基于RDMA的分布式图探索:加速并行SPARQL查询
116 浏览量
更新于2024-07-14
收藏 899KB PDF 举报
本文是一篇研究论文,标题为《基于RDMA的分布式图探索的快速和并行RDF查询》(Fast and Concurrent RDF Queries with RDMA-Based Distributed Graph Exploration),发表于2016年美国操作系统设计与实现第12届USENIX研讨会(OSDI'16)。会议于11月2日至4日在佐治亚州萨凡纳举行,论文的国际标准书号为978-1-931971-33-1。该论文探讨了在大规模RDF数据上进行高效、并发查询的问题,RDF(Resource Description Framework)是一种用于描述语义网数据的标准模型,而SPARQL(Simple Protocol and RDF Query Language)则是查询RDF图的语言。
在大数据时代,随着RDF知识库的规模不断扩大,处理海量的SPARQL查询变得至关重要。作者Jiaxin Shi、Youyang Yao、Rong Chen和Haibo Chen来自上海交通大学的并行与分布式系统研究所,Feifei Li则来自犹他大学的计算科学学院,他们共同提出了一个利用RDMA(Remote Direct Memory Access)技术进行分布式图探索的解决方案。RDMA允许直接从远程内存中读写数据,从而减少了网络通信开销,显著提升了查询性能。
论文的核心内容可能包括以下几个方面:
1. **RDMA技术的应用**:作者可能介绍了如何将RDMA技术融入RDF查询处理中,以实现数据在分布式环境中的高速传输和访问,减少中间环节,提高查询响应速度。
2. **分布式图探索算法**:论文可能会展示一种基于RDMA的高效算法,用于在分布式环境中并行探索RDF图,通过并行处理查询,以支持大规模并发查询。
3. **性能评估与优化**:通过实验和对比分析,论文可能会展示在实际场景中使用RDMA带来的性能提升,以及针对不同查询负载和硬件配置下的优化策略。
4. **系统架构与实现**:论文可能详细阐述了系统的整体设计,包括数据分布、通信协议、查询调度等关键组件,以及如何确保系统的可靠性和扩展性。
5. **未来展望**:最后,作者可能会讨论这项技术的潜在应用领域,以及可能面临的挑战和未来的研究方向。
这篇论文不仅关注了如何通过RDMA技术解决RDF查询的性能瓶颈问题,还展示了在分布式计算环境下实现高效的并发查询策略,对于理解现代大数据处理和知识图谱查询技术具有重要的参考价值。
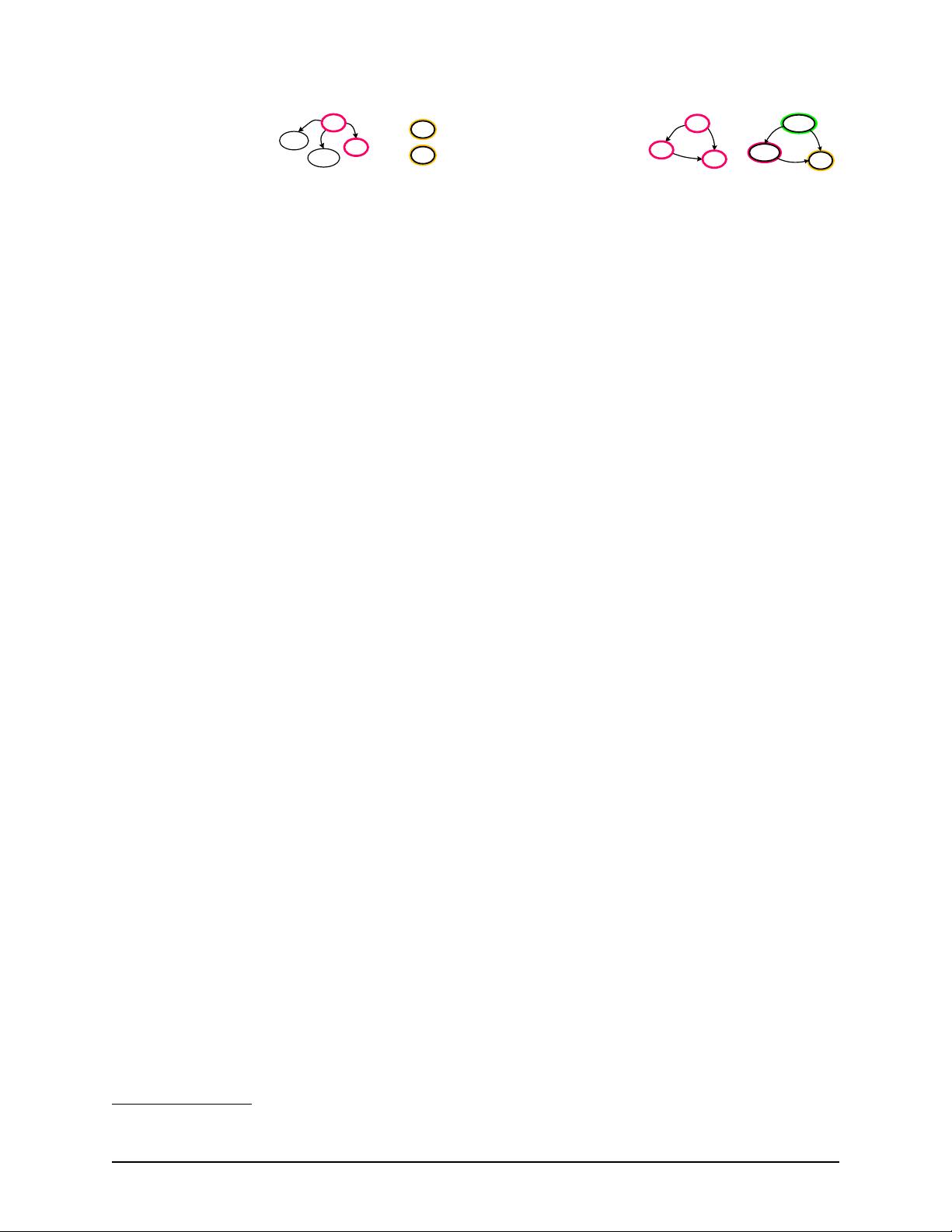
mo
to
SELECT ?Y WHERE {
?X memberOf X-Lab .
?X type Professor .
?X teacherOf ?Y .
}
X-Lab
Prof
?X
ty
?Y
OS
DS
SPARQL Graph Results
Fig. 2: A SPARQL query (Q
1
) on sample RDF graph.
For example, as shown in Figure
2, the query Q
1
re-
trieves all objects that were taught (to) by a Professor
who is a member (mo) of X-Lab. The query can also be
graphically represented by a query graph, in which ver-
tices represent the subjects and objects of the triple pat-
terns; the black vertices represent constants, a nd the red
vertices repres ent variables; The edges represent pred-
icates in the required patterns (GP). The query results
(?Y, described in RD) include DS and OS.
Difference from graph analytics. Readers might be
