Python Scrapy入门指南:实战解析与数据提取
需积分: 17 107 浏览量
更新于2024-07-16
1
收藏 17.7MB PDF 举报
Python Scrapy参考文档是一份全面指南,旨在帮助学习者理解并掌握如何使用Python编程语言构建高效的网络爬虫框架Scrapy。该文档分为九个章节,从初识Scrapy的概念和安装开始,逐步深入到爬虫的各个方面。
在第一章中,介绍了什么是网络爬虫以及Scrapy的基本概念,包括如何创建一个Scrapy项目,分析目标网页结构,编写基础的Spider,并演示了如何运行爬虫。这一章的重点在于引导读者理解和实践Scrapy的基本操作流程。
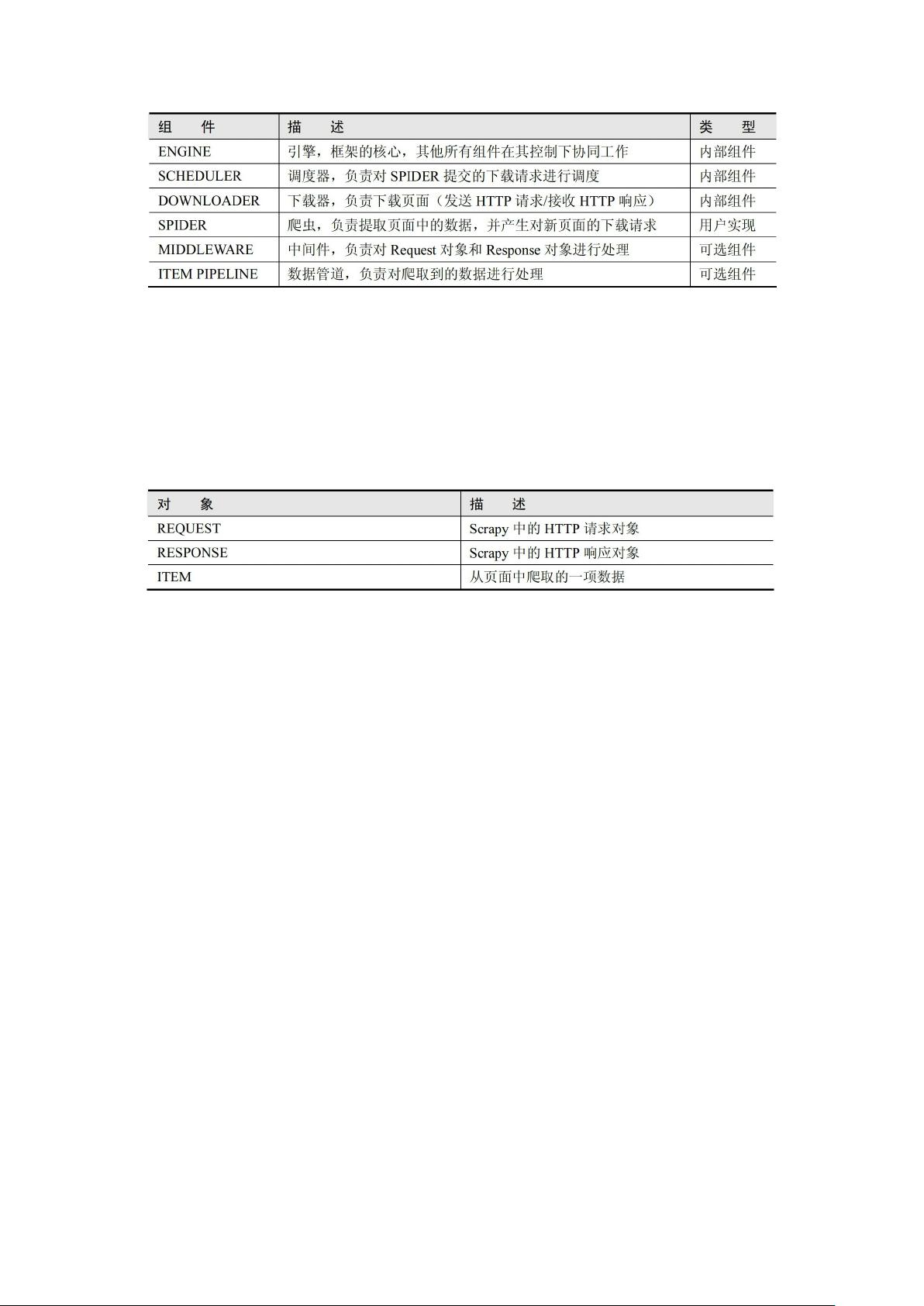
第二章详细讲解了Scrapy框架结构,特别是Request和Response对象的作用和用法。Request对象用于发起网络请求,而Response对象则包含了服务器的响应数据。学习者会学会如何继承scrapy.Spider,设置爬虫的名称、起始URL,以及如何编写解析页面内容的函数。
第三章专门探讨如何使用Selector工具从网页中提取数据,涉及Selector对象的创建、数据选择和提取,以及XPath和CSS选择器的使用。XPath提供了强大的查找和定位HTML元素的能力,CSS选择器则以简洁的样式语言实现相同功能。
第四章围绕Item和Field展开,介绍了如何定义和组织数据结构,以及如何扩展Item子类和设置Field的元数据。这一部分对于数据的持久化和管理至关重要。
第五章着重介绍ItemPipeline,它是Scrapy中的数据处理机制,通过继承自定义类来实现数据清洗、去重、存储等功能。具体实例包括过滤重复数据和将数据保存到MongoDB数据库。
第六章讲解如何使用LinkExtractor提取链接,包括设置提取规则和规则的描述,这对于发现新的抓取目标非常关键。
第七章主要关注数据的导出,讲解了如何配置命令行参数和配置文件,以及如何添加不同的数据导出格式,如CSV或JSON等。源码参考和Exporter的实现也在此部分详述。
