深度学习里程碑:AlexNet与现代神经网络演进
需积分: 25 195 浏览量
更新于2024-07-19
收藏 2.69MB PDF 举报
"AlexNet深度学习综述"
深度学习作为一种革命性的机器学习技术,近年来在众多应用领域取得了显著的成功。自AlexNet在2012年ImageNet竞赛中取得突破性成果以来,它引领了深度学习的发展,尤其是卷积神经网络(CNN)的进步。本文将对AlexNet进行综述,并探讨其在深度学习方法上的历史演变。
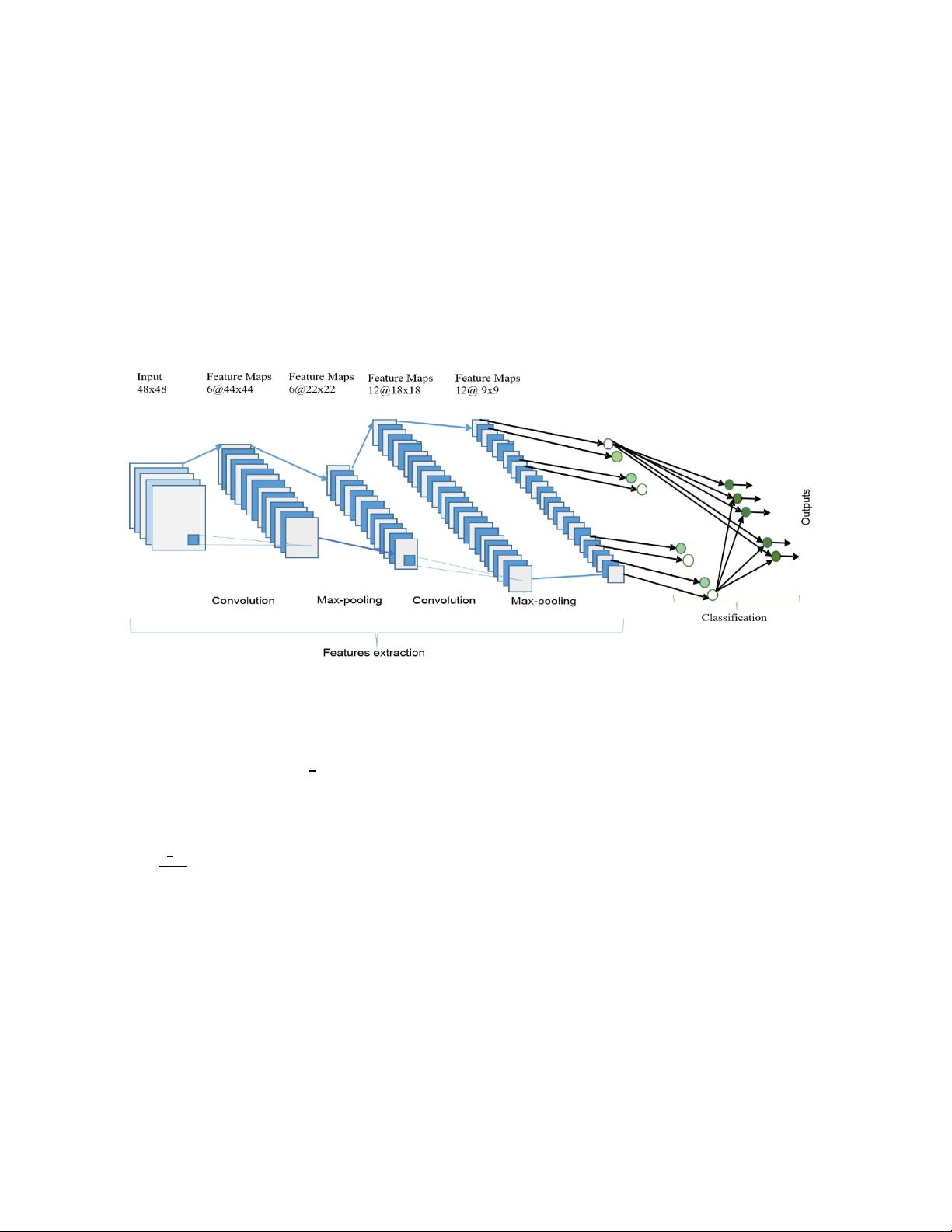
AlexNet是深度学习领域的里程碑,由Hinton团队提出,其主要创新在于深度架构和大规模数据的结合。AlexNet包含8个层次,其中5层是卷积层,3层是全连接层,以及两个最大池化层。通过并行GPU处理,AlexNet成功地减少了训练时间,提高了模型的准确性,打破了当时计算机视觉任务的记录。
深度学习的主要分支包括深度神经网络(DNN)、卷积神经网络(CNN)和循环神经网络(RNN)。DNN是多层的神经网络,允许非线性特征学习,而AlexNet正是DNN的一个实例。CNN在图像处理和计算机视觉领域尤为强大,因为它们能捕捉空间关系和局部特征。AlexNet利用卷积层提取图像特征,有效减少了参数数量,降低了过拟合风险。RNN则适用于序列数据,如语音识别和自然语言处理,因其具有记忆过去状态的能力。
深度学习方法在多个领域展现出优越性能,如图像处理、计算机视觉、语音识别、机器翻译、艺术、医疗成像、医学信息处理、机器人和控制、生物信息学、NLP、网络安全等。与传统机器学习方法相比,深度学习在解决复杂问题时往往表现出更高的准确性和泛化能力。
然而,深度学习也面临挑战,例如模型解释性差、训练数据需求量大、计算资源消耗高以及容易出现梯度消失或爆炸问题。为克服这些挑战,研究者们提出了各种优化策略,如正则化、批量归一化、残差连接和动态网络结构等。
总结来说,AlexNet开启了深度学习的新纪元,推动了CNN的发展,并影响了后续的深度学习架构,如VGGNet、GoogLeNet和ResNet等。随着硬件进步和算法优化,深度学习将继续在各个领域发挥关键作用,不断推动技术的边界。

> REPLACE THIS LINE WITH YOUR PAPER IDENTIFICATION NUMBER (DOUBLE-CLICK HERE TO EDIT) <
7
C. Stochastic Gradient Descent (SGD)
Since a long training time is the main drawback for the
traditional gradient descent approach, the SGD approach is used
for training Deep Neural Networks (DNN) [52]. Algorithm II
explains SGD in detail.
