Lucene源码深度解析:全文检索原理与实现
需积分: 26 146 浏览量
更新于2024-07-26
收藏 4.73MB PDF 举报
"Lucene源码分析文档主要涵盖了全文检索的基本原理和Lucene框架的源码解析,适合初学者深入理解搜索引擎的工作机制。作者通过详细阐述Lucene的索引创建和搜索过程,帮助读者掌握Lucene的核心功能。"
在全文检索的基本原理部分,文档介绍了以下知识点:
1. **总论**:全文检索是一种能够在大量文本中快速查找包含特定词汇的文档的技术,Lucene是Java平台上最流行的全文检索库。
2. **索引内容**:索引主要存储词项(Term)及其在文档中的位置信息,用于加速搜索过程。
3. **创建索引**:
- **原始文档**(Document):包含要被索引的信息。
- **分词组件**(Tokenizer):将文档内容分割成可索引的词元。
- **语言处理组件**(LinguisticProcessor):处理词元,例如去除停用词,词形还原等。
- **索引组件**(Indexer):构建字典,合并相同的词项形成文档倒排链表(PostingList)。
4. **搜索索引**:
- **用户查询**:用户输入的查询语句。
- **词法分析**:识别单词和关键字。
- **语法分析**:构造查询语句的语法树。
- **语言处理**:处理查询中的语言特性。
- **搜索**:匹配语法树的文档,并根据相关性排序。
- **相关性计算**:包括Term权重计算和向量空间模型(VSM)。
在Lucene的总体架构部分,文档可能涉及以下内容:
1. Lucene的模块化设计,包括分析器(Analyzer)、索引器(IndexWriter)、搜索器(Searcher)等核心组件。
2. Lucene的索引结构,如倒排索引(Inverted Index)是如何支持高效的全文搜索。
在代码分析篇,文档可能会深入到Lucene的源码层面,讲解如下内容:
1. **索引文件格式**:包括Lucene如何存储和组织索引数据,如基本概念、类型和规则。
- **前缀后缀规则**:用于节省存储空间和加快读取速度。
- **差值规则**(Delta Encoding):优化数值编码,减少存储空间。
- **或然跟随规则**:可能涉及位图索引或稀疏数据表示。
通过这些分析,学习者可以逐步了解Lucene如何实现高效的全文检索,以及如何阅读和理解Lucene的源代码,为后续的开发工作打下坚实基础。

16
到相同的转换。
语言处理组件(linguistic processor)的结果称为词(Term)。
在我们的例子中,经过语言处理,得到的词(Term)如下:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,
“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
也正是因为有语言处理的步骤,才能使搜索 drove,而 drive 也能被搜索出来。
第四步
第四步第四步
第四步:
::
:将得到的词
将得到的词将得到的词
将得到的词(Term)传给索引组件
传给索引组件传给索引组件
传给索引组件(Indexer)。
。。
。
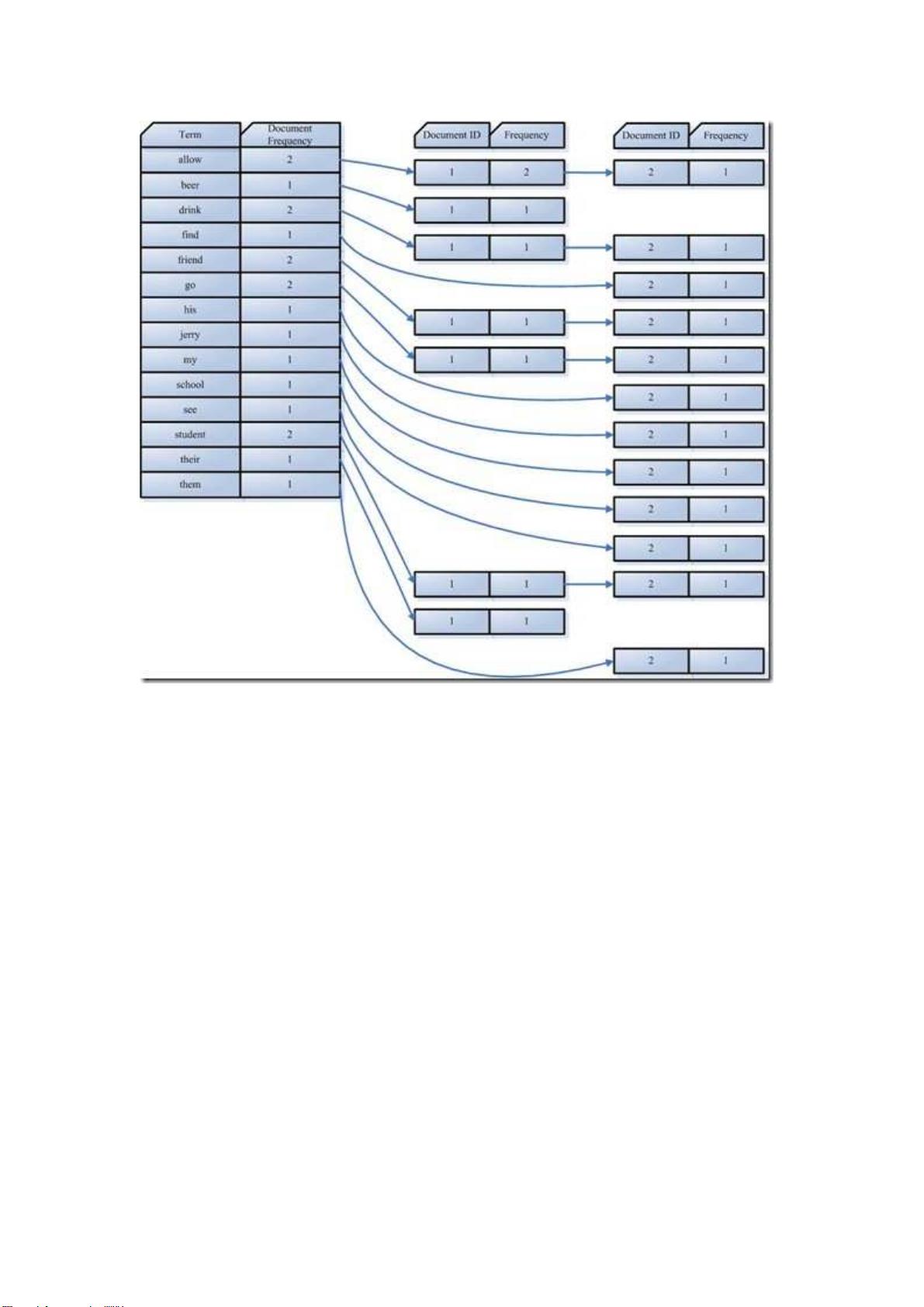
索引组件(Indexer)主要做以下几件事情:
1. 利用得到的词
利用得到的词利用得到的词
利用得到的词(Term)创建一个字典
创建一个字典创建一个字典
创建一个字典。
。。
。
在我们的例子中字典如下:
Term Document ID
student 1
allow 1
go 1
their 1
friend 1
allow 1
drink 1
beer 1
my 2
friend 2


剩余526页未读,继续阅读
2012-01-16 上传
2018-07-12 上传
2012-11-16 上传
2021-08-14 上传
2019-02-19 上传
2011-10-09 上传

joeywen
- 粉丝: 84
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