curious about the relationship between RDF queries and
graph analytics [
28, 18, 31, 19, 13, 41, 55, 56], especially
a recent design [
50] used one-sided RDMA to implement
message-passing primitives. However, there are several
fundamental differences between RDF queries and graph
analytics.
First, RDF queries are user-centric; thus minimizing
the roundtrip latency is more important than maximizing
network throughput. Second, RDF queries only touch a
small subset of a graph instead of processing the entire
graph, making it not worthwhile to dedicate all resources
to run a single query. Third, graph-analytics is usually
done in a batch-oriented manner in contrast to concur-
rently serving multiple RDF queries.
2.2 Existing Solutions
We then discuss two representative approaches adopted
in existing state-of-the-art RDF systems.
Triple store and triple join: A majority of existing
systems store and index RDF data as a set of triples in
relational databas e s, and excessively leverage triple join
operations to process SPARQL queries. Generally, query
processing consists of two phases: Scan and Join. In
the Scan phase, the R D F engine decompose s a SPARQL
query into a set of triple patterns. For the query in Fig-
ure
2, the triple patterns are {?X memberOf X-Lab}, {?X
type Professor} and {?X teacherOf ?Y}. For each triple
pattern, it generates a temporary query table with bind-
ings by scanning the triple store. In the Join phase, the
query tables are joined to produce the final query results.
Some prior work [
54] has summarized the inherent
limitations of triple-store based approach. First, triple
stores rely excessively on costly join operations, espe-
cially for distributed merge/hash-join. Second, the scan-
join approach may generate large redundant intermediate
results. Finally, while using redundant six primary SPO
4
4
S, P and O stand for subject, predicate and object accordingly.