Algorithm II. Stochastic Gradient Descent (SGD)
Inputs: loss function , learning rate , dataset and the
model
Outputs: Optimum which minimizes
REPEAT until converge:
Shuffle
For each batch of
in do
End
D. Back-propagation
DNN are trained with the popular Back-Propagation (BP)
algorithm with SGD [53]. The pseudo code of basic Back-
propagation is given in Algorithm III. In case of MLP, we can
easily represent NN models using computation graphs which
are directive acyclic graphs. For that representation of DL, we
can use the chain-rule to efficiently calculate the gradient from
the top to the bottom layers with BP as shown in Algorithm III
for a single path network. For example:
(4)
This is composite function for layers of a network. In case
of , then the function can be written as
(5)
According to the chain rule, the derivative of this function can
be written as
(6)
E. Momentum
Momentum is a method which helps to accelerate the training
process with the SGD approach. The main idea behind it is to
use the moving average of the gradient instead of using only the
current real value of the gradient. We can express this with the
following equation mathematically:
(7)
(8)
Here γ is the momentum and is the learning rate for the t
th
round of training. Other popular approaches have been
introduced during last few years which are explained in section
4 under the scope of optimization approaches. The main
advantages of using momentum during training is to prevent the
network from getting stuck in local minimum. The values of
momentum are γ (0,1]. It is noted that a higher momentum
value overshoots its minimum, possibly making the network
unstable. In generally γ is set to 0.5 until the initial learning
stabilizes and is then increased to 0.9 or higher [54].
Algorithm III. Back-propagation
Input: A network with layers, the activation function
,
the outputs of hidden layer
and the
network output
Compute the gradient:
For to do
Calculate gradient for present layer:
Apply gradient descent using
and
Back-propagate gradient to the lower layer
End
F. Learning rate
The learning rate is an important component for training DNN
(as explained in Algorithm I and II). The learning rate is the step
size considered during training which makes the training
process faster. However, selecting the value of the learning rate
is sensitive. For example: if you choose a larger value for ,
the network may start diverging instead of converging. On the
other hand, if you choose a smaller value for , it will take more
time for the network to converge. In addition, it may be easily
stuck in a local minima. The typical solution for this problem is
to reduce the learning rate during training [52].
There are three common approaches used for reducing the
learning rate during training: constant, factored, and
exponential decay. First, we can define a constant which is
applied to reduce the learning rate manually with a defined step
function. Second, the learning rate can be adjusted during
training with the following equation:
(9)
Where
is the t
th
round learning rate,
is the initial learning
rate, and is the decay factor with a value between the range
of
.
剩余38页未读,继续阅读
1065 浏览量
297 浏览量
107 浏览量
2021-09-01 上传
2023-09-19 上传
2021-08-19 上传
301 浏览量
170 浏览量
795 浏览量

qgywzz2
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Saber仿真下的简化Buck环路分析与TDsa扫频
- Spring框架下使用FreeMarker发邮件实例解析
- Cocos2d捕鱼达人路线编辑器开发指南
- 深入解析CSS Flex布局与特性的应用
- 小学生加减法题库自动生成软件介绍
- JS颜色选择器示例:跨浏览器兼容性
- ios-fingerprinter:自动化匹配iOS配置文件与.p12证书
- 掌握移动Web前端高效开发技术要点
- 解决VS中OpenGL程序缺失GL/glut.h文件问题
- 快速掌握POI技术,轻松编辑Excel文件
- 实用ASCII码转换工具:轻松实现数制转换与查询
- Oracle ODBC补丁解决数据源配置问题
- C#集成连接器的开发与应用
- 电子书制作教程:你的文档整理助手
- OpenStack计费监控:使用collectd插件收集统计信息
- 深入理解SQL Server 2008 Reporting Services
