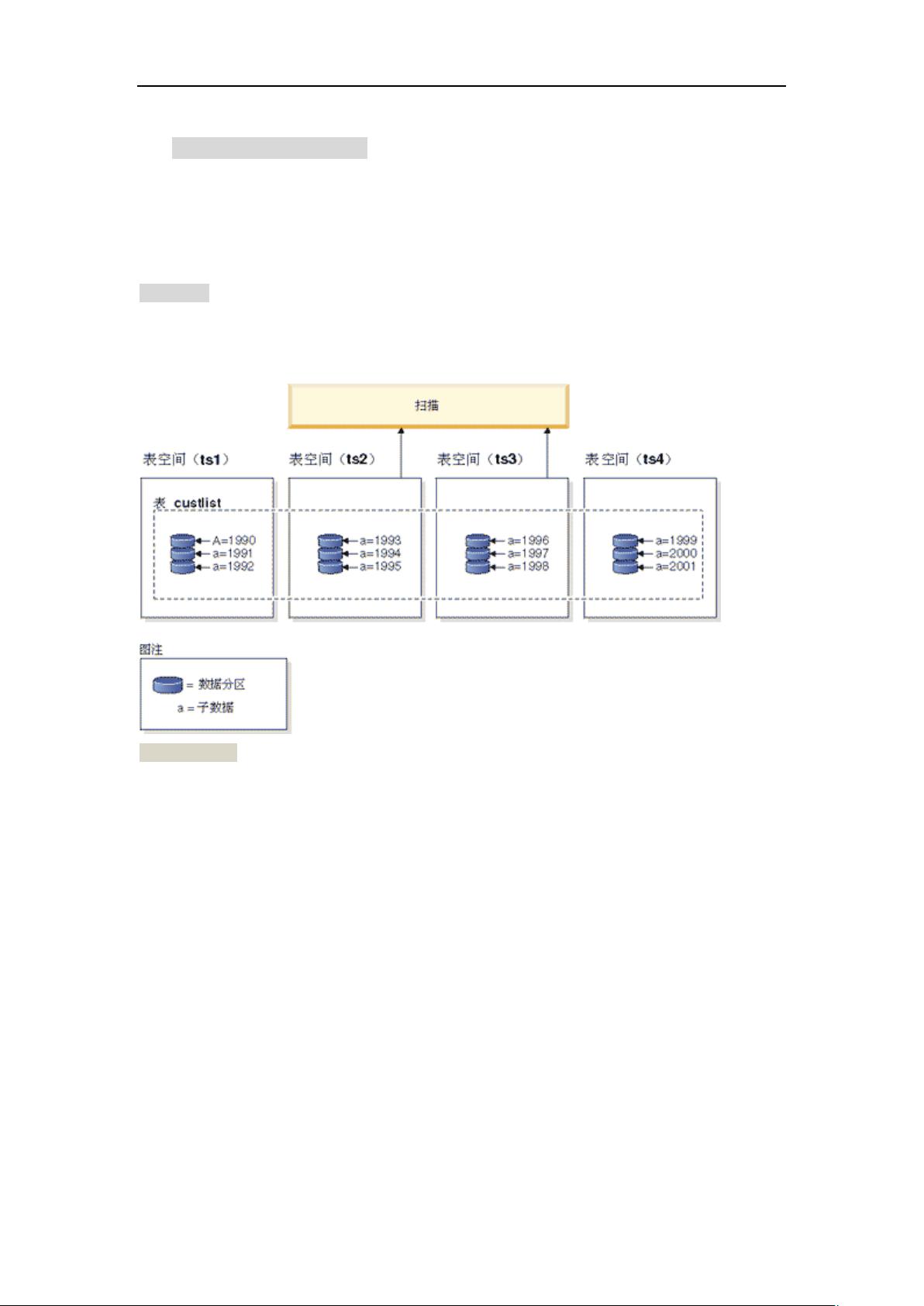
分布式分区视图
分布式分区视图允许用户将大型表中的数据分散到不同机器的数据库上,用户不需要知道直接访问哪个基
础表而是通过视图访问数据,在开发上有一定的透明性。但是并没有简化分区数据集的管理、设计。用户
使用分区视图时,必须单独创建、管理每个基础表(在其中定义视图的表),而且必须单独为每个表管理数
据完整性约束,管理工作变得非常复杂。而且还有一些限制,比如不能使用自增列,不能有大数据对象。
对于全局查询并不是并行计算,有时还不如不分区的响应快。
下载后可阅读完整内容,剩余8页未读,立即下载
2022-12-06 上传
2020-09-09 上传
2022-07-14 上传
2021-09-14 上传
2022-12-21 上传
2022-11-24 上传
2022-07-18 上传
2023-02-27 上传
2023-07-07 上传

小虾仁芜湖
- 粉丝: 104
- 资源: 9352
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