SELECT ?X ?Y ?Z WHERE {
?X teacherOf ?Y .
?Z takesCourse ?Y .
?Z advisor ?X .
}
OS
tc
to
ad
Logan
Marie
ad
tc
?X
?Y
to
?Z
SPARQL Graph Results
Fig. 3: A SPARQL query (Q
2
) on sample RDF graph.
permutation indexes [
49] can accelerate scan operations,
such indexes lead to heavy memory pressure.
Graph store and graph exploration: Instead of join-
ing query tables, Trinity.RDF [
49] stores RDF data in a
native graph model on top of a distributed in-memory
key/value store, and leverages fast graph-exploration
strategy for query processing. It further adopts one-step
pruning (i.e., the constraint in the immediately prior step)
to reduce the intermediate results. As an example, con-
sidering Q
1
in Figure
2 over the data in Figure 1, after
exploring the type of Professor for each member of X-
Lab with respect to the data in Figure 1, we find that the
possible binding for ?X is only Erik and Logan, and the
rest of members are pruned.
However, the graph exploration in Trinity.RDF relies
on a final centralized join to filter out non-matching re-
sults. For example, the query Q
2
in Figure
3 asks for ad-
visors (?X), courses (?Y) and students (?Z) such that the
advisor advises (ad) the student who also takes a course
(tc) taught by (to) the advisor. After exploring all three
triple patterns in Q
2
with respect to the data in Figure
1,
the non-matching bindings, namely, Logan
−→
to OS, OS
←−
tc
Raven and Raven
−→
ad Erik will not be pruned until a final
join. Prior work [
21, 37] indicates that the final join is
a potential bottleneck, especially for queries with cycles
and/or large intermediate results.
2.3 RDMA and Its Characteristics
Remote Direct Memory Access (RDMA) is a cross-node
memory access technique with low-latency and low CPU
overhead, due to complete bypassing of target OS ker-
nel and/or CPU. RDMA provides both two-sided mes-
sage passing interfaces like SEND/RECV Verbs as well
as one-sided operations such as READ, WRITE and
two atomic operations (fetch-and-add and compare-and-
swap). As noted in prior work [
30, 16, 48], one-sided
operations are usually less disruptive than its two-sided
counterparts due to no CPU involvement to the target
machine. To minimize interference among multiple ma-
chines during query processing, we focus on one-sided
RDMA operations in this paper. However, it should be
straightforward to use two-sided RDMA operations in
Wukong as well.
Figure
4(a) shows the throughput (in Kbps ) of dif-
ferent communication primitives. RDMA undoubtedly
achieves the highest throughput for all payload sizes,
while the throughput of TCP/IP over IPoIB (IP over In-
finiBand) or 10GbE approaches that of one-sided RDMA
USENIX Association 12th USENIX Symposium on Operating Systems Design and Implementation 319
剩余16页未读,继续阅读
2021-08-08 上传
2021-08-08 上传
2023-07-21 上传
2023-06-15 上传
2023-07-25 上传
2023-08-31 上传
2023-06-11 上传
2023-05-31 上传
2023-11-09 上传

weixin_38728624
- 粉丝: 4
- 资源: 881
 我的内容管理
展开
我的内容管理
展开







最新资源
- IPQ4019 QSDK开源代码资源包发布
- 高频组电赛必备:掌握数字频率合成模块要点
- ThinkPHP开发的仿微博系统功能解析
- 掌握Objective-C并发编程:NSOperation与NSOperationQueue精讲
- Navicat160 Premium 安装教程与说明
- SpringBoot+Vue开发的休闲娱乐票务代理平台
- 数据库课程设计:实现与优化方法探讨
- 电赛高频模块攻略:掌握移相网络的关键技术
- PHP简易简历系统教程与源码分享
- Java聊天室程序设计:实现用户互动与服务器监控
- Bootstrap后台管理页面模板(纯前端实现)
- 校园订餐系统项目源码解析:深入Spring框架核心原理
- 探索Spring核心原理的JavaWeb校园管理系统源码
- ios苹果APP从开发到上架的完整流程指南
- 深入理解Spring核心原理与源码解析
- 掌握Python函数与模块使用技巧