第八章是项目实践,提供了一个实际项目的需求分析,让读者在实际场景中应用所学知识。通过模仿爬取matplotlib例子源码文件,学习者可以进一步熟悉Scrapy的各个环节。
第九章专门处理文件下载和图片抓取,介绍了FilesPipeline和ImagesPipeline的使用方法,通过两个项目实战——下载matplotlib例子源码文件和360图片,展示了如何在Scrapy中处理这些复杂的任务。
这份Python Scrapy参考文档为学习者提供了一个循序渐进的学习路径,涵盖了从入门到进阶的全部内容,适合对网络爬虫有兴趣的开发者和研究者使用。

... <省略中间部分输出> ...
995 Beyond Good and Evil,£43.38
996 Alice in Wonderland (Alice's Adventures in Wonderland #1),£55.53
997 "Ajin: Demi-Human, Volume 1 (Ajin: Demi-Human #1)",£57.06
998 A Spy's Devotion (The Regency Spies of London #1),£16.97
999 1st to Die (Women's Murder Club #1),£53.98
1000 "1,000 Places to See Before You Die",£26.08
从上述数据可以看出,我们成功地爬取到了1000本书的书名和
价格信息(50页,每页20项)。
1.4 本章小结
本章是开始Scrapy爬虫之旅的第1章,先带大家了解了什么是网
络爬虫,然后对Scrapy爬虫框架做了简单介绍,最后以一个简单的
爬虫项目让大家对开发Scrapy爬虫有了初步的印象。在接下来的章
节中,我们将深入学习开发Scrapy爬虫的核心基础内容。
25



剩余244页未读,继续阅读
2014-12-23 上传
2021-03-09 上传
190 浏览量
2012-07-17 上传
2022-09-15 上传
2023-09-04 上传
2022-05-29 上传
2022-05-29 上传

张耘华
- 粉丝: 370
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
